I’m trying to run Reference Based Motion Correction but I get the following error message (see below). As inputs I’m linking particles, volume and Mask from a NU-Refine job:
====== Job process terminated abnormally.
DIE: particle pairwise distance matrix is singular, check for duplicate particles (sgetrf failed)
========= monitor process now starting main process at 2023-12-13 16:16:40.225034
MAINPROCESS PID 859025
MAIN PID 859025
motioncorrection.run_reference_motion cryosparc_compute.jobs.jobregister
========= monitor process now waiting for main process
REDACTED
Override mask provided for volume_0
FSC No-Mask… 0.143 at 77.236 radwn. 0.5 at 72.221 radwn. Took 0.304s.
FSC With Mask… 0.143 at 78.500 radwn. 0.5 at 76.667 radwn. Took 0.082s.
========= sending heartbeat at 2023-12-13 16:16:53.604306
========= sending heartbeat at 2023-12-13 16:17:03.629890
========= sending heartbeat at 2023-12-13 16:17:13.655241
========= sending heartbeat at 2023-12-13 16:17:23.681984
========= sending heartbeat at 2023-12-13 16:17:33.706275
gpufft: creating new cufft plan (plan id 0 pid 859025)
gpu_id 0
ndims 3
dims 160 160 160
inembed 160 160 162
istride 1
idist 4147200
onembed 160 160 81
ostride 1
odist 2073600
batch 1
type R2C
wkspc automatic
Python traceback:
refmotion worker 1 (NVIDIA GeForce RTX 4090)
scale (alpha): 16.104767
noise model (sigma2): 72.801971
TIME (s) SECTION
0.000014817 sanity
2.303220899 read movie
0.037372439 get gain, defects
0.335987747 read bg
0.012685308 read rigid
1.527655743 prep_movie
1.259791484 extract from frames
0.000316716 extract from refs
0.000000391 adj
0.000000020 bfactor
0.002853359 rigid motion correct
0.000065611 get noise, scale
5.479964534 — TOTAL —
DIE: particle pairwise distance matrix is singular, check for duplicate particles (sgetrf failed)
========= main process now complete at 2023-12-13 16:17:40.788776.
========= monitor process now complete at 2023-12-13 16:17:40.874866.
I’m running v 4.4.1. The NU-refine job was done in C3. I did not perform symmetry expansion, but I am working with micrographs that do contain a large number of particles per image. The maximum reported number per micrograph according to a curate exposures job is 1610. For another project, I similarly had large numbers of particles per micrograph, which would trigger an out-of-memory error during the reference based motion correction. I’ll see if lowering the number of particles either through (i) remove particle duplicates with larger distances (e.g. 30A), or (ii) by splitting the particle stack into subsets (the latter worked for me on the other project where I was running into memory issues, despite the fact that I had set gpu_oversub_gb to 100, and mem_cache_sz to 0.8 on a system with 1.5TB of memory.
Will report back when the jobs either finish or crash.
Yes, that won’t matter. I see the same on another dataset, and the fix is the same - drop the number of particles per micrograph so that it doesn’t exceed the memory on the GPU. If you have 24GB GPUs, it’s pretty easy to run out of memory if you have enough particles per micrograph!
For comparison, on 24GB GPUs, 8K micrographs with ~90-100 particles per micrograph with 768 pixel boxes are OK, but the same micrographs and box size with 150+ particles per micrograph means running out of VRAM on 24GB GPUs. I’ve not tried finer grained tests than that.
I’m not sure exactly “how close is too close” for RBMC. Maybe one of the devs can chime in…?
I’ve lowered the maximum number of particles from 1610 to 425 by splitting into 4 subsets with randomize enabled. The total number of particles is 288k particles. My particle box size is 160, and I’m using 3 RTX 4090s. Although the RBMC manages to proceed further, it does still crash at some point and it outputs the same error.
I’m surprised by this to be honest, because for another project I was working with a box-size of 256 and the max number of particles per micrograph was upwards of 400. I did notice some ‘weird’ behavior. While doing a remove duplicates job with a distance of 20A, most of my particles were removed, i.e. 9247 kept versus 568578 removed. It is not clear to me why this is happening: my FSC curves go to zero at high frequencies, and the 2D classification jobs preceding the NU-refine job had “remove duplicates” enabled.
EDIT: upon closer inspection, one of my 2D classification jobs did NOT have remove duplicates enabled and the particles were picked using the filament tracer, so perhaps these particles are causing downstream issues. Will investigate further.
Is there a way to know which micrograph is the likely culprit ? The progress bar reached 67% during the computing of the cross-validation scores:
Cross-validation scores computed:
[▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇▇---------------------------] 13126/19495 (67%)
DIE: particle pairwise distance matrix is singular, check for duplicate particles (sgetrf failed)
====== Job process terminated abnormally.
I can address your questions about remove duplicates and filament picking. Since filament picking chooses locations along the filament axis with fairly dense spacing, this is likely why RBMC is crashing with particles being too close together (hence causing this singular matrix error).
There are two possible workarounds:
Re-picking particles with a greater “Separation distance between segments”. What this will do is pick particles further apart along the helical axis, and thus reduce the chance of particles being too close together for RBMC to handle. This will necessitate a repeat in the workflow for everything post-particle-picking (e.g. 2D class, helical/CTF refinement, and RBMC).
Run a standalone “Remove Duplicate Particles” job with a minimum separation distance less than 20 Å, on the particles prior to inputting them into RBMC. Since using a minimum separation distance of 20 Å resulted in removing the vast majority of your particles, I’d suggest trying a value significantly smaller (maybe in the range of 5-10Å) to keep more particles, and then seeing if RBMC works on the downstream particles from that job.
Unfortunately we don’t have a good idea of the exact minimum distance between particles that causes this error, so in either workaround 1 or 2 you may need to play with the minimum distance between particles. Workaround #2 is certainly faster for this purpose, but workaround #1 would keep more of your data. On our side, we have noted to look into better handling of coincident or close-picked particles in RBMC.
thank you for your suggestion. Repicking is something I may have to resort to at some point if I cannot get this problem resolved, but I would like to keep that as the last option as I am working with 6 different optics groups, and it has taken a lot of effort to filter down my particles to the current stack. Moreover, I’m not quite sure that this will solve the issue as I have already removed the particles that were picked using the filament tracer. Also, I have already run a number of “Remove Duplicates” jobs, using incrementally greater inter-particle distances, going from 10A all the way up to 70A. Initially my job would crash during the hyper-parameter search. By removing duplicates at 20A distance I could reach the dose-weighting section, but still it would crash with the same error. Now, at 70A, I can reach the actual motion correction but cryosparc still crashes with the dreaded “DIE: particle pairwise distance matrix is singular, check for duplicate particles (sgetrf failed)”.
Question: I’m assuming the crashes are being triggered by a singular / or only handful of images. If one could see at which point (i.e. the exposure name) RBMC crashes, a simple workaround could be to remove the culprit image(s). I would prefer to remove only a handful of images, than 10% of my particles (which is now the case at 70A inter-particle distance, during the remove duplicates job).
I got the same error. I have run a local motion correction before RBMC without problem. I have 1.1M particles from 8k movies. My protein has no symmetry and is not filament. My box size is 360. The workstation has 4x 3090. I first found particles from some classes can run RBMC until the dose weight. Then I used the precalculated parameters to do RBMC for each class separately. But I still found each class stopped with the error. Hopefully there would be a easy way to handle this without losing particles.
Split the particle set up and run RBMC multiple times with the same parameters. Worked for me, although the final dataset only gets to ~0.07Å higher resolution than the best of the subsets, which shows the point at which returns from increasing particle count diminishes…
I’ve discussed with the team and we don’t have a clear idea as to why a 70 Å distance would be insufficient to workaround this error. Just to confirm, are you running RBMC on the outputs of one Remove Duplicate Particle job with the 70Å separation distance (i.e. not combining particles from multiple jobs)?
If so, we’d appreciate taking a look at the cs file from the remove duplicate particles job. I will follow up over DM with instructions on how you could share this cs file with our team.
Is there any solution for this? I encountered this problem for the first time with filament data. It is very weird because the filament data with much denser particles didn’t have any problem but one had this problem despite trying to remove duplicate etc.
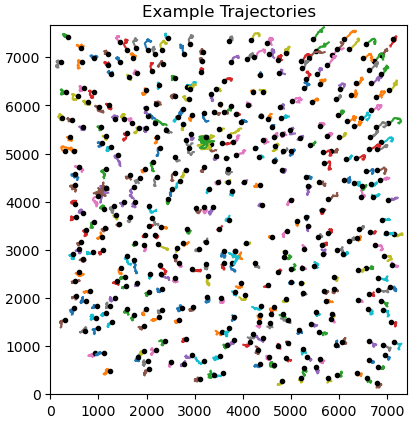
CryoSPARC v4.5 (released today) changes the way we handle this, and the “singular matrix” error should not occur anymore. We now use the Moore-Penrose pseudoinverse in computing the spatial prior, so if there are problematic particle positions, those particles will be under-regularized but the rest of the micrograph will process correctly. Here’s an example of what the trajectories can look like when this happens — you’ll notice that a few particle have spikier trajectories than the others do.