We have been successfully using cryosparc on a large and shared HPC resource of our
university for a while. Today I tried to update from v4.0.2 (which was running
without issues) to 4.1.1 with patch 230110. However, after the update
jobs (e.g. ab-initio) aborted with Module not Found errors specifying
that pycuda wasn’t found:
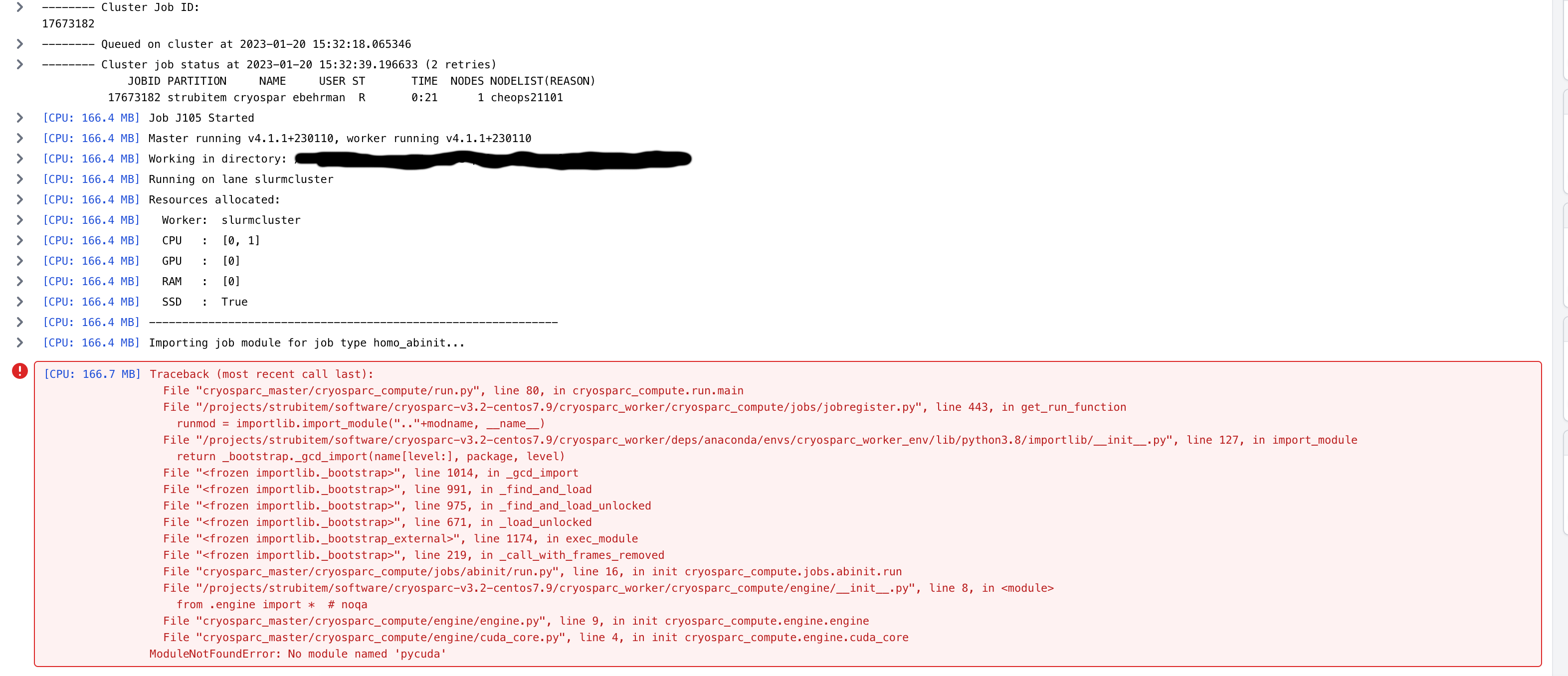
Therefore, I tried a manual update on the worker node as described on the guide (Software Updates and Patches - CryoSPARC Guide). This showed that indeed pycuda is failing to install:
Installing collected packages: pycuda
DEPRECATION: pycuda is being installed using the legacy 'setup.py install' method, because the '--no-binary' option was enabled for it and this currently disables local wheel building for projects that don't have a 'pyproject.toml' file. pip 23.1 will enforce this behaviour change. A possible replacement is to enable the '--use-pep517' option. Discussion can be found at https://github.com/pypa/pip/issues/11451
Running setup.py install for pycuda ... error
error: subprocess-exited-with-error
× Running setup.py install for pycuda did not run successfully.
│ exit code: 1
╰─> [11067 lines of output]
However I am unsure why as nvidia-smi finds both GPUs and nvcc is present. As the log shows errors related to gcc: could this be related to the error that was addressed with v.4.1.1?
gcc -Wno-unused-result -Wsign-compare -fwrapv -Wall -O3 -DNDEBUG -fPIC -DBOOST_ALL_NO_LIB=1 -DBOOST_THREAD_BUILD_DLL=1 -DBOOST_MULTI_INDEX_DISABLE_SERIALIZATION=1 -DBOOST_PYTHON_SOURCE=1 -Dboost=pycudaboost -DBOOST_THREAD_DONT_USE_CHRONO=1 -DPYGPU_PACKAGE=pycuda -DPYGPU_PYCUDA=1 -DHAVE_CURAND=1 -Isrc/cpp -Ibpl-subset/bpl_subset -I/opt/rrzk/lib/cuda/11.3/include -I/projects/strubitem/software/cryosparc-v3.2-centos7.9/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/numpy/core/include -I/projects/strubitem/software/cryosparc-v3.2-centos7.9/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/include/python3.8 -c bpl-subset/bpl_subset/libs/python/src/converter/arg_to_python_base.cpp -o build/temp.linux-x86_64-cpython-38/bpl-subset/bpl_subset/libs/python/src/converter/arg_to_python_base.o
In file included from bpl-subset/bpl_subset/boost/python/handle.hpp:10:0,
from bpl-subset/bpl_subset/boost/python/converter/arg_to_python_base.hpp:7,
from bpl-subset/bpl_subset/libs/python/src/converter/arg_to_python_base.cpp:6:
bpl-subset/bpl_subset/boost/python/cast.hpp: In function ‘void pycudaboost::python::detail::assert_castable(pycudaboost::type<Target>*)’:
bpl-subset/bpl_subset/boost/python/cast.hpp:73:20: warning: typedef ‘must_be_a_complete_type’ locally defined but not used [-Wunused-local-typedefs]
typedef char must_be_a_complete_type[sizeof(T)];
^~~~~~~~~~~~~~~~~~~~~~~