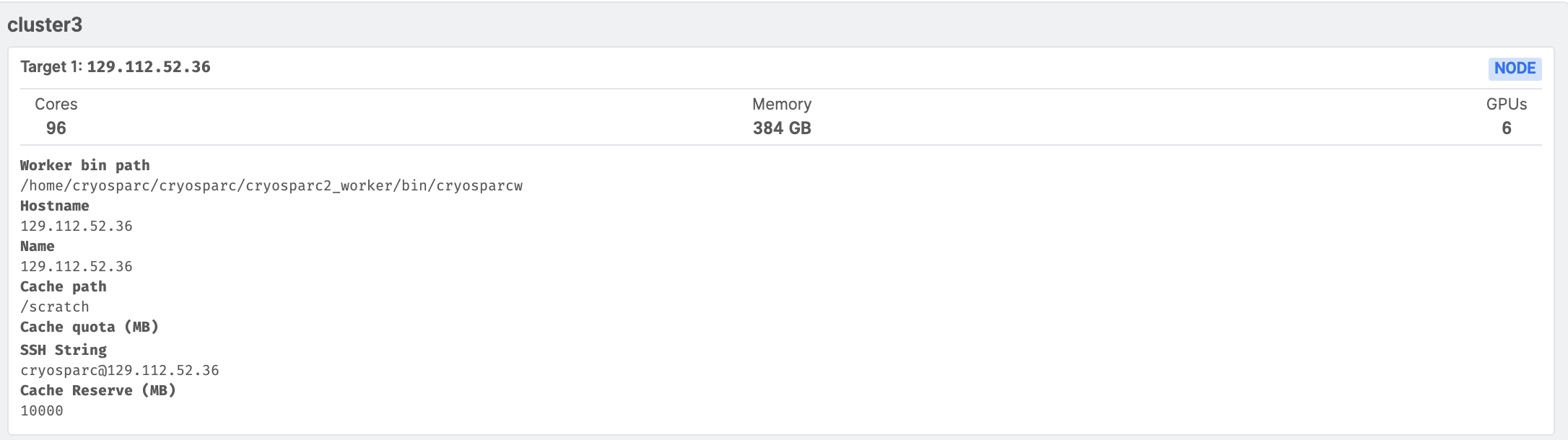
@nfrasser
Here is the full output.
It looks like fail to connect to the worker?
"---------- Scheduler finished ---------------
Failed to connect link: HTTP Error 502: Bad Gateway"
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
[EXPORT_JOB] : Request to export P35 J10
[EXPORT_JOB] : Exporting job to /run/media/xiaochun/Data63/111320_HW267/P35/J10
[EXPORT_JOB] : Exporting all of job's images in the database to /run/media/xiaochun/Data63/111320_HW267/P35/J10/gridfs_data...
[EXPORT_JOB] : Done. Exported 0 images in 0.00s
[EXPORT_JOB] : Exporting all job's streamlog events...
[EXPORT_JOB] : Done. Exported 1 files in 0.00s
[EXPORT_JOB] : Exporting job metafile...
[EXPORT_JOB] : Done. Exported in 0.00s
[EXPORT_JOB] : Updating job manifest...
[EXPORT_JOB] : Done. Updated in 0.00s
[EXPORT_JOB] : Exported P35 J10 in 0.01s
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
[EXPORT_JOB] : Request to export P35 J2
[EXPORT_JOB] : Exporting job to /run/media/xiaochun/Data63/111320_HW267/P35/J2
[EXPORT_JOB] : Exporting all of job's images in the database to /run/media/xiaochun/Data63/111320_HW267/P35/J2/gridfs_data...
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85'), (u'P35', u'J10')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
Licenses currently active : 0
Now trying to schedule J10
Need slots : {u'GPU': 1, u'RAM': 3, u'CPU': 2}
Need fixed : {u'SSD': True}
Master direct : False
Scheduling job to c07095.dhcp.swmed.org
Not a commercial instance - heartbeat set to 12 hours.
Launchable! -- Launching.
Changed job P35.J10 status launched
Running project UID P35 job UID J10
Running job on worker type node
Running job using: /home/cryosparc/cryosparc/cryosparc2_worker/bin/cryosparcw
Running job on remote worker node hostname c07095.dhcp.swmed.org
cmd: bash -c "nohup /home/cryosparc/cryosparc/cryosparc2_worker/bin/cryosparcw run --project P35 --job J10 --master_hostname c105053.dhcp.swmed.org --master_command_core_port 39002 > /run/media/xiaochun/Data63/111320_HW267/P35/J10/job.log 2>&1 & "
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 1
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
Failed to connect link: HTTP Error 502: Bad Gateway
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 1
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---- Killing project UID P35 job UID J10
Killing job on worker type node c07095.dhcp.swmed.org
Killing job on another worker node hostname c07095.dhcp.swmed.org
Changed job P35.J10 status killed
[EXPORT_JOB] : Request to export P35 J10
[EXPORT_JOB] : Exporting job to /run/media/xiaochun/Data63/111320_HW267/P35/J10
[EXPORT_JOB] : Exporting all of job's images in the database to /run/media/xiaochun/Data63/111320_HW267/P35/J10/gridfs_data...
[EXPORT_JOB] : Done. Exported 0 images in 0.00s
[EXPORT_JOB] : Exporting all job's streamlog events...
[EXPORT_JOB] : Done. Exported 1 files in 0.00s
[EXPORT_JOB] : Exporting job metafile...
[EXPORT_JOB] : Done. Exported in 0.01s
[EXPORT_JOB] : Updating job manifest...
[EXPORT_JOB] : Done. Updated in 0.00s
[EXPORT_JOB] : Exported P35 J10 in 0.01s
[EXPORT_JOB] : Request to export P35 J10
[EXPORT_JOB] : Exporting job to /run/media/xiaochun/Data63/111320_HW267/P35/J10
[EXPORT_JOB] : Exporting all of job's images in the database to /run/media/xiaochun/Data63/111320_HW267/P35/J10/gridfs_data...
[EXPORT_JOB] : Done. Exported 0 images in 0.00s
[EXPORT_JOB] : Exporting all job's streamlog events...
[EXPORT_JOB] : Done. Exported 1 files in 0.00s
[EXPORT_JOB] : Exporting job metafile...
[EXPORT_JOB] : Done. Exported in 0.00s
[EXPORT_JOB] : Updating job manifest...
[EXPORT_JOB] : Done. Updated in 0.00s
[EXPORT_JOB] : Exported P35 J10 in 0.01s
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85'), (u'P35', u'J10')]
Licenses currently active : 0
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
Licenses currently active : 0
Now trying to schedule J10
Need slots : {u'GPU': 1, u'RAM': 3, u'CPU': 2}
Need fixed : {u'SSD': True}
Master direct : False
Scheduling job to c07095.dhcp.swmed.org
Failed to connect link: HTTP Error 502: Bad Gateway
Not a commercial instance - heartbeat set to 12 hours.
Launchable! -- Launching.
Changed job P35.J10 status launched
Running project UID P35 job UID J10
Running job on worker type node
Running job using: /home/cryosparc/cryosparc/cryosparc2_worker/bin/cryosparcw
Running job on remote worker node hostname c07095.dhcp.swmed.org
cmd: bash -c "nohup /home/cryosparc/cryosparc/cryosparc2_worker/bin/cryosparcw run --project P35 --job J10 --master_hostname c105053.dhcp.swmed.org --master_command_core_port 39002 > /run/media/xiaochun/Data63/111320_HW267/P35/J10/job.log 2>&1 & "
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 1
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 1
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 1
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 1
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------
---------- Scheduler running ---------------
Jobs Queued: [(u'P27', u'J85')]
Licenses currently active : 1
Now trying to schedule J85
Need slots : {u'GPU': 1, u'RAM': 2, u'CPU': 4}
Need fixed : {u'SSD': True}
Master direct : False
Queue status :
Queue message :
---------- Scheduler finished ---------------