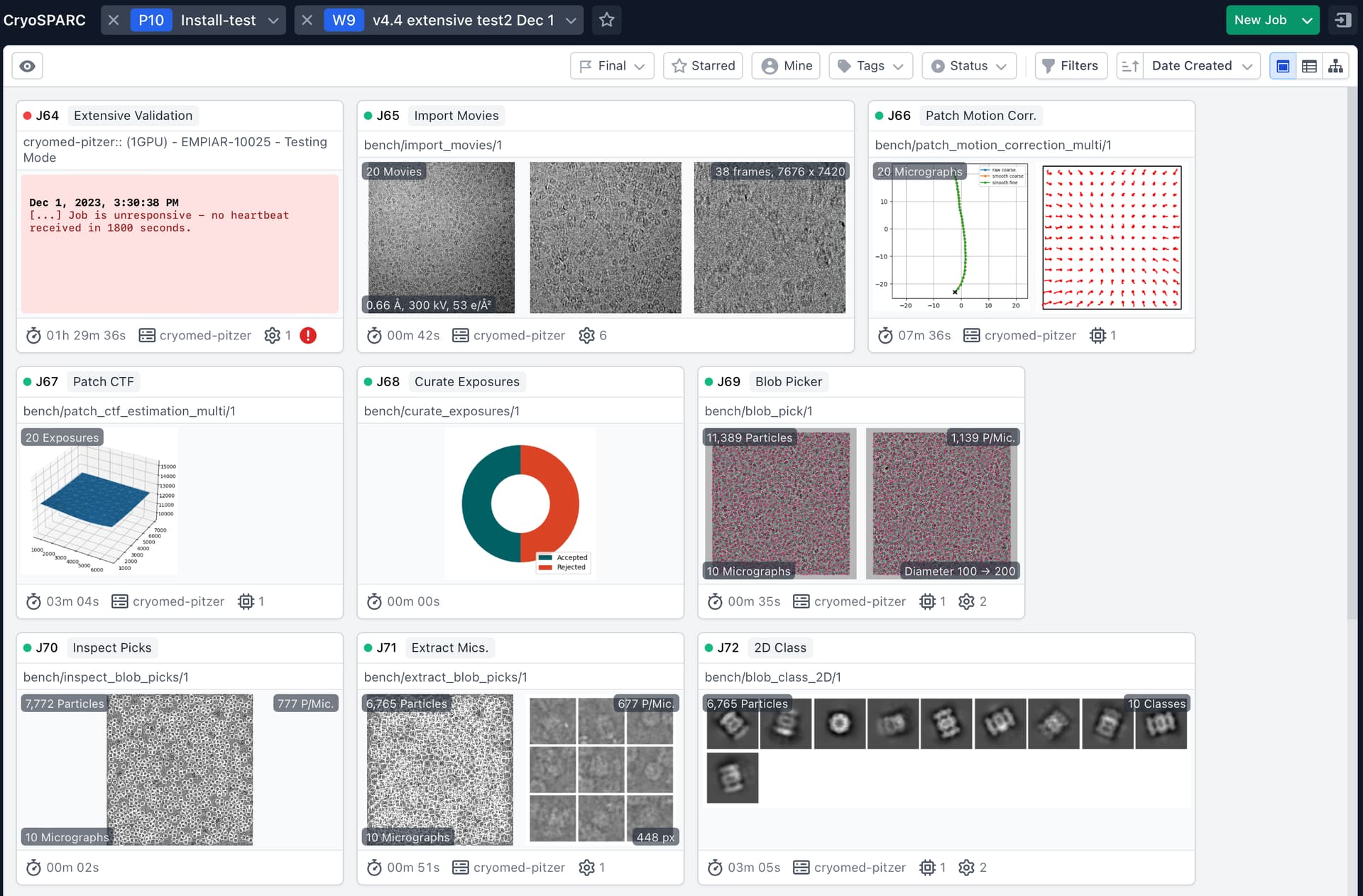
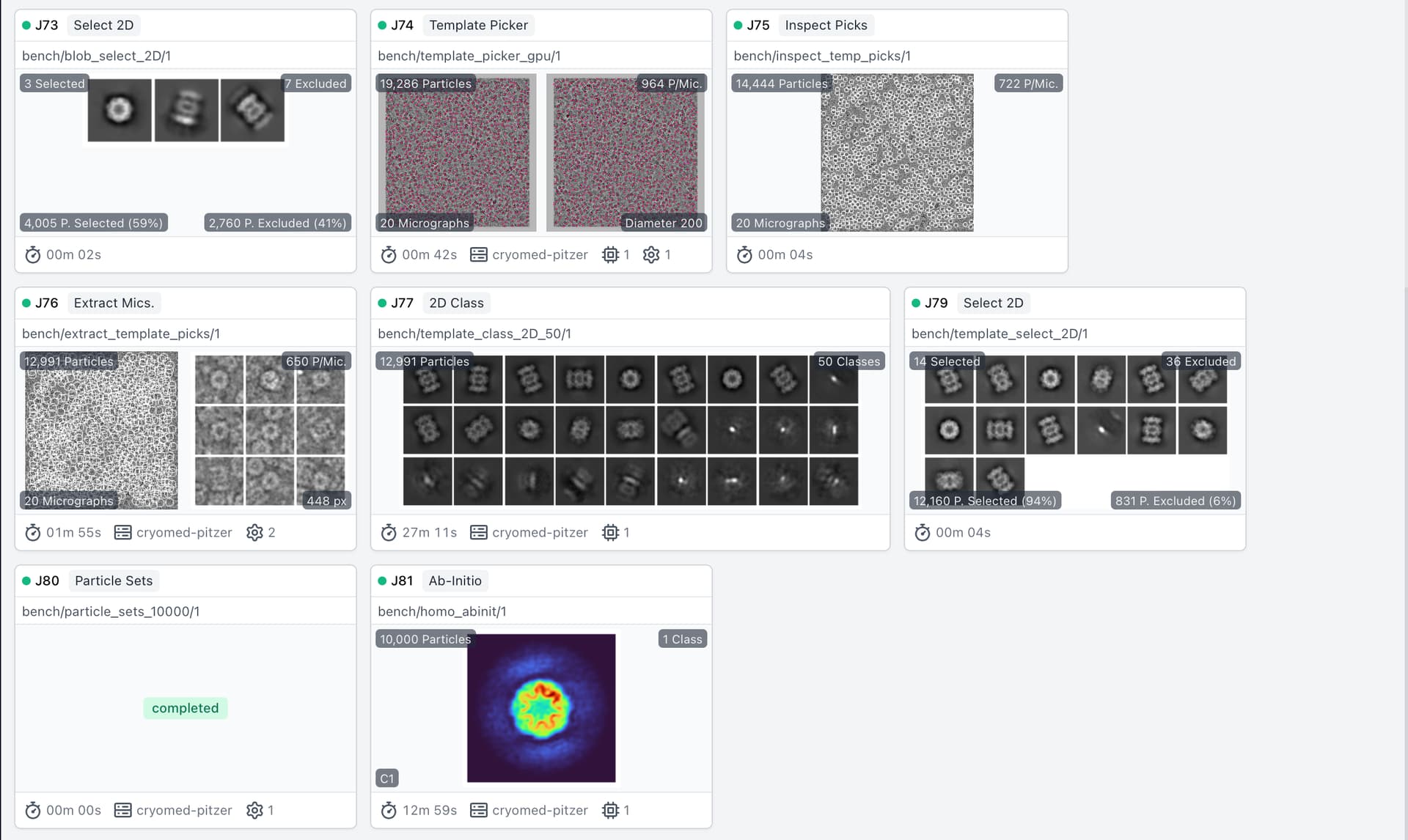
I updated it to v4.4 and tried to run the Extensive Validation with the empiar_10025_subset data.
But, I got this error after 17 successful jobs:
===========
[CPU: 180.4 MB] Launching job: abinit
Creating job abinit, (homo_abinit)
Scheduling homo_abinit (homo_abinit) P10, J81
**** Kill signal sent by CryoSPARC (ID: ) ****
Job is unresponsive - no heartbeat received in 1800 seconds.
===============
But, the job (P10, J81) was complete without issue.
I found that there was any new jobs created or submitted after the job (P10, J81), and plainly waited and failed as I described.
The job (P10, J81) is for Ab-initio, and the next job should be Homo Refine, I think. But, the Homo Refine was not created.
(I updated
export CRYOSPARC_HEARTBEAT_SECONDS=1800
I can observe what is happening after the job (P10, J81) was complete.)
I tried 4 times, and I got exactly the same errors for 3 times after exact 17 successful jobs.
But, in one case, it went to 19 jobs, but it failed with the same errors.
The extensive validation tests were just fine before the update.
Any comments/suggestions would be very helpful.
It is installed for a cluster.
Thanks!
-Heechang