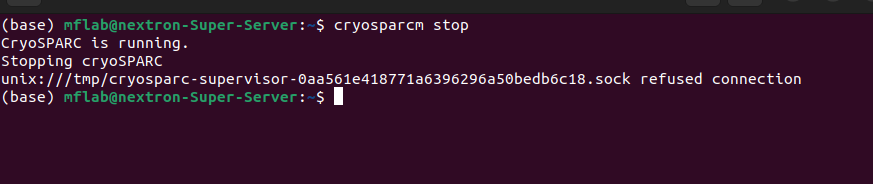
It’s a similar problem that others have had, and before the solutions from those discussions (posted below) have fixed the problem. Usually deleting the .sock file works and then Cryosparc runs fine. The issue now is that it only last for a 1-2 hours and then the same thing happens again.
Any ides or tips how to fix this?
It’s a single workstation. Recently upgraded to 4.1.2.
Welcome to the forum @svalen.
Please can you paste your terminal output as text.
Before deleting the sock file, one should always confirm that no processes related to the given CryoSPARC instance are running, keeping in mind that a computer can run multiple CryoSPARC instances (if certain requirements are met). For this purpose: under the Linux account that runs CryoSPARC processes, run cryosparcm stop ps xww | grep -e cryosparc -e mongo
and kill (notkill -9) processes related to the given CryoSPARC instance, but not processes related to other CryoSPARC instances that may also be running on the computer.
For confirmation that no more relevant processes are running, again: ps xww | grep -e cryosparc -e mongo
Only then should sock files belonging to the given CryoSPARC instance be removed.
Does this help?
Hello, and thank you for helping.
I’ve posted the text below after following your instructions. I can’t see any processes I can kill (right?) or am I doing something wrong?
Hi, again
I’ve noticed that it seems to happen when I’m running two NU-refinements at the same time. This has not been a problem before, and I usually run two jobs in parallel. At the moment, running jobs one at a time works but it’s of course slower and not ideal.
I’ve pasted the output below. (Sorry, I’m a bit inexperienced so not sure I did this properly)
(base) mflab@nextron-Super-Server:~$ eval $(/media/datastore/cryosparc/cryosparc_worker/bin/cryosparcw env)
env | grep PATH
which nvcc
nvcc --version
python -c "import pycuda.driver; print(pycuda.driver.get_version())"
uname -a
free -g
nvidia-smi
CRYOSPARC_PATH=/media/datastore/cryosparc/cryosparc_worker/bin
WINDOWPATH=2
PYTHONPATH=/media/datastore/cryosparc/cryosparc_worker
CRYOSPARC_CUDA_PATH=/usr/local/cuda
LD_LIBRARY_PATH=/usr/local/cuda/lib64:/media/datastore/cryosparc/cryosparc_worker/deps/external/cudnn/lib
PATH=/usr/local/cuda/bin:/media/datastore/cryosparc/cryosparc_worker/bin:/media/datastore/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/bin:/media/datastore/cryosparc/cryosparc_worker/deps/anaconda/condabin:/media/datastore/cryosparc/cryosparc_master/bin:/home/mflab/miniconda3/bin:/home/mflab/miniconda3/condabin:/home/mflab/.local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/snap/bin
/usr/local/cuda/bin/nvcc
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Jun__8_16:49:14_PDT_2022
Cuda compilation tools, release 11.7, V11.7.99
Build cuda_11.7.r11.7/compiler.31442593_0
(11, 7, 0)
Linux nextron-Super-Server 5.15.0-58-generic #64-Ubuntu SMP Thu Jan 5 11:43:13 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
total used free shared buff/cache available
Mem: 125 11 91 0 21 111
Swap: 1 0 1
Fri Feb 10 09:26:42 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.65.01 Driver Version: 515.65.01 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA RTX A5000 On | 00000000:01:00.0 On | Off |
| 30% 34C P8 22W / 230W | 468MiB / 24564MiB | 6% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA RTX A5000 On | 00000000:02:00.0 Off | Off |
| 30% 31C P8 13W / 230W | 6MiB / 24564MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 2128 G /usr/lib/xorg/Xorg 210MiB |
| 0 N/A N/A 2261 G /usr/bin/gnome-shell 78MiB |
| 0 N/A N/A 10360 G ...7/usr/lib/firefox/firefox 151MiB |
| 0 N/A N/A 13376 G ...mviewer/tv_bin/TeamViewer 23MiB |
| 1 N/A N/A 2128 G /usr/lib/xorg/Xorg 4MiB |
+-----------------------------------------------------------------------------+
(base) mflab@nextron-Super-Server:~$
I was able to run a Patch motion correction job with both GPUs without a problem, but if I run two different NU-refinement jobs simultaneously, it disconnects.
For an NU-refinement job that completed, but would have failed if it had been run concurrently with another job, what is the output of the following command (run inside the icli, with the actual project and job identifiers):
project, job = 'P147', 'J96'
max([e.get('cpumem_mb', 0) for e in db.events.find({'project_uid':project, 'job_uid':job})])
(base) mflab@nextron-Super-Server:~$ cryosparcm icli
Python 3.8.15 | packaged by conda-forge | (default, Nov 22 2022, 08:49:35)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.33.0 -- An enhanced Interactive Python. Type '?' for help.
connecting to nextron-Super-Server:39002 ...
cli, rtp, db, gfs and tools ready to use
In [1]: project, job = 'P8', 'J101'
...: max([e.get('cpumem_mb', 0) for e in db.events.find({'project_uid':projec
...: t, 'job_uid':job})])
Out[1]: 42558.15625
Non-uniform refinement jobs use a lot of system RAM. Two concurrent, memory-intensive jobs could cause available system RAM to be exhausted and overall system performance to deteriorate.
Sorry, but I accidentally removed the sock file while the cryosparc is running. Then the cryosparc can not restart as this issue Error starting cryosparc: "Could not get database status" - #9 by wtempel say. How can I solve this problem. I am really regreting for not stopping cryosparc first. Thank you very much!!
Hi,
Did anybody happen to come up with a fix for this? We are having the same issue, where the cryosparc page buffers, and “cryosparcm status” command gives us a ‘… .sock refused connection’. There are no running processes when we check, and removing the sock file allows us to restart cryosparc and continue submitting jobs… had this issue with both patch motion correction and blob picker. Our workstation has 4 RTX 2080 Ti GPUs, could it be a memory issue?
Thanks!
Update: I have been using a script to clear the cache every hour and it seems to have gotten around the " … .sock refused connection" issue. However I am still having issues, now during during 2D-classification:
`Traceback (most recent call last):
File “/home/bell/programs/cryosparc_worker/cryosparc_compute/jobs/runcommon.py”, line 2192, in run_with_except_hook
run_old(*args, **kw)
File “cryosparc_master/cryosparc_compute/gpu/gpucore.py”, line 134, in cryosparc_master.cryosparc_compute.gpu.gpucore.GPUThread.run
File “cryosparc_master/cryosparc_compute/gpu/gpucore.py”, line 135, in cryosparc_master.cryosparc_compute.gpu.gpucore.GPUThread.run
File “cryosparc_master/cryosparc_compute/jobs/class2D/newrun.py”, line 632, in cryosparc_master.cryosparc_compute.jobs.class2D.newrun.class2D_engine_run.work
File “cryosparc_master/cryosparc_compute/engine/newengine.py”, line 1619, in cryosparc_master.cryosparc_compute.engine.newengine.EngineThread.find_best_pose_shift_class
File “<array_function internals>”, line 5, in unravel_index
ValueError: index -1089082060 is out of bounds for array with size 336
We have ran the same 2D class job parameters (not cloned) and get this error at different points during iterations.
Along with that error, we also get an unresponsive heartbeat termination for some of the same 2D class jobs as well. Any advice would be greatly appreciated.
You may want to exit the shell after having recorded the commands’ outputs to avoid inadvertently running general commands inside the CryoSPARC environment.
bell@ub22-04:~$ cat /sys/kernel/mm/transparent_hugepage/enabled
always [madvise] never
bell@ub22-04:~$ sudo dmesg -T | grep -i error
(no output)
bell@ub22-04:~$ eval $(cryosparcm env)
(no output)
bell@ub22-04:~$ host $CRYOSPARC_MASTER_HOSTNAME
ub22-04 has address 10.69.108.35
bell@ub22-04:~$ time curl ${CRYOSPARC_MASTER_HOSTNAME}:
$CRYOSPARC_COMMAND_CORE_PORT
Hello World from cryosparc command core.
real 0m0.023s
user 0m0.005s
sys 0m0.005s
not sure if this is the correct way to do so, but the command I’ve been clearing the cache with: sync; echo 1 > /proc/sys/vm/drop_caches
I did run a check particles job (with NaN option) on the same particle stack and no corruption was detected. We have been turning off SSD caching as well for every job applicable.
If it helps, 2D classification will run fine with a fraction of the particles (about 1 million), but the full dataset (about 13 million) results in the issues aforementioned.
Interesting. I wonder if each 1M or so partition of the 13M set would succeed individually, or if there were at least one partition that would also fail. Have you tried that?