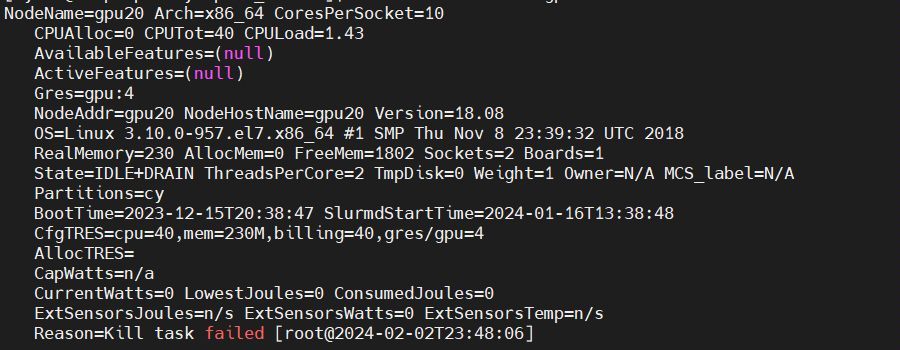
- Here is the output of
cryosparcm cli "get_scheduler_targets()"
[{'cache_path': '/gpu_temp', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'custom_var_names': [], 'custom_vars': {}, 'desc': None, 'hostname': 'cy', 'lane': 'cy', 'name': 'cy', 'qdel_cmd_tpl': 'scancel {{ cluster_job_id }}', 'qinfo_cmd_tpl': 'sinfo', 'qstat_cmd_tpl': 'squeue -j {{ cluster_job_id }}', 'qstat_code_cmd_tpl': None, 'qsub_cmd_tpl': 'sbatch {{ script_path_abs }}', 'script_tpl': '#!/usr/bin/env bash\n#### cryoSPARC cluster submission script template for SLURM\n## Available variables:\n## {{ run_cmd }} - the complete command string to run the job\n## {{ num_cpu }} - the number of CPUs needed\n## {{ num_gpu }} - the number of GPUs needed. \n## Note: the code will use this many GPUs starting from dev id 0\n## the cluster scheduler or this script have the responsibility\n## of setting CUDA_VISIBLE_DEVICES so that the job code ends up\n## using the correct cluster-allocated GPUs.\n## {{ ram_gb }} - the amount of RAM needed in GB\n## {{ job_dir_abs }} - absolute path to the job directory\n## {{ project_dir_abs }} - absolute path to the project dir\n## {{ job_log_path_abs }} - absolute path to the log file for the job\n## {{ worker_bin_path }} - absolute path to the cryosparc worker command\n## {{ run_args }} - arguments to be passed to cryosparcw run\n## {{ project_uid }} - uid of the project\n## {{ job_uid }} - uid of the job\n## {{ job_creator }} - name of the user that created the job (may contain spaces)\n## {{ cryosparc_username }} - cryosparc username of the user that created the job (usually an email)\n##\n## What follows is a simple SLURM script:\n\n#SBATCH --job-name cryosparc_{{ project_uid }}_{{ job_uid }}\n#SBATCH -n {{ num_cpu }}\n#SBATCH --gres=gpu:{{ num_gpu }}\n#SBATCH -p cy\n###SBATCH --mem={{ (ram_gb*1000)|int }}MB \n#SBATCH -o {{ job_dir_abs }}/run.out\n#SBATCH -e {{ job_dir_abs }}/run.err\n#module load cuda80/toolkit/8.0.61\n#module load cuda80/fft/8.0.61\n#module load cuda10.1\n\n#echo "PATH is ${PATH}"\n#echo "LD_LIBRARY_PATH is ${LD_LIBRARY_PATH}"\n\navailable_devs=""\nfor devidx in $(seq 0 15);\ndo\n if [[ -z $(nvidia-smi -i $devidx --query-compute-apps=pid --format=csv,noheader) ]] ; then\n if [[ -z "$available_devs" ]] ; then\n available_devs=$devidx\n else\n available_devs=$available_devs,$devidx\n fi\n fi\ndone\nexport CUDA_VISIBLE_DEVICES=$available_devs\n\n{{ run_cmd }}\n', 'send_cmd_tpl': '{{ command }}', 'title': 'cy', 'tpl_vars': ['run_args', 'cluster_job_id', 'worker_bin_path', 'job_log_path_abs', 'ram_gb', 'project_dir_abs', 'num_gpu', 'job_creator', 'job_uid', 'cryosparc_username', 'command', 'job_dir_abs', 'run_cmd', 'num_cpu', 'project_uid'], 'type': 'cluster', 'worker_bin_path': '/cm/shared/apps/cryosparc/cylab/cryosparc_worker/bin/cryosparcw'}]
grep -v LICENSE /path/to/cryosparc_worker/config.sh
export CRYOSPARC_USE_GPU=true
export CRYOSPARC_IMPROVED_SSD_CACHE=true
export CRYOSPARC_CACHE_NUM_THREADS=1
- The Event log of failed NU-refinement job
> [2024-01-21 1:47:11.95] License is valid.
> [2024-01-21 1:47:11.95] Launching job on lane cy target cy ...
> [2024-01-21 1:47:12.03] Launching job on cluster cy
> [2024-01-21 1:47:12.04] ====================== Cluster submission script: ========================
==========================================================================
#!/usr/bin/env bash
#### cryoSPARC cluster submission script template for SLURM
## Available variables:
## /cm/shared/apps/cryosparc/cylab/cryosparc_worker/bin/cryosparcw run --project P27 --job J190
--master_hostname shipmhpc --master_command_core_port 45102 > /work/caolab/yu.cao/CS-ly-ribo/J190/job.log
2>&1 - the complete command string to run the job
## 4 - the number of CPUs needed
## 1 - the number of GPUs needed.
## Note: the code will use this many GPUs starting from dev id 0
## the cluster scheduler or this script have the responsibility
## of setting CUDA_VISIBLE_DEVICES so that the job code ends up
## using the correct cluster-allocated GPUs.
## 24.0 - the amount of RAM needed in GB
## /work/caolab/yu.cao/CS-ly-ribo/J190 - absolute path to the job directory
## /work/caolab/yu.cao/CS-ly-ribo - absolute path to the project dir
## /work/caolab/yu.cao/CS-ly-ribo/J190/job.log - absolute path to the log file for the job
## /cm/shared/apps/cryosparc/cylab/cryosparc_worker/bin/cryosparcw - absolute path to the cryosparc
worker command
## --project P27 --job J190 --master_hostname shipmhpc --master_command_core_port 45102 -
arguments to be passed to cryosparcw run
## P27 - uid of the project
## J190 - uid of the job
## yu.cao - name of the user that created the job (may contain spaces)
## yu.cao@shsmu.edu.cn - cryosparc username of the user that created the job (usually an email)
##
## What follows is a simple SLURM script:
#SBATCH --job-name cryosparc_P27_J190
#SBATCH -n 4
#SBATCH --gres=gpu:1
#SBATCH -p cy
###SBATCH --mem=24000MB
#SBATCH -o /work/caolab/yu.cao/CS-ly-ribo/J190/run.out
#SBATCH -e /work/caolab/yu.cao/CS-ly-ribo/J190/run.err
#module load cuda80/toolkit/8.0.61
#module load cuda80/fft/8.0.61
#module load cuda10.1
#echo "PATH is ${PATH}"
#echo "LD_LIBRARY_PATH is ${LD_LIBRARY_PATH}"
available_devs=""
for devidx in $(seq 0 15);
do
if [[ -z $(nvidia-smi -i $devidx --query-compute-apps=pid --format=csv,noheader) ]] ; then
if [[ -z "$available_devs" ]] ; then
available_devs=$devidx
else
available_devs=$available_devs,$devidx
fi
fi
done
export CUDA_VISIBLE_DEVICES=$available_devs
/cm/shared/apps/cryosparc/cylab/cryosparc_worker/bin/cryosparcw run --project P27 --job J190
--master_hostname shipmhpc --master_command_core_port 45102 > /work/caolab/yu.cao/CS-ly-ribo/J190/job.log
2>&1
==========================================================================
==========================================================================
> [2024-01-21 1:47:12.05] -------- Submission command:
sbatch /work/caolab/yu.cao/CS-ly-ribo/J190/queue_sub_script.sh
> [2024-01-21 1:47:12.09] -------- Cluster Job ID:
68
> [2024-01-21 1:47:12.09] -------- Queued on cluster at 2024-01-21 14:47:12.099717
> [2024-01-21 1:47:12.69] -------- Cluster job status at 2024-01-21 14:51:17.090480 (24 retries)
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
68 cy cryospar cylab R 4:05 1 gpu21
> [2024-01-21 1:51:19.55] [CPU: 180.8 MB] Job J190 Started
> [2024-01-21 1:51:19.61] [CPU: 180.8 MB] Master running v4.4.1, worker running v4.4.1
> [2024-01-21 1:51:19.64] [CPU: 180.8 MB] Working in directory: /work/caolab/yu.cao/CS-ly-ribo/J190
> [2024-01-21 1:51:19.64] [CPU: 180.8 MB] Running on lane cy
> [2024-01-21 1:51:19.64] [CPU: 180.8 MB] Resources allocated:
> [2024-01-21 1:51:19.65] [CPU: 180.8 MB] Worker: cy
> [2024-01-21 1:51:19.65] [CPU: 180.8 MB] CPU : [0, 1, 2, 3]
> [2024-01-21 1:51:19.65] [CPU: 180.8 MB] GPU : [0]
> [2024-01-21 1:51:19.66] [CPU: 180.8 MB] RAM : [0, 1, 2]
> [2024-01-21 1:51:19.67] [CPU: 180.8 MB] SSD : True
> [2024-01-21 1:51:19.67] [CPU: 180.8 MB] --------------------------------------------------------------
> [2024-01-21 1:51:19.68] [CPU: 180.8 MB] Importing job module for job type nonuniform_refine_new...
> [2024-01-21 1:51:26.60] [CPU: 257.7 MB] Job ready to run
> [2024-01-21 1:51:26.60] [CPU: 257.7 MB] ***************************************************************
> [2024-01-21 1:51:48.47] [CPU: 1.10 GB] Using random seed of None
> [2024-01-21 1:51:48.53] [CPU: 1.14 GB] Loading a ParticleStack with 304331 items...
> [2024-01-21 1:51:49.00] [CPU: 1.14 GB] SSD cache : cache successfully synced in_use
> [2024-01-21 1:51:50.88] [CPU: 1.14 GB] SSD cache : cache successfully synced, found 115,654.03 MB of files on SSD.
> [2024-01-21 1:51:55.94] [CPU: 1.14 GB] SSD cache : cache successfully requested to check 4311 files.
> [2024-01-21 1:58:54.71] [CPU: 1.14 GB] SSD cache : cache requires 399,116 MB more on the SSD for files to be downloaded.
> [2024-01-21 1:58:56.12] [CPU: 1.14 GB] SSD cache : cache has enough available space.
> [2024-01-21 1:58:56.12] [CPU: 1.14 GB] Needed | 399,116.15 MB
Available | 1,242,260.08 MB
Disk size | 1,525,438.13 MB
Usable space | 1,515,438.13 MB (reserve 10,000 MB)
> [2024-01-21 1:58:56.13] [CPU: 1.14 GB] Transferring across 2 threads:
000187370811886476155_FoilHole_18239858_Data_18234987_18234989_20230818_163132_fractions
_shiny.mrcs (44/4311)
Progress | 4,029 MB (1.01%)
Total | 399,116 MB
Average speed | 52.57 MB/s
ETA | 2h 5m 14s
> [2024-01-21 2:09:28.33] **** Kill signal sent by CryoSPARC (ID: <Heartbeat Monitor>) ****
> [2024-01-21 2:09:45.07] Job is unresponsive - no heartbeat received in 180 seconds.
- And job log of failed Cache particles on SSD
================= CRYOSPARCW ======= 2024-01-26 00:30:46.070320 =========
Project P1 Job J2641
Master shipmhpc Port 45102
===========================================================================
========= monitor process now starting main process at 2024-01-26 00:30:46.070412
MAINPROCESS PID 26332
========= monitor process now waiting for main process
MAIN PID 26332
utilities.run_cache_particles cryosparc_compute.jobs.jobregister
***************************************************************
2024-01-26 00:30:56,833 run_with_executor INFO | Resolving 7256 source path(s) for caching
========= sending heartbeat at 2024-01-26 00:31:02.792498
========= sending heartbeat at 2024-01-26 00:31:12.803054
========= sending heartbeat at 2024-01-26 00:31:22.823665
2024-01-26 00:31:26,695 run_with_executor INFO | Resolved sources in 29.86 seconds
2024-01-26 00:31:27,576 cleanup_junk_files INFO | Removed 5821 invalid item(s) in the cache
2024-01-26 00:31:28,306 run_with_executor INFO | Cache allocation ran in 1.51 seconds
2024-01-26 00:31:28,306 run_with_executor INFO | Found 1436 SSD hit(s)
2024-01-26 00:31:28,306 run_with_executor INFO | Transferring 5820 file(s)...
2024-01-26 00:31:29,635 run_with_executor INFO | Transferred /work/caolab/yu.cao/LuYi/20230519_WO4/Extract/job131/rawdata/FoilHole_19236997_Data_19228125_19228127_20230519_175211_fractions.mrcs to SSD key f282b498b3db47f1e6c5010e1cfd5cb6b9c1f54a...
2024-01-26 00:31:30,869 run_with_executor INFO | Transferred /work/caolab/yu.cao/LuYi/20230519_WO4/Extract/job131/rawdata/FoilHole_19236583_Data_19228125_19228127_20230519_172109_fractions.mrcs to SSD key ade405bf4ba9a727e3f6e2e2b641f16c6cff3dfd...
2024-01-26 00:31:32,393 run_with_executor INFO | Transferred /work/caolab/yu.cao/LuYi/20230519_WO4/Extract/job131/rawdata/FoilHole_19257811_Data_19228125_19228127_20230521_012018_fractions.mrcs to SSD key 6b0b31c292ea1a546c4537d15b102d66c41b8507...
========= sending heartbeat at 2024-01-26 00:31:32.843094
... Omit some similar log information ...
2024-01-26 01:43:12,944 run_with_executor INFO | Transferred /work/caolab/yu.cao/LuYi/20230519_WO4/Extract/job131/rawdata/FoilHole_19244211_Data_19228125_19228127_20230520_101656_fractions.mrcs to SSD key 6f3a0d694576bc80359eb3a2eb3d08ff942f4436...
========= sending heartbeat at 2024-01-26 01:43:13.838008
2024-01-26 01:43:14,727 run_with_executor INFO | Transferred /work/caolab/yu.cao/LuYi/20230519_WO4/Extract/job131/rawdata/FoilHole_19248551_Data_19228125_19228127_20230520_162940_fractions.mrcs to SSD key 2c6ffe715a0456b1445e8dc148da57c5ef774d2c...
========= sending heartbeat at 2024-01-26 01:43:23.858818
========= sending heartbeat at 2024-01-26 01:43:33.878336
========= sending heartbeat at 2024-01-26 01:43:43.897752
========= sending heartbeat at 2024-01-26 01:43:53.919049
========= sending heartbeat at 2024-01-26 01:44:03.938244
========= sending heartbeat at 2024-01-26 01:44:13.957391
========= sending heartbeat at 2024-01-26 01:44:23.972807
========= sending heartbeat at 2024-01-26 01:44:33.982990
========= sending heartbeat at 2024-01-26 01:44:43.993090
========= sending heartbeat at 2024-01-26 01:44:54.013351
========= sending heartbeat at 2024-01-26 01:45:04.033164
========= sending heartbeat at 2024-01-26 01:45:14.052505
========= sending heartbeat at 2024-01-26 01:45:24.072957
========= sending heartbeat at 2024-01-26 01:45:34.092117
========= sending heartbeat at 2024-01-26 01:45:44.107228
========= sending heartbeat at 2024-01-26 01:45:54.117364
========= sending heartbeat at 2024-01-26 01:46:04.127541
========= sending heartbeat at 2024-01-26 01:46:14.137664
========= sending heartbeat at 2024-01-26 01:46:24.147798
========= sending heartbeat at 2024-01-26 01:46:34.157989
========= sending heartbeat at 2024-01-26 01:46:44.168093
========= sending heartbeat at 2024-01-26 01:46:54.188376
========= sending heartbeat at 2024-01-26 01:47:04.207433
========= sending heartbeat at 2024-01-26 01:47:14.226565
========= sending heartbeat at 2024-01-26 01:47:24.246281
========= sending heartbeat at 2024-01-26 01:47:34.266657
========= sending heartbeat at 2024-01-26 01:47:44.287137
========= sending heartbeat at 2024-01-26 01:47:54.305387
========= sending heartbeat at 2024-01-26 01:48:04.317681
========= sending heartbeat at 2024-01-26 01:48:14.330223
========= sending heartbeat at 2024-01-26 01:48:24.342826
========= sending heartbeat at 2024-01-26 01:48:34.355248
========= sending heartbeat at 2024-01-26 01:48:44.367856
========= sending heartbeat at 2024-01-26 01:48:54.380376
========= sending heartbeat at 2024-01-26 01:49:04.393067
========= sending heartbeat at 2024-01-26 01:49:14.405523