Hi All,
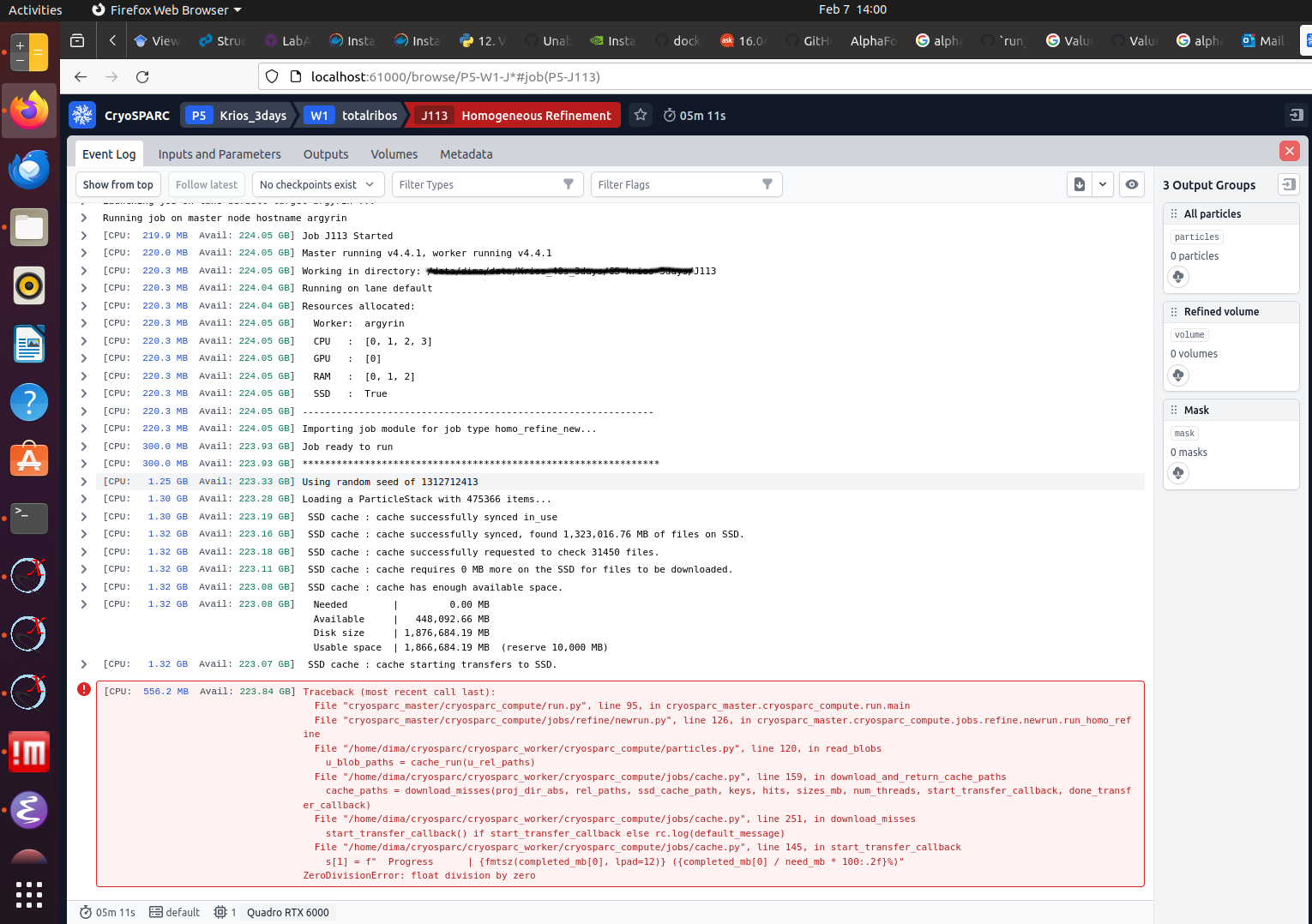
I am encountering crash while starting homogeneous refinement with default parameters on combined two set of polished 1x binned particles, each coming from separate set of motion corrected images. Is it a known limitation or I’m hitting hard limits on RAM (250G) or VRAM (28G)? Thank you for your comments! Screenshot of log file is attached.
P.S. Merging into single stack with “remove duplicate particles” doesn’t resolve the issue. Reducing alignment resolution to 6A doesn’t resolve the issue. Setting GPU batch size of images to 50k doesn’t resolve the issue.
cryosparcm cli “get_scheduler_targets()”
[{‘cache_path’: ‘/media/dima/scratch/cryosparc_cache’, ‘cache_quota_mb’: None, ‘cache_reserve_mb’: 10000, ‘desc’: None, ‘gpus’: [{‘id’: 0, ‘mem’: 25388515328, ‘name’: ‘Quadro RTX 6000’}, {‘id’: 1, ‘mem’: 25388515328, ‘name’: ‘Quadro RTX 6000’}, {‘id’: 2, ‘mem’: 25385631744, ‘name’: ‘Quadro RTX 6000’}, {‘id’: 3, ‘mem’: 25388515328, ‘name’: ‘Quadro RTX 6000’}], ‘hostname’: ‘argyrin’, ‘lane’: ‘default’, ‘monitor_port’: None, ‘name’: ‘argyrin’, ‘resource_fixed’: {‘SSD’: True}, ‘resource_slots’: {‘CPU’: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127], ‘GPU’: [0, 1, 2, 3], ‘RAM’: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31]}, ‘ssh_str’: ‘dima@argyrin’, ‘title’: ‘Worker node argyrin’, ‘type’: ‘node’, ‘worker_bin_path’: ‘/home/dima/cryosparc/cryosparc_worker/bin/cryosparcw’}]