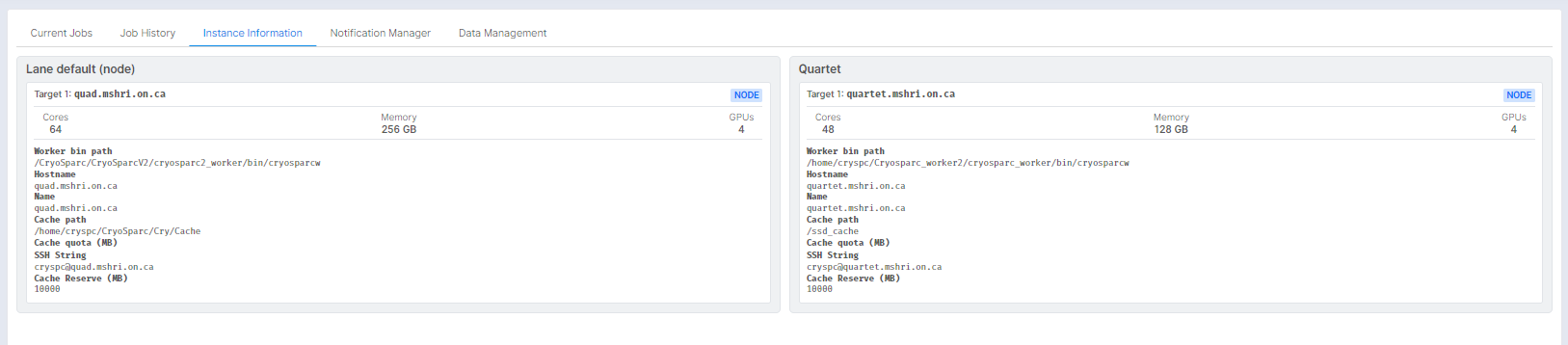
Hi!
I have the same issue which I’ve reported here:
https://discuss.cryosparc.com/t/launched-state-on-jobs-that-require-gpus/7480
In my case, the output of the cryosparcm log command_core looks like this:
---------- Scheduler running ---------------
Jobs Queued: [(‘P1’, ‘J25’)]
Licenses currently active : 2
Now trying to schedule J25
Need slots : {‘CPU’: 12, ‘GPU’: 2, ‘RAM’: 4}
Need fixed : {‘SSD’: False}
Master direct : False
Queue status : waiting_resources
Queue message : GPU not available
I see that there is a Queue message that GPU not available, but worker node sees GPUs as follows:
Detected 2 CUDA devices.
id pci-bus name
0 0000:01:00.0 NVIDIA GeForce RTX 3090
1 0000:21:00.0 NVIDIA GeForce RTX 3090
What is more, when I start jobs that do not require GPUs from the master node, all jobs complete. What is strange, when I try to run same jobs from the worker node (via CLI), then I have things like that:
================= CRYOSPARCW ======= 2021-10-22 14:22:52.780766 =========
Project P1 Job J34
Master michal-all-series Port 31002
===========================================================================
========= monitor process now starting main process
MAINPROCESS PID 9096
MAIN PID 9096
imports.run cryosparc_compute.jobs.jobregister
========= monitor process now waiting for main process
***************************************************************
**** handle exception rc
set status to failed
Traceback (most recent call last):
File "cryosparc_worker/cryosparc_compute/run.py", line 84, in cryosparc_compute.run.main
File "/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/jobs/imports/run.py", line 585, in run_import_movies_or_micrographs
assert len(all_abs_paths) > 0, "No files match!"
AssertionError: No files match!
========= main process now complete.
========= monitor process now complete.
As I’ve mentioned, I am not able to run jobs from the master node on the worker node when GPU is required. When I try to run jobs from CLI on the worker node, then I’ve got errors like that:
================= CRYOSPARCW ======= 2021-10-22 14:23:46.991599 =========
Project P1 Job J31
Master michal-all-series Port 31002
===========================================================================
========= monitor process now starting main process
MAINPROCESS PID 9152
MAIN PID 9152
motioncorrection.run_patch cryosparc_compute.jobs.jobregister
========= monitor process now waiting for main process
***************************************************************
Running job on hostname %s 153.19.19.156
Allocated Resources : {'fixed': {'SSD': False}, 'hostname': '153.19.19.156', 'lane': 'lane_3', 'lane_type': 'lane_3', 'license': True, 'licenses_acquired': 1, 'slots': {'CPU': [12, 13, 14, 15, 16, 17], 'GPU': [1], 'RAM': [4, 5]}, 'target': {'cache_path': None, 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'desc': None, 'gpus': [{'id': 0, 'mem': 25438715904, 'name': 'NVIDIA GeForce RTX 3090'}, {'id': 1, 'mem': 25447170048, 'name': 'NVIDIA GeForce RTX 3090'}], 'hostname': '153.19.19.156', 'lane': 'lane_3', 'monitor_port': None, 'name': '153.19.19.156', 'resource_fixed': {'SSD': False}, 'resource_slots': {'CPU': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63], 'GPU': [0, 1], 'RAM': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31]}, 'ssh_str': 'michal@153.19.19.156', 'title': 'Worker node 153.19.19.156', 'type': 'node', 'worker_bin_path': '/home/michal/Apps/cryosparc/cryosparc_worker/bin/cryosparcw'}}
WARNING: Treating empty result movies.0.movie_blob as an empty dataset! You probably forgot to output something in a connected job!
WARNING: Treating empty result movies.0.gain_ref_blob as an empty dataset! You probably forgot to output something in a connected job!
WARNING: Treating empty result movies.0.mscope_params as an empty dataset! You probably forgot to output something in a connected job!
**** handle exception rc
set status to failed
Traceback (most recent call last):
File "cryosparc_worker/cryosparc_compute/run.py", line 84, in cryosparc_compute.run.main
File "cryosparc_worker/cryosparc_compute/jobs/motioncorrection/run_patch.py", line 44, in cryosparc_compute.jobs.motioncorrection.run_patch.run_patch_motion_correction_multi
AttributeError: 'NoneType' object has no attribute 'add_fields'
========= main process now complete.
========= monitor process now complete.
Do you have any ideas how to solve that?
Best regards,
Marcel