Hi,
I can tell you I have processed 1000s of Cryosparc jobs on this computer and using multiple versions of cs.
I’ve almost run every single type job type successfully. There is only one job I’ve never managed as it always fails and thats 3D Flex reconstruct.
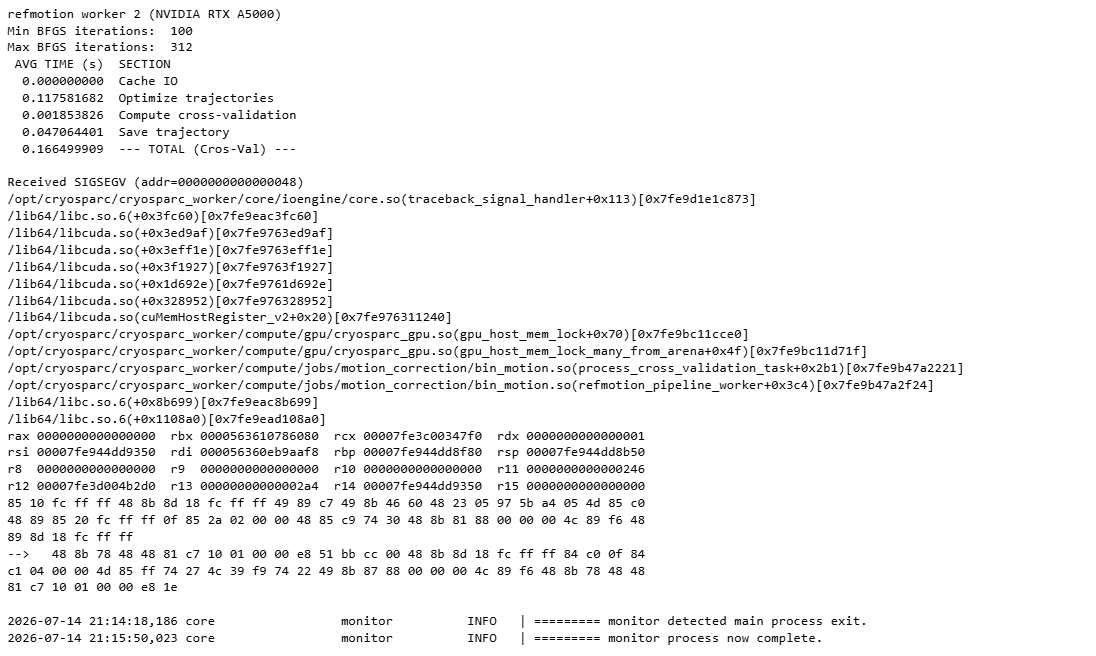
It will fail at this position and never succeeds at processing the first particle stack (i’ve tested multiple particle stacks):
RBMC is the only other job I’ve had issues with, and this one is odd because it works sometimes.
My work around has been for a single conformation:
- Take movies with most particles per movie (I ended up with 290 movies with 4.8K particles
- run RBMC with these movies (estimate trajectories and dose weights)
- test in refinement if improved and it was successful
- split my movies into stack of ~470 movies per stack.
- run RBMC with previously calculated trajectories/dose weights with each stack and pool all particles together for refinement.
My compute setting for each stack typically start with 4 GPUs, 100 gb over, 0.8 cache (i’ve messed with 0.2, 0.4, 0.6, not really noticing a difference in speed or failure). Each one takes around 30 mins.
When they fail I attempt with 1 GPU same settings and sometimes it fixes it. However sometimes I need to reset the computer and then try again. These one’s typically take 90 mins with 1 GPU.
I still have 8 more movie stacks to go through.
I have tested some of the particles I have RBMC’d so far (~53K) and the resolution is at 2.9A, which is equal to the full particle stack (~90K) at 2.9A.
I hope this helps, I’ve used multiple versions of cryosparc.
Our goal is going to be to set a cron job to clear out the cache on some kind of regular basis.
Edit: with 4.4v specifically I’ve rerun patch motion, patch CTF, blob picking, extraction, ab intio, hetero, homo and NU refinements, symmetry expansion, alignments tools, 3D variability, cluster, local refinements etc.
Connor