Our projects are all stored on servers, attached with NFS. Should I also monitor network usage, additionally to memory usage? I think I can easily extend my script for the logging.
Update:
It seems like the memory leak is coming from a function that tries to update the sizes of all jobs in the instance. This job looks at every job’s output result groups, loads in each dataset (.cs) file to find its associated files, and finds the sizes of those files. It turns out that there is a bug in our dataset implementation that doesn’t allow the Python garbage collector to clean itself up, causing the memory leak when the size update function loads in the dataset.
We’re releasing a patch that will (hopefully) fix the memory leak soon, would you both (@ctueting and @ebirn, and anyone else, DM me) be willing to run this patch to see if the memory leak goes away?
This size update function happens when you run cryosparcm start. You should be able to avoid the memory leak now if you do the following:
cryosparcm stop
cryosparcm start
cryosparcm restart command_core
Calling cryosparcm restart command_core kills the job size update function that runs when you call cryosparcm start.
2 Likes
Sure, we’re we can deploy a patch when you have it ready.
In case this is still relevant: yes, the projects are located on NFS, a shared filesystem between cryosparc, the cluster, and workstations.
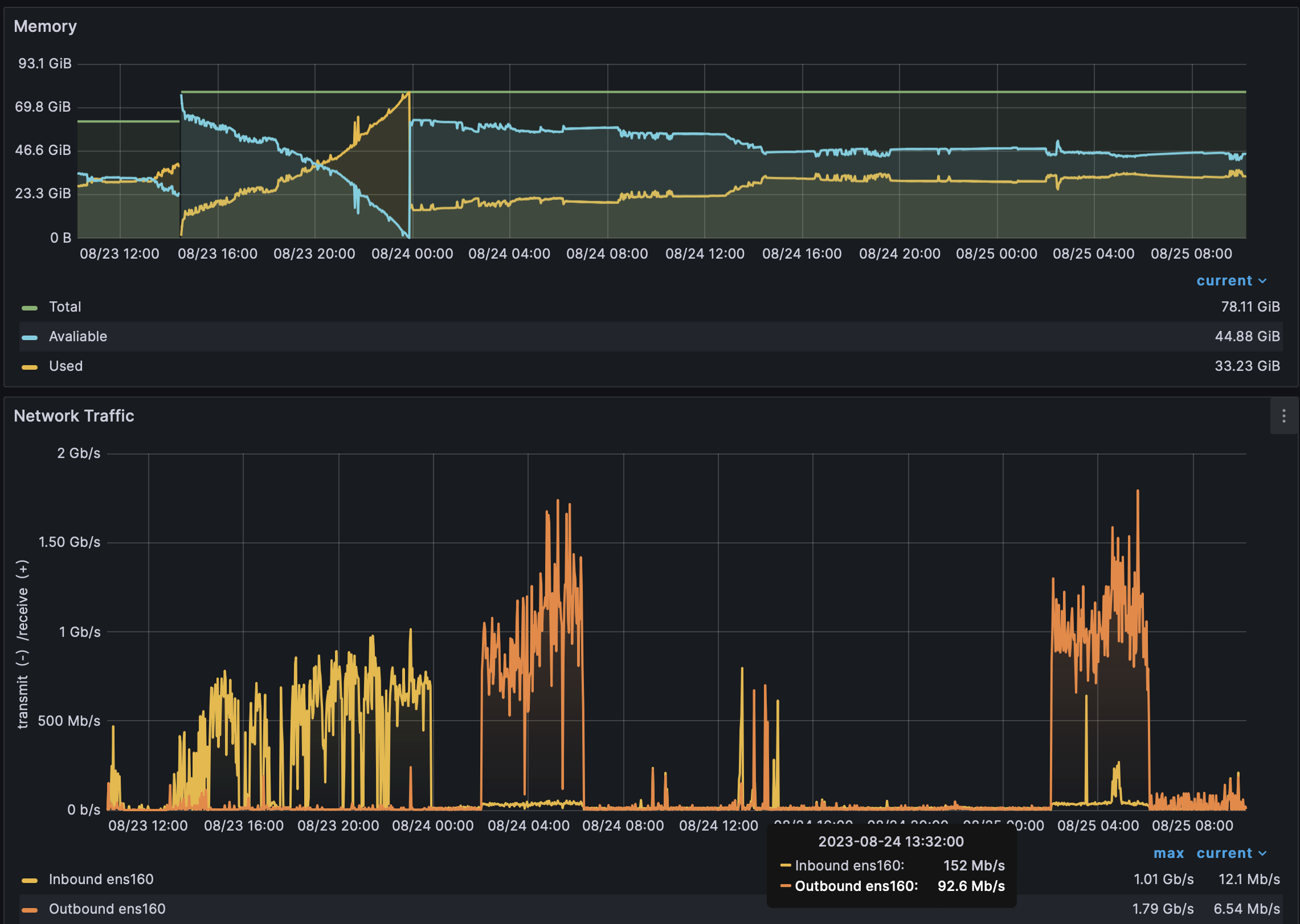
This is what our traffic looks like. the outbound traffic 02:00-06:00 is the backup written.
Note the inbound traffic on 08/23 up to OOM, and then only slight increase, yesterday 08/24 12:00 correlates with an increase in memory usage at the same time.
The command_core mitigation will be effective if done right after initial start of the application, oder also later on, when we see memory increasing?
Let me know, if we can provide anything else.
Wow that debugging was fast.
Of course we can test the patch.
Currently, our users queued some heavy jobs, I would like to finish. As soon as they are done, I will try the workaround and patch our instance.
Thanks for the additional memory trace.
It will be effective in both scenarios- again, the command to run is cryosparcm restart command_core.
DM sent, thank you! Looking forward to hearing if this fixes the problem for you.
@ctueting @ebirn CryoSPARC v4.3.1 fixes the command_core memory leak.
2 Likes
Hi,
We’ve deployed 3.4.1 in production on Monday, and we’ve not encountered any memory issues up to this point. At the moment it appears that memory usage has gone down in general for the master processes.
4 Likes
Since the deployment of the new update, GUI performance has been stellar.
4 Likes
A post was split to a new topic: Gunicorn memory use