Thanks for all this feedback @olibclarke! Responses below:
Does this mean that the output volumes are not reflective of a reconstruction of the particle set assigned to each class, or am I misunderstading?
Yep, that is correct.
If this is the case, would it be possible to add an option to calculate a naive reconstruction of each class in the final step, without considering the contribution of every particle in every other class?
Thanks for this suggestion! We discussed it internally and came up with the idea to create a new ‘multi-class’ reconstruct-only job for any ‘all_particles’-type outputs that include class assignments. This should be in a release soon!
Also out of curiosity, does heterogeneous refinement use weighted back projection too? Or is this a new thing in 3D classification (beta)?
Heterogeneous refinement does indeed use weighted backprojection – the job I mentioned above will be useful to get single-class reconstructions from hetero_refine as well.
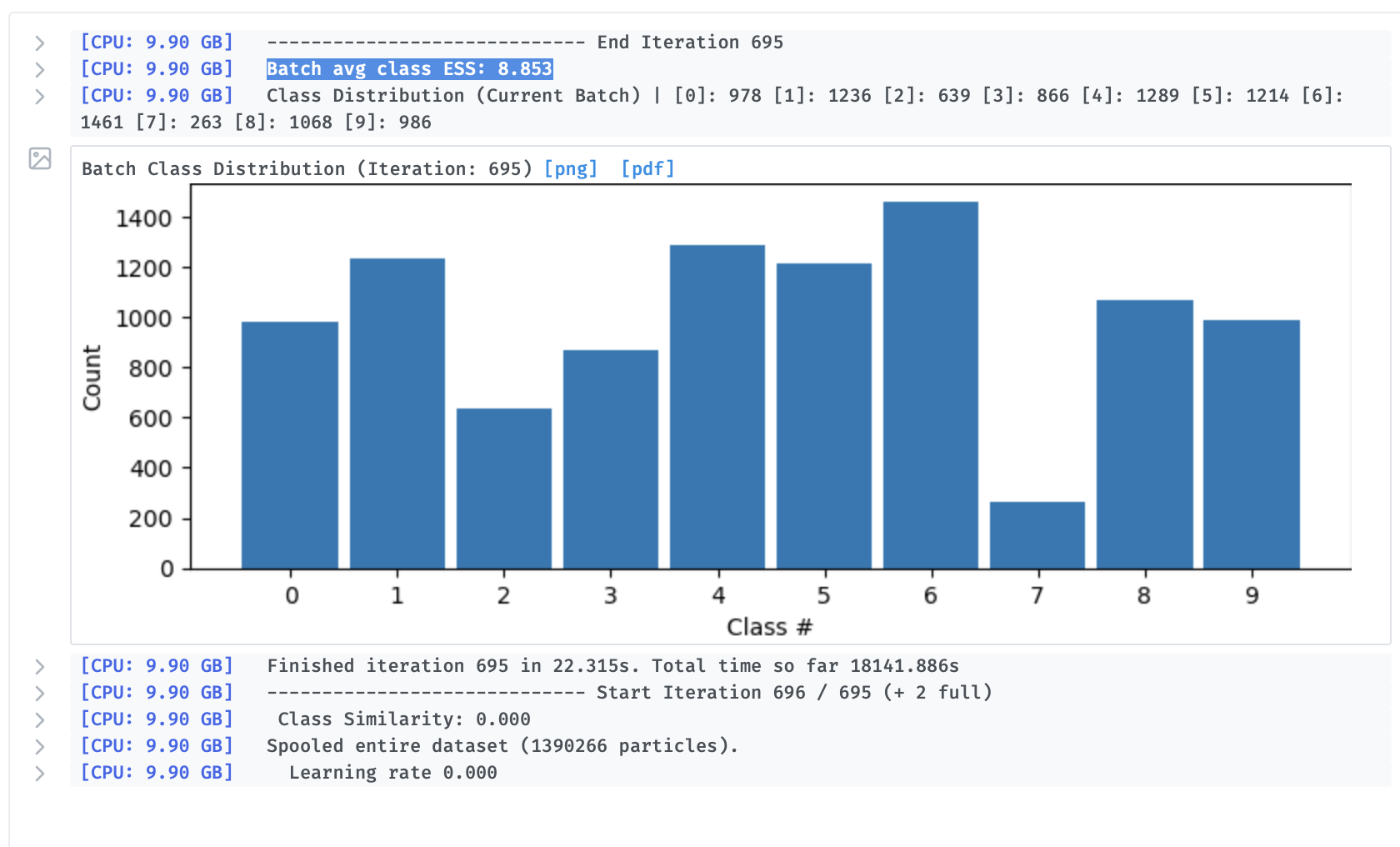
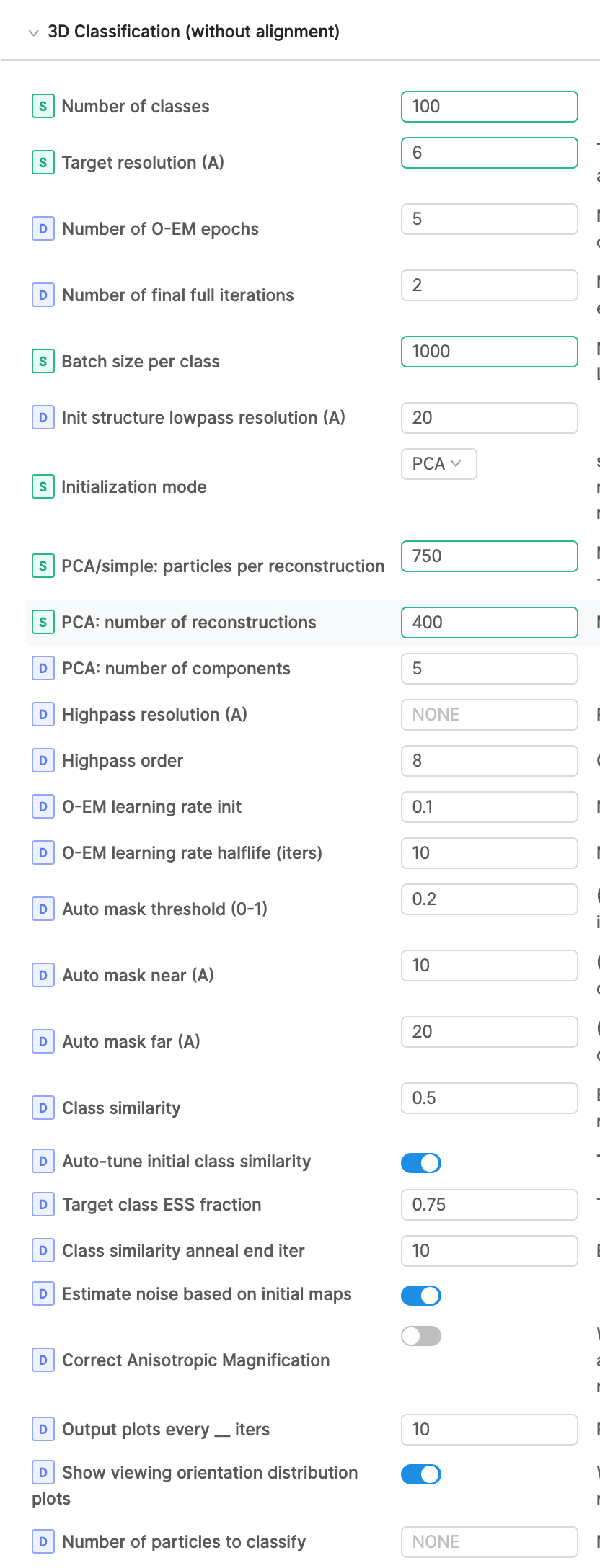
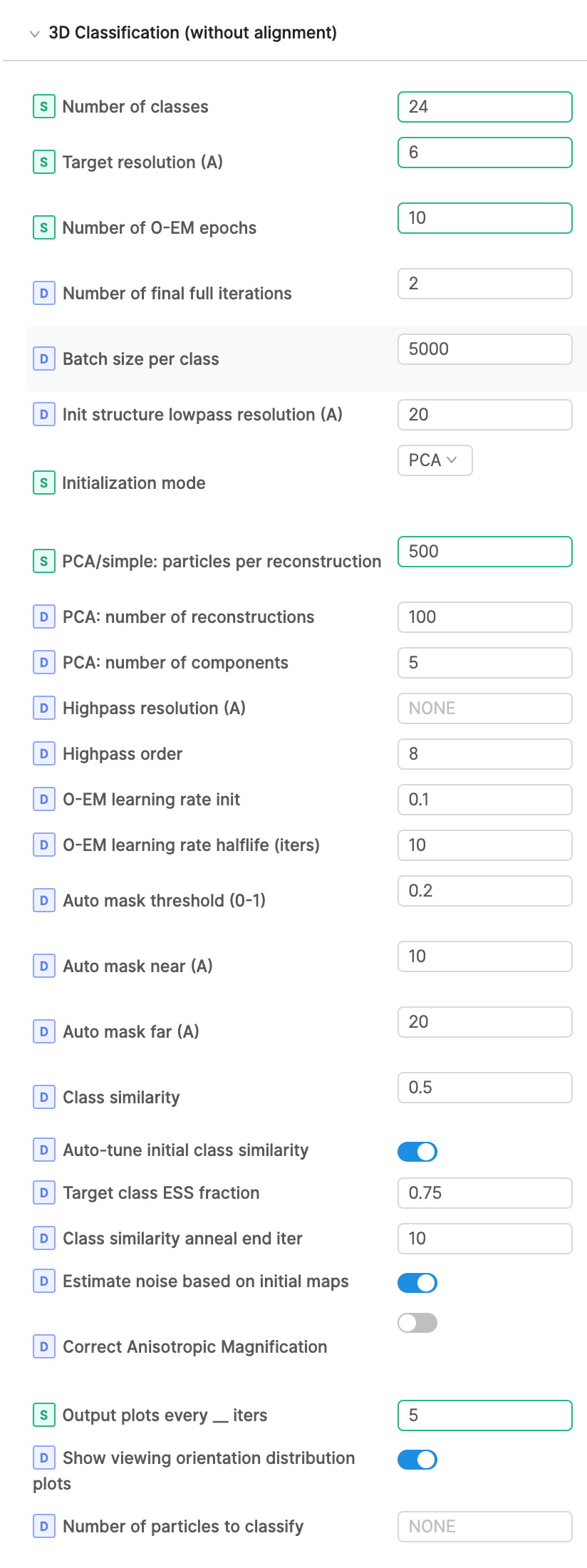
Also - Target class ESS fraction - just to understand, is this effectively setting a convergence criterion? So by default, the number of iterations will be set such that the mean ESS is ~75% of the number of classes?
This does not set a convergence criteria but (optionally) allows the job to tune the initial class similarity (which in turn adjusts the initial class distribution). When the class similarity (‘Beta’) is 0, the class assignments are defined by the standard maximum likelihood optimization. To ensure that the initial volumes don’t inadvertently skew the initial class assignments such that most particles belong to only a few classes, we define this constant, ‘Beta’, which we increase until the probability mass is diffused enough such that the empirical class ESS is at least the target class ESS (and hence each particle has a non-negligible probability of coming from any of the classes). Beta is then annealed down to 0 throughout the classification to ensure the final class assignments are indeed the maximum likelihood classes under the resulting volumes.
But then later in the docs it states that the classification is converged when this value reaches 1, and in my hands it seems to be still 9+ at the end of classification… am I doing something wrong? Or does this just mean that the nominal number of classes is likely greater than the actual number of classes in the data?
Is this consistent across different hyper-parameters? Have you tried increasing the number of epochs or changing the batch size per iteration? Does the class histogram change much in the last few iterations? This could mean that there are 9+ very similar classes that are difficult to differentiate between, but this seems unlikely since you are seeing appropriate heterogeneity when you reconstruct the single-class particle sets. Thus there is probably a single mode among these 9+ classes that is indeed the correct class. Perhaps this is a sign that the algorithm simply has not converged, but it’s tough to say.
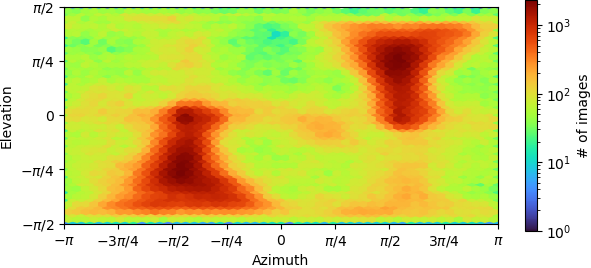
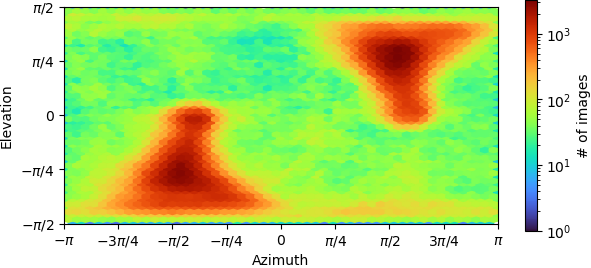
Is there any way to see the per class ESS values? It seems like if I am understanding correctly that this would be helpful to get a sense of variability - if one class has a low ESS, and the others have high ESS, does this mean that the low-ESS class is distinct, i.e. the particles in it do not have significant probabilities of assignment to other classes?
Ah yep, that is indeed what this would mean and we do actually report this in the heterogeneous refinement job! In the next release, I can add this to the 3D Classification to go along with the Class Distribution histogram (which should be similar to per class ESS if most particles have a class ESS of 1).