Do you have 512GB RAM? That free memory makes me think it ran out of system RAM. Check dmesg to see whether the kernel freaked out and the OOM reaper kicked in…
I have also opened the log file externaly (~250 Mb) and here is the latest lines
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
TIFFReadDirectory: Unknown field with tag 65002 (0xfdea) encountered
========= main process now complete at 2024-01-17 19:52:23.319551.
========= monitor process now complete at 2024-01-17 19:52:24.701361.
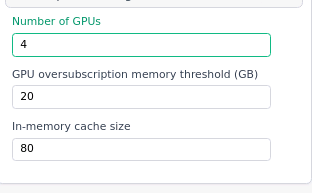
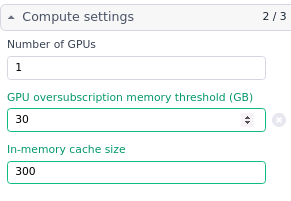
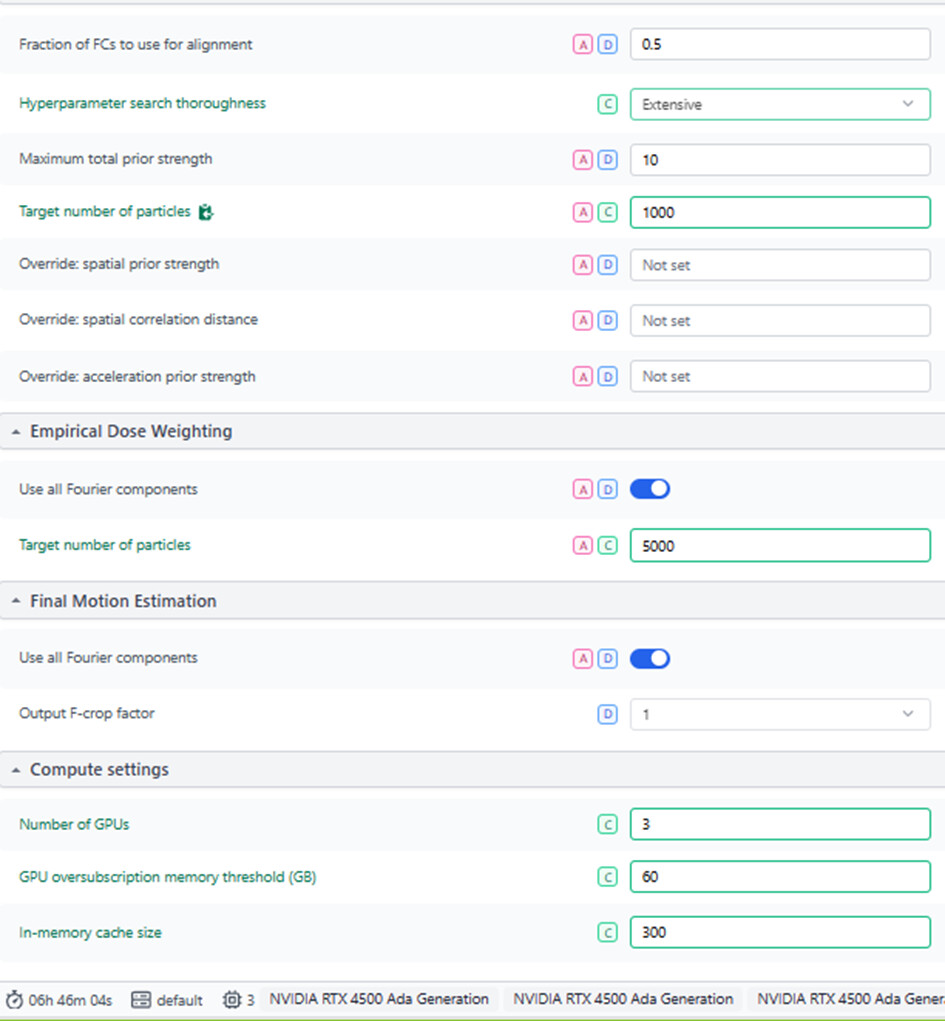
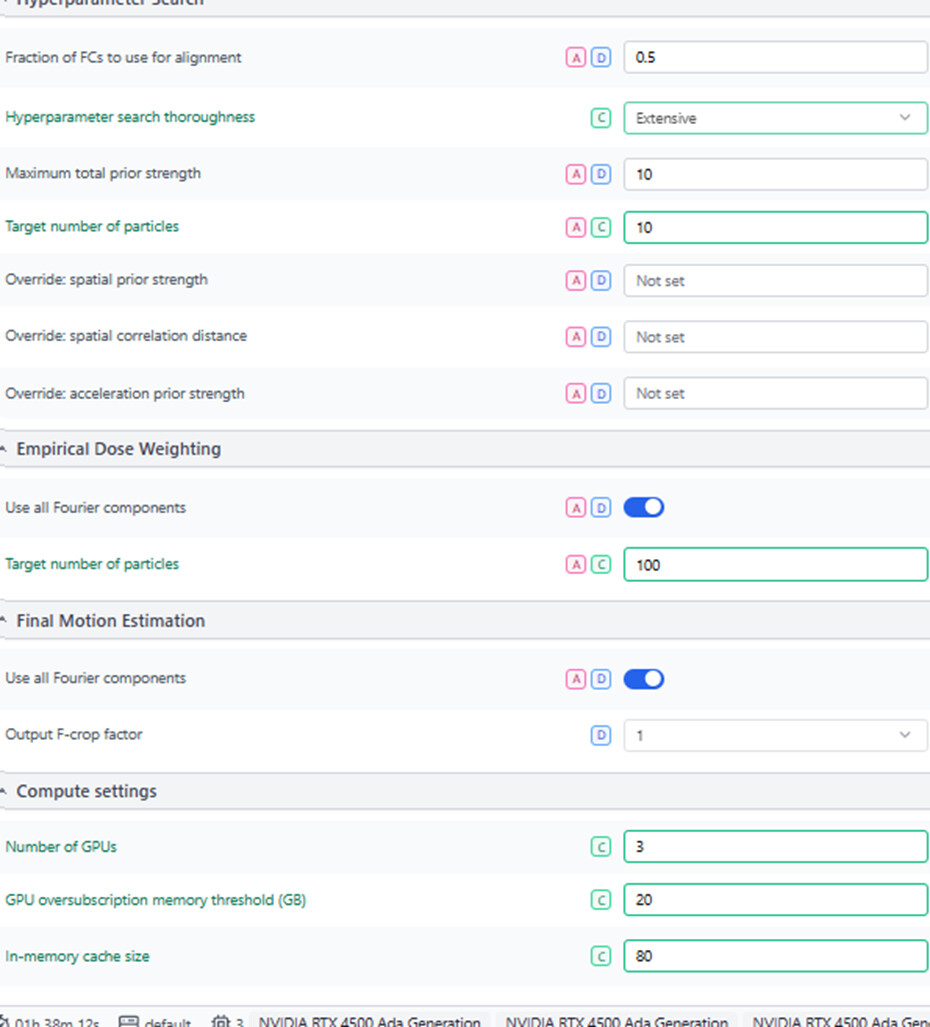
First thing I’d test is run on a single GPU and set the oversubscription threshold over the GPU VRAM (e.g. on 16GB, leave at 20, on 24GB, set to 30, etc) and the in-memory cache to 300.
RBMC system RAM usage oscillates a bit based on particles on each micrograph, so it’s possible one micrograph needs >80GB of system RAM… EER data can be particularly heavy if upsampling 2 (I’ve not tried 16K in CryoSPARC…)
Hi @Dmitry, that seems very odd…! Sorry, it really sounded like it was running out of memory…
Let me just check that step 3 was run with the same conditions as step 2 (1GPU 30 VRAM, 300 RAM)? It seems odd to me that increasing the hardware parameters changes the crash (and makes it later) but upon fixing the duplicate issue it crashes back where it used to once again…
Does dmesg have anything which might shed further light on the situation?
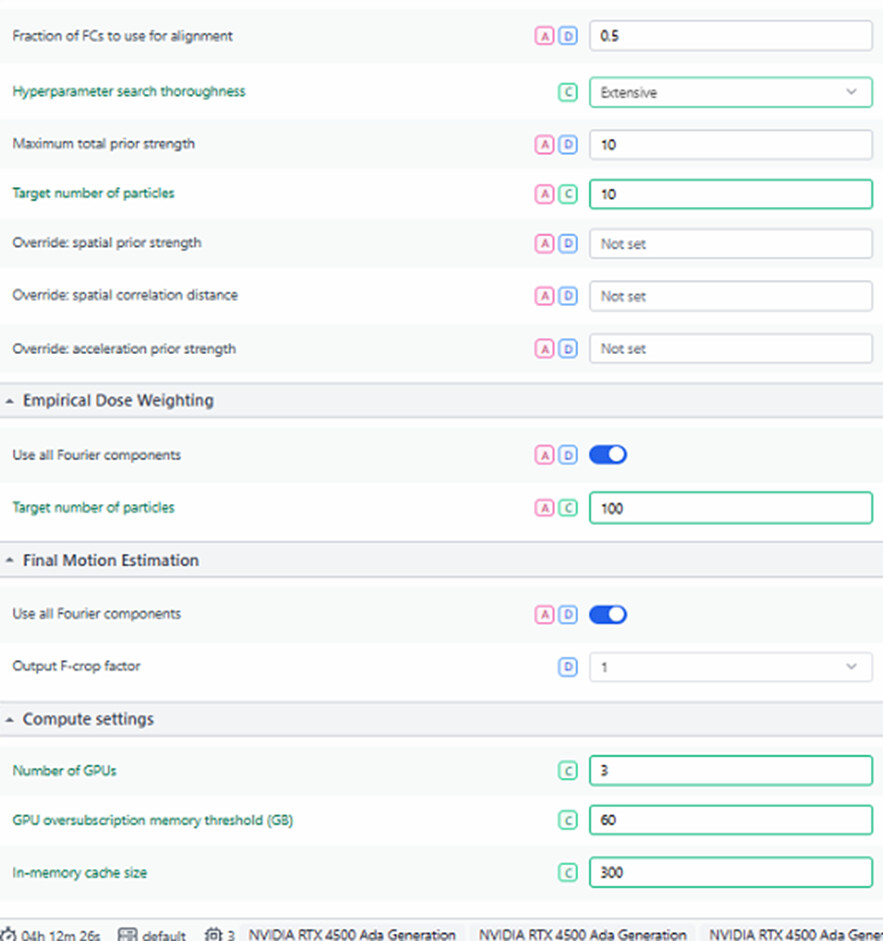
This is crashing on hyperparameter search…? Can you try fewer particles (say, 5,000)? Even try 1,000 just to see if it can complete successully (although don’t use that parameter set if it does work…
Part of the issue is the TIFFRead spam in the log, which makes it really hard to track anything else (RELION has the same issue by default when motion correcting/polishing EER because libtiff doesn’t understand the EER headers)… if you cat [/path/to/logfile] | grep -v TIFFReadDirectory > ~/tempLog.txt it will filter out all the pointless TIFFRead warnings and make it a little easier to see what’s going on (if it has any information)…
– @wtempel , and @hsnyder do you have the test dataset I can run the Reference based motion correction to see what is wrong?
– Can it be some issue with CS installation?
– Can the initial wrong input parameters cause such an issue? What about the total dose?
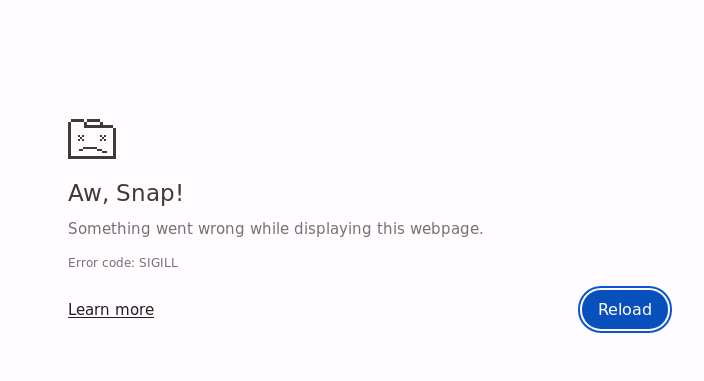
Additionally, when I try to load the report from each failed protocol (reference-based motion cor)
I get the following error
But finally, the report is being downloaded anyhow.
Let me know if I can send you the reports to you.
For testing, you may run Reference Based Motion Correction with outputs from Extensive Validation with the T20s subset:
“Movies” from the validation’s Patch Motion Correction
particles and volume from the validation’s Homogeneous Refinement
Is your CryoSPARC master computer also acting as a GPU worker for the aforementioned motion correction jobs? Was a job running when you attempted to download the report?
you said: “Is your CryoSPARC master computer also acting as a GPU worker for the aforementioned motion correction jobs? Was a job running when you attempted to download the report?”
I am not sure - how to check that?
I tried to reproduce the downloading error - starting the Reference based motion correction and downloading the report, also when CS and system is not running any protocol. But currently the report downloads work without an issue.