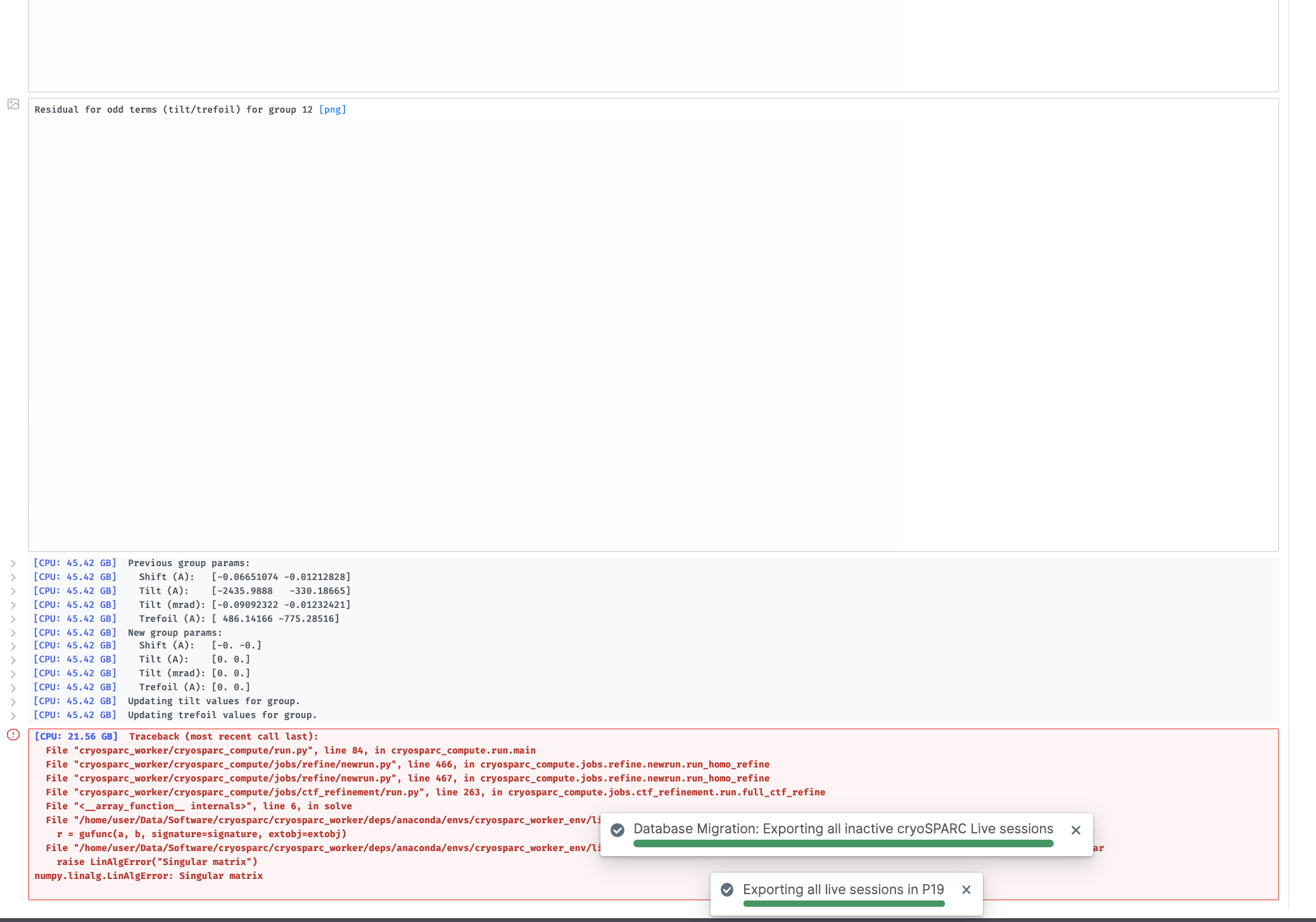
The following error occurred during 3D non-uniform refinement.
Any cure?
Thank you!
Sincerely,
Dmitry
Traceback (most recent call last):
File "cryosparc_worker/cryosparc_compute/run.py", line 84, in cryosparc_compute.run.main
File "cryosparc_worker/cryosparc_compute/jobs/refine/newrun.py", line 466, in cryosparc_compute.jobs.refine.newrun.run_homo_refine
File "cryosparc_worker/cryosparc_compute/jobs/refine/newrun.py", line 467, in cryosparc_compute.jobs.refine.newrun.run_homo_refine
File "cryosparc_worker/cryosparc_compute/jobs/ctf_refinement/run.py", line 263, in cryosparc_compute.jobs.ctf_refinement.run.full_ctf_refine
File "<__array_function__ internals>", line 6, in solve
File "/home/user/Data/Software/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.7/site-packages/numpy/linalg/linalg.py", line 394, in solve
r = gufunc(a, b, signature=signature, extobj=extobj)
File "/home/user/Data/Software/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.7/site-packages/numpy/linalg/linalg.py", line 88, in _raise_linalgerror_singular
raise LinAlgError("Singular matrix")
numpy.linalg.LinAlgError: Singular matrix
Is this the first iteration of CTF Refinement within Non-Uniform Refinement? Did previous iterations of CTF Refinement work?
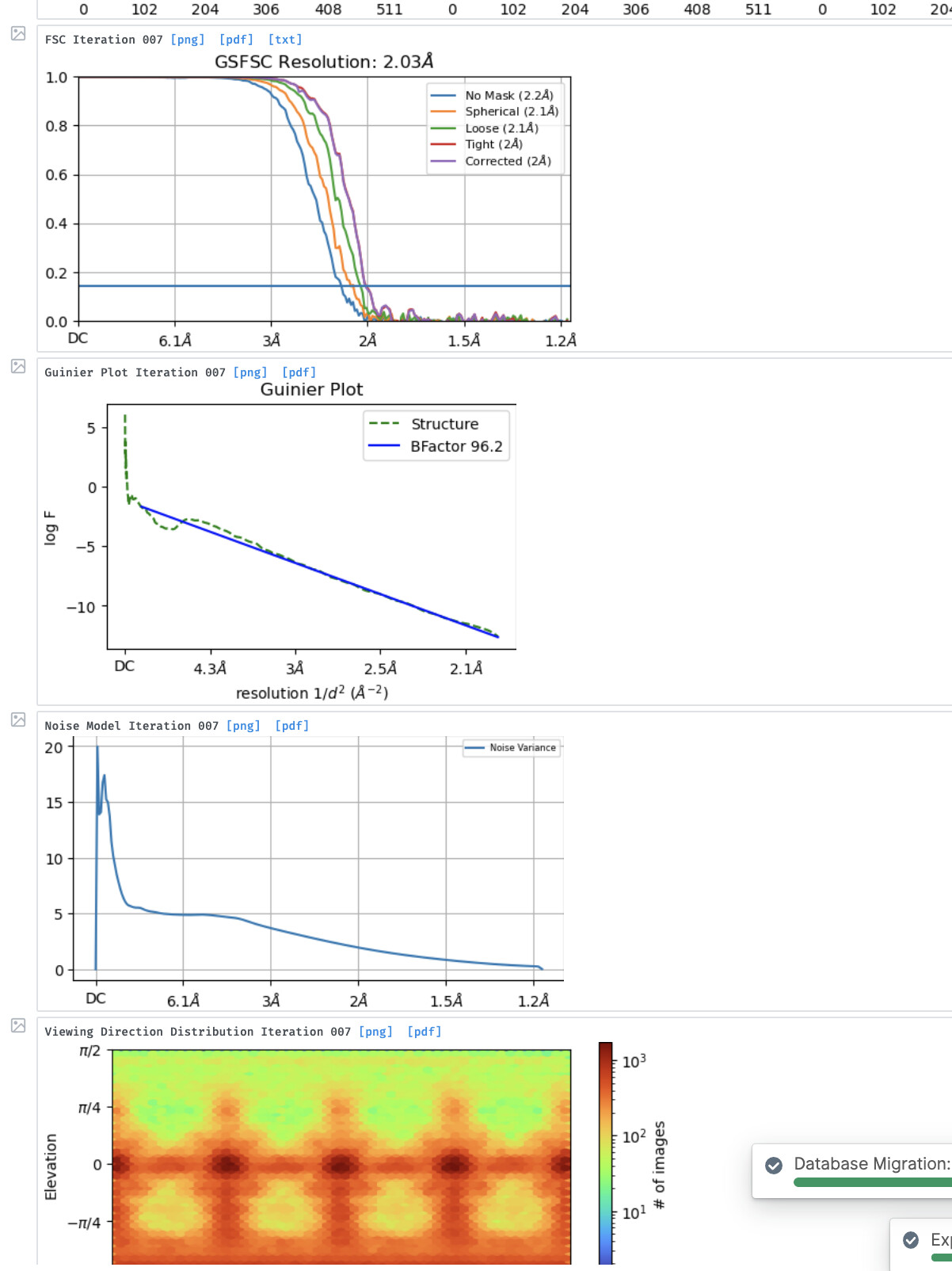
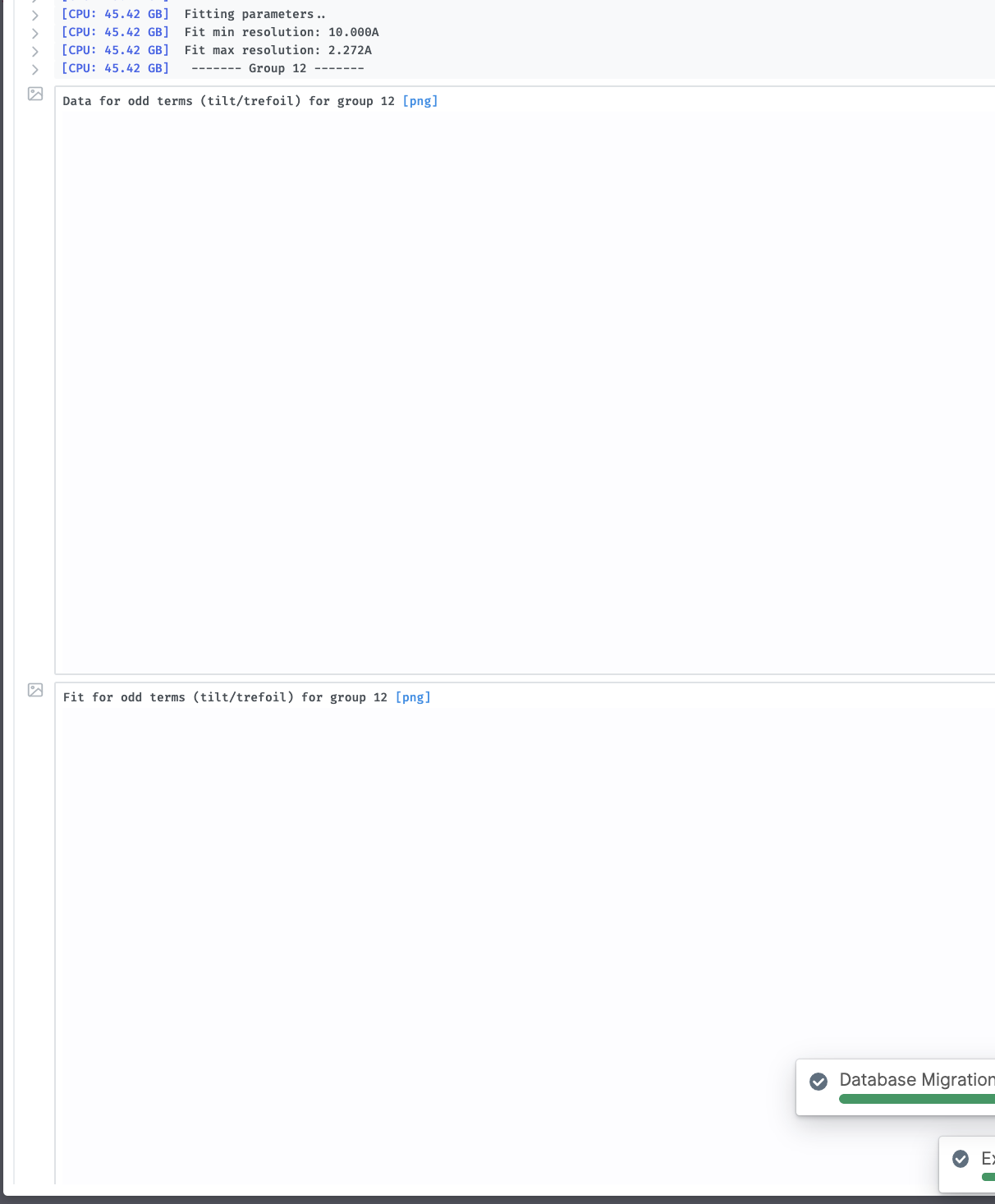
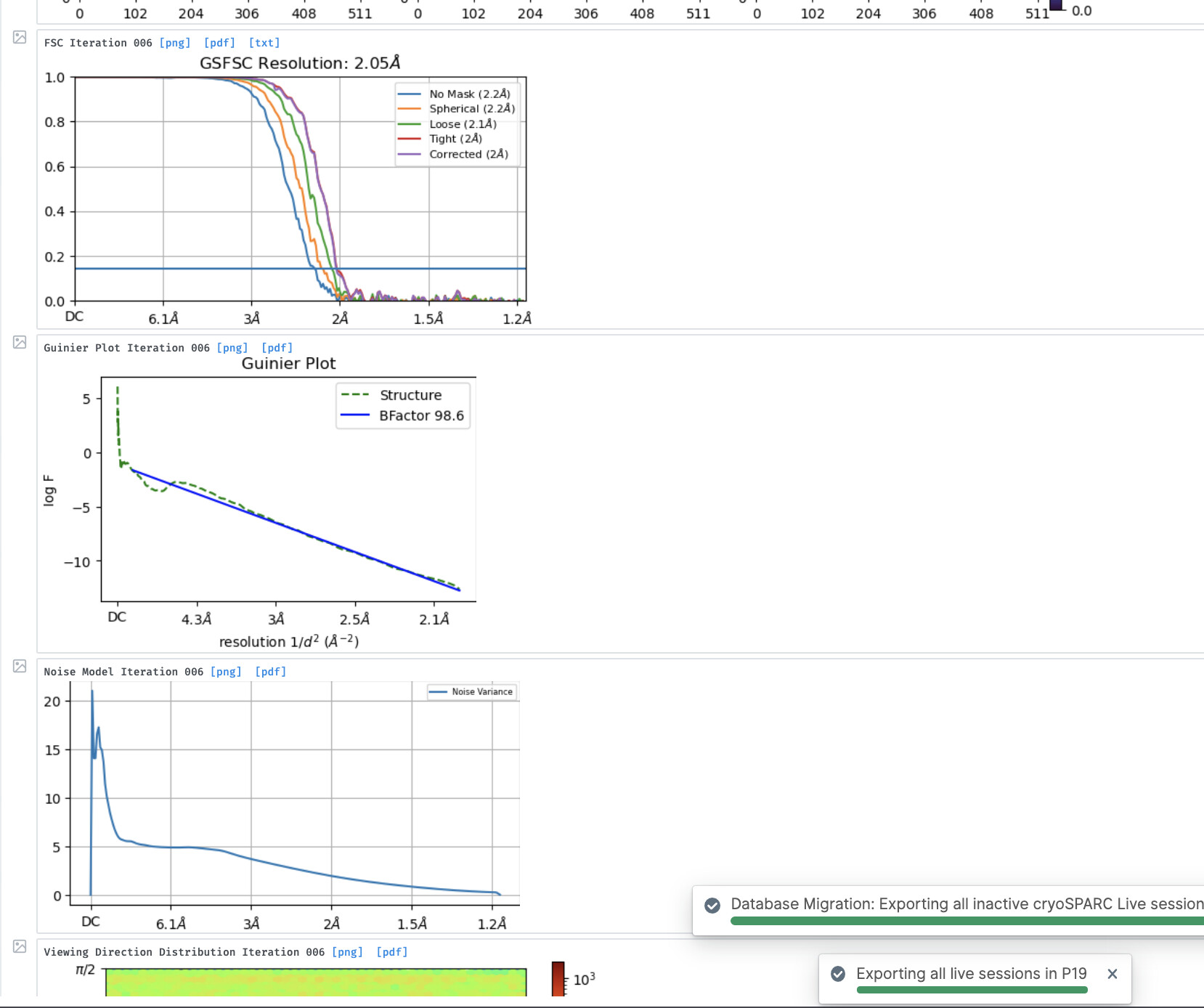
Also, can you please provide any of the CTF Refinement plots that were outputted before this error? You can send screenshots or copy+paste.
Sorry for the late response. Did you specify any parameters for this job? If so, what are they?
Also, can you navigate to the job’s “Metadata” tab and click on the “Copy to Clipboard” button, then send me that? It will allow me to see what specific GPU and CUDA version this job ran with.
Also, can you try running this same job with half the particles? You can use the Particle Sets Tool to split the particle dataset in half before connecting an output to another Non-uniform Refinement job.
Hello @Stephan. Yes, I will try to send the files later. The issue is that the program worked with the box size 384x384, but the same data with the box size 512x512 led to a crash. And according to what we see - at the last iteration. So I suppose that can be an issue of memory. In that case, I would like to ask what the solution exists?
I’m getting the same error for NU Ref New with optimize per-group CTF and optimize per-particle defocus and also getting the error for CTF refine global (only parameter change = 3 iterations).
The particle input for both of these jobs is Exposure Group Utilities using split by blob/path to make each micrograph its own group.
NU ref has previously run successfully with nearly the same settings, except all particles were in one group. It’s about 600k particles from 5k micrographs at box 400 with C5 symmetry.
I’m on v3.3.1+221214 with CUDA 11.2.0. NU ref has previously failed because out of memory but simply cloning and restarting the job was successful, which is kind of weird. I can send over some metadata if that is helpful.
computer cluster 4xGPU node of 20 CPU, memory of 256G
“UnboundLocalError: local variable ‘uid’ referenced before assignment”
i. action=split, start index=41, # character to consider=8, index position=back
ii. lowpass=12A, minimize per-particle scale, optimize per-particle defocu, Fit A-mag