Hello,
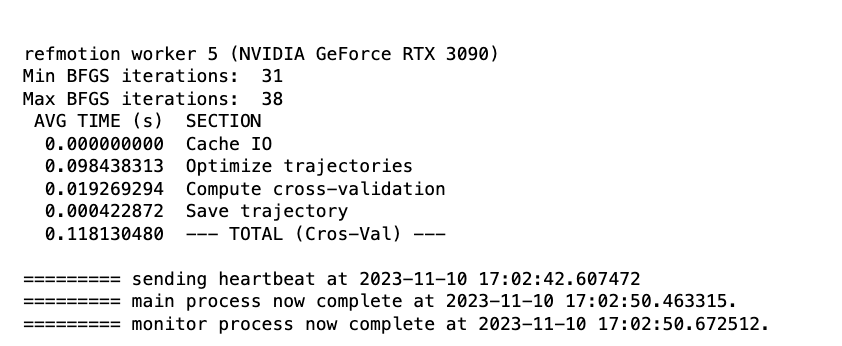
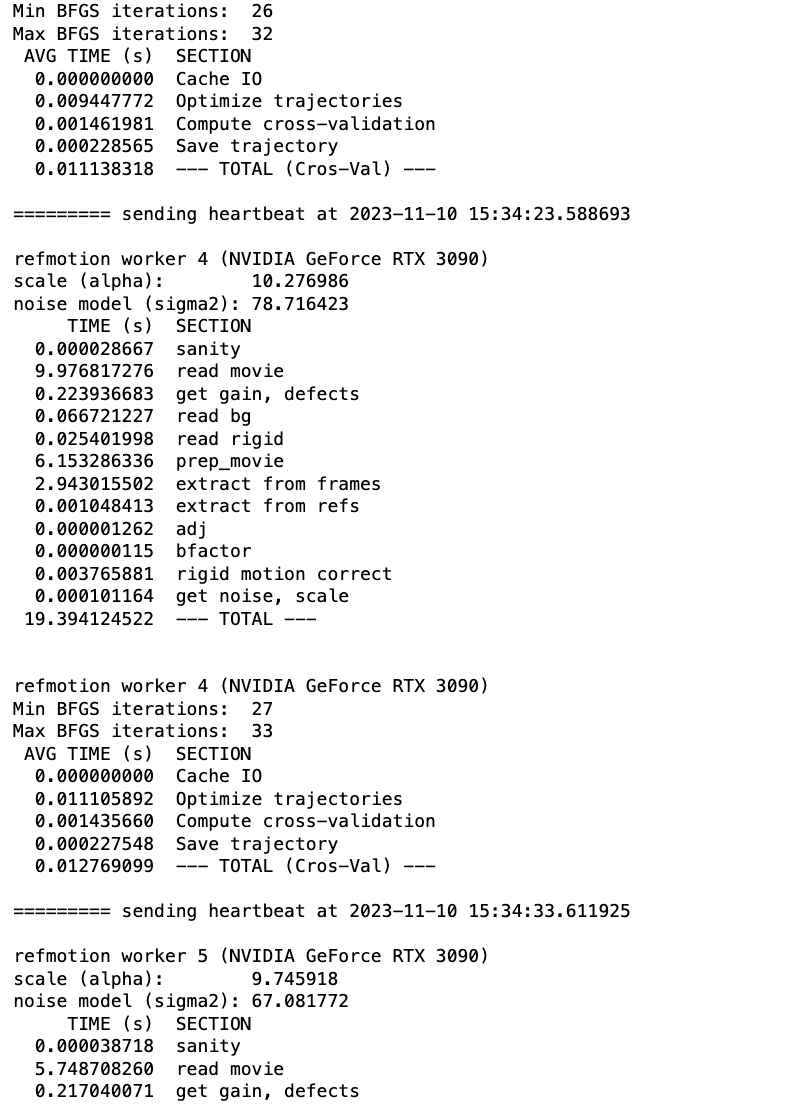
Could anyone help me figure out why my reference based motion correction is giving me this error? I’ve attached a screen shot that shows the error and when it occurs. Interestingly, the point at which it terminates is seemingly random during cross validation - perhaps some images are holding it up that didn’t hold up motion correction or CTF in cryosparc live?
All of my data are processed within cryosparc, I used cryosparc live for motion correction and CTF before exporting - I’ve picked particles and gone through multiple round of 3D classification/refinements, and have obtained nice high resolution structures (2.4A at best).
I have attempted two data sets, one where I have extracted particles, sorted particles (classification) and refined structures in C1, it has a large box size of 720 (1.048A/Pix).
A more complicated model I was trying, is where my particles were refined in C2, symmetry expanded, then re-extracted on one end of the molecule and reprocessed through classification, particle subtraction and refinements.
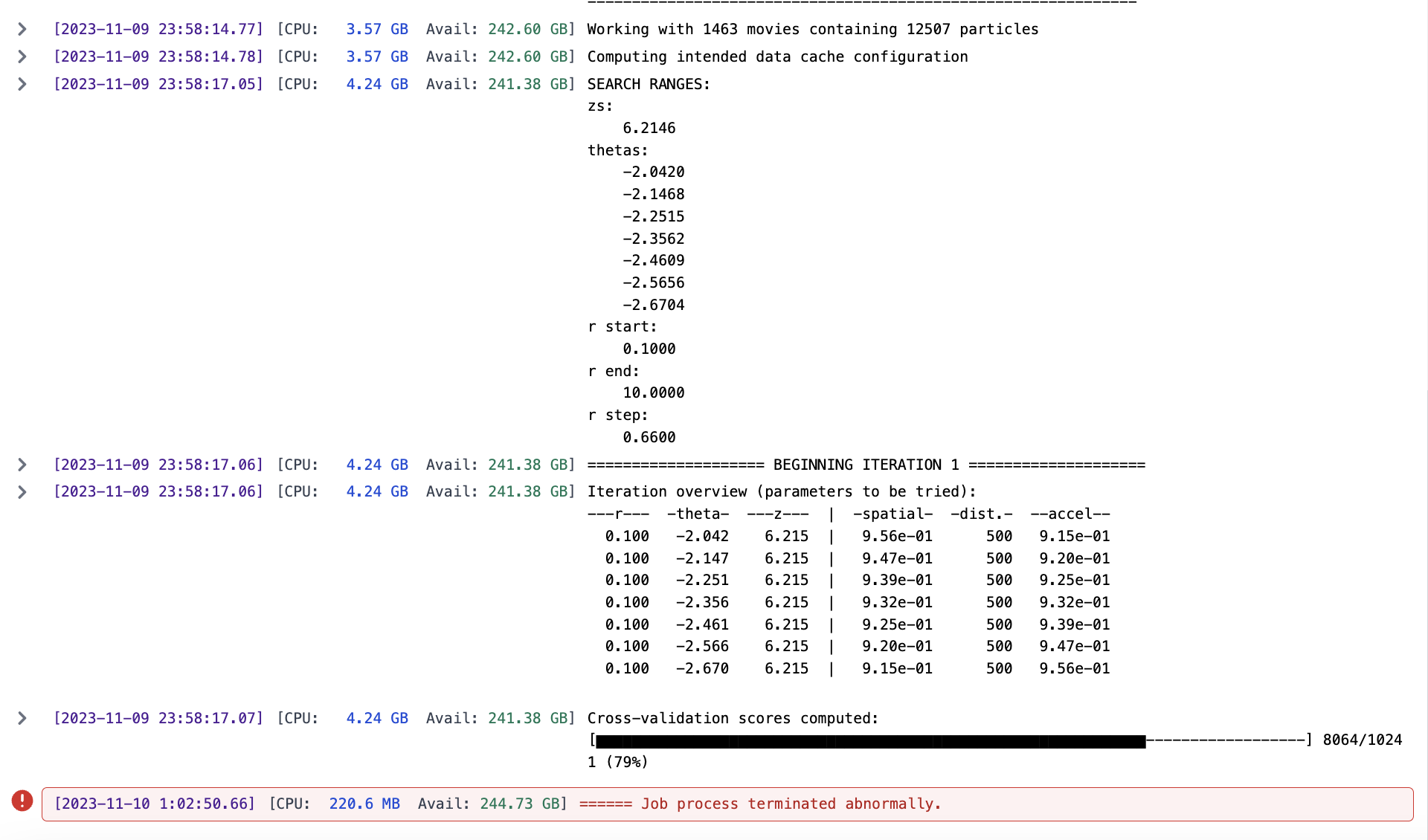
I’m not sure how to diagnose this, as the only error message I get is the job was terminated abnormally. I have successfully updated drivers and have tested 3D classification, refinements and orientation diagnosis, all working with my v4.4.
To add a little to this error. I have also tested the test-dataset and everything runs smoothy, I used the job builder to build every job, instead cryosparc live. Reference based motion correction works in this case.
So it’s likely some difference between the data sets.
Sincerely,
Connor Arkinson.