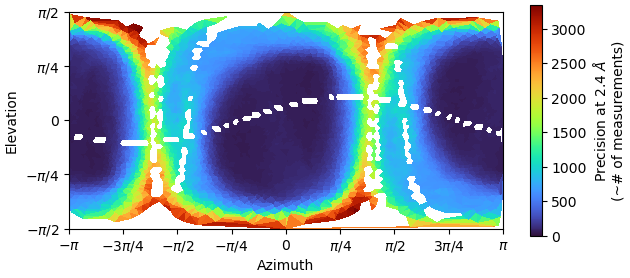
I used the mask having the local region created by chimera saved as same box size and binarized with Volume Tools to use it as local refinement input
Neither using the specified fulcrum value (measured in chimera) nor the default mask center or box center), i encounter the error above image.
I think the error is due to input mask because the local refinement job is working when i used the non-uniform refinement dynamic mask. However, when i used cryoSPARC v4.4.1, there are no problems with same mask creation method (chimera segger → import volume → volume tool). What should i do?
When i used gaussian prior option with default static mask option, it’s not working, but dynamic mask option successfully give the result. Are there any reasons why these coordination cause the error?
[CPU: 9.07 GB Avail:1011.49 GB]
Traceback (most recent call last):
File "/home/cryosparc_user/cryosparc/cryosparc_worker/cryosparc_compute/jobs/runcommon.py", line 2294, in run_with_except_hook
run_old(*args, **kw)
File "/home/cryosparc_user/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.10/threading.py", line 953, in run
self._target(*self._args, **self._kwargs)
File "cryosparc_master/cryosparc_compute/engine/newengine.py", line 2714, in cryosparc_master.cryosparc_compute.engine.newengine.process.work
File "cryosparc_master/cryosparc_compute/engine/newengine.py", line 2766, in cryosparc_master.cryosparc_compute.engine.newengine.process.work
File "cryosparc_master/cryosparc_compute/engine/newengine.py", line 1518, in cryosparc_master.cryosparc_compute.engine.newengine.EngineThread.compute_error
ValueError: Detected NaN values in newengine.compute_error. 11294500 NaNs in total, 500 particles with NaNs.
[CPU: 9.07 GB Avail:1011.49 GB]
Traceback (most recent call last):
File "/home/cryosparc_user/cryosparc/cryosparc_worker/cryosparc_compute/jobs/runcommon.py", line 2294, in run_with_except_hook
run_old(*args, **kw)
File "/home/cryosparc_user/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.10/threading.py", line 953, in run
self._target(*self._args, **self._kwargs)
File "cryosparc_master/cryosparc_compute/engine/newengine.py", line 2714, in cryosparc_master.cryosparc_compute.engine.newengine.process.work
File "cryosparc_master/cryosparc_compute/engine/newengine.py", line 2766, in cryosparc_master.cryosparc_compute.engine.newengine.process.work
File "cryosparc_master/cryosparc_compute/engine/newengine.py", line 1518, in cryosparc_master.cryosparc_compute.engine.newengine.EngineThread.compute_error
ValueError: Detected NaN values in newengine.compute_error. 11294500 NaNs in total, 500 particles with NaNs.
I retry the J39’s cloned job using a subset of 100000 particles from the output of a Particle Sets Tool, but got the same error.
[CPU: 8.17 GB Avail:1009.03 GB]
Traceback (most recent call last):
File “/home/cryosparc_user/cryosparc/cryosparc_worker/cryosparc_compute/jobs/runcommon.py”, line 2294, in run_with_except_hook
run_old(*args, **kw)
File “/home/cryosparc_user/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.10/threading.py”, line 953, in run
self._target(*self._args, **self._kwargs)
File “cryosparc_master/cryosparc_compute/engine/newengine.py”, line 2714, in cryosparc_master.cryosparc_compute.engine.newengine.process.work
File “cryosparc_master/cryosparc_compute/engine/newengine.py”, line 2766, in cryosparc_master.cryosparc_compute.engine.newengine.process.work
File “cryosparc_master/cryosparc_compute/engine/newengine.py”, line 1518, in cryosparc_master.cryosparc_compute.engine.newengine.EngineThread.compute_error
ValueError: Detected NaN values in newengine.compute_error. 11294500 NaNs in total, 500 particles with NaNs.
We are a bit stumped on this one. We thought of one thing worth trying, specifically because this problem only occurs with static masking as you mentioned.
It’s possible that the mask is invalid in some way, e.g. has NaNs, or values outside [0,1], etc.
Could you try using different mask for input, specifically one that has been generated via a different process? You originally used ChimeraX segger, so could you try for example using volume eraser to create a mask base, then import this mask base, and pass it to a volume tools job with appropriate thresholding and:
We are seeing this as well for some local refinement jobs, using a mask created directly using volume tools… and it happens with one set of particles extracted with a certain box size, but not with the same set of particles extracted with a different box size.
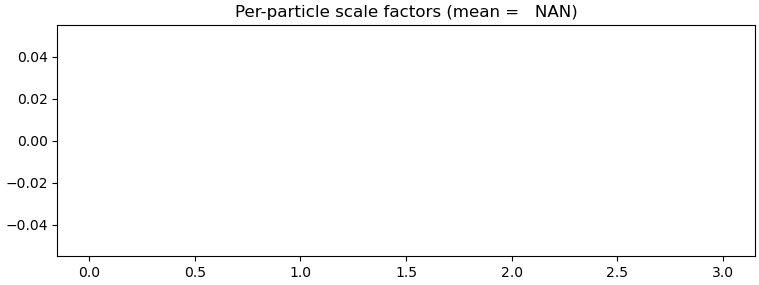
Also, the set of particles that gives this error in local refinement does not give the same error in NU-refine. In our case I think the issue is with refinement of scale factors (for some reason the scale factor refinement in local refinement fails, even when using a global mask, whereas it succeeds in NU-refine) - @LDE, what happens if you switch off “minimize over per-particle scale”? In my case, this fixes the issue.
I also have the same problem in some local refinement jobs, with masks created using volume tools (after segmentation in ChimeraX). The masks are unlikely to be the problem, since local refinement jobs with different particle subsets, but the same mask, sometimes work.
The problem occurs when:
use pose/shift gaussian prior during alignment = TRUE
minimize over per-particle scale = TRUE
The job then runs after either setting minimize over per-particle scale = FALSE or reset input per-particle scale = TRUE
Also, a local refinement on the same particle set with another mask works without problems.
Actually, so far I’ve encountered this problem only with the smallest mask I’m using (encompassing roughly 90 kDa).
I’m experiencing the same error message, and even the numbers are identical in the line “11294500 NaNs in total, 500 particles with NaNs.”
I am also running local refinement with a static mask in CryoSPARC v4.5.3. I played around with different masks, as suggested by others, and sometimes it allowed the job to complete (but sometimes it didn’t). Unlike @LDE, for me the error occurs at seemingly random times throughout the run (could happen a few minutes in or over an hour in). Additionally, I just experienced a situation where I simply cleared the failed run and reran it, and it ran fine. This makes me think the difference in masks was a red herring and that there is a random process at play here. That said, I ran dozens of local refinements yesterday without issue, and the problem only appeared today when I combined a few particle stacks that I’d been working with separately yesterday. Though, again, the problem is irreproducible, so that might also be a red herring.
If anyone has found any tricks to get their runs to complete, please lmk!
A few additional datapoints. Indeed, the particle stack wasn’t the problem. I returned to some of yesterday’s original particle stacks (which didn’t previously generate the error) and have now gotten the error message when running local refinements on those.
The only pattern that has held true for every run so far is that the error does not happen if “Minimize over per-particle scale” is unchecked (in line with @olibclarke’s suggestion).
My approach now is just to restart my local refinement jobs every time they fail. It usually makes it to the end somewhere between the 3rd and 5th try.
UPDATE: nothing seems to fix the current job card including new particle sets/masks/references/parameters, but cloning and rerunning on a new card works fine with any combination.
Hi, this is very helpful as I have got exactly the same error with my local refine jobs on v4.5.3. “ValueError: Detected NaN values in newengine.compute_error. 11294500 NaNs in total, 500 particles with NaNs.”
Cloning and rerunning didn’t work for me, but turning off the “minimise over a per-particle scale” did allow it to run, as long as I kept the per-particle option switched off, keeping gaussian priors on wasn’t a problem for me.
I also have this issue in v4.6. Sometimes the refinement runs normally for 3 or 4 iterations before crashing, sometimes it crashes immediately (even with the same particles). It also says “ValueError: Detected NaN values in newengine.compute_error. 11294500 NaNs in total, 500 particles with NaNs”. Turning gaussian priors on or off has no effect, and neither does minimizing over per particle scales or resetting the input per particle scales. I also ran check for corrupt particles but that doesn’t help either.
Hi, I have encountered the same problem with local refinement and focused mask. Deactivating ‘minimise to scale per particle’ seems to solve the problem, even with * use pose/shift gaussian prior during alignment = TRUE (Cryosparc v4.6.0)
stefano