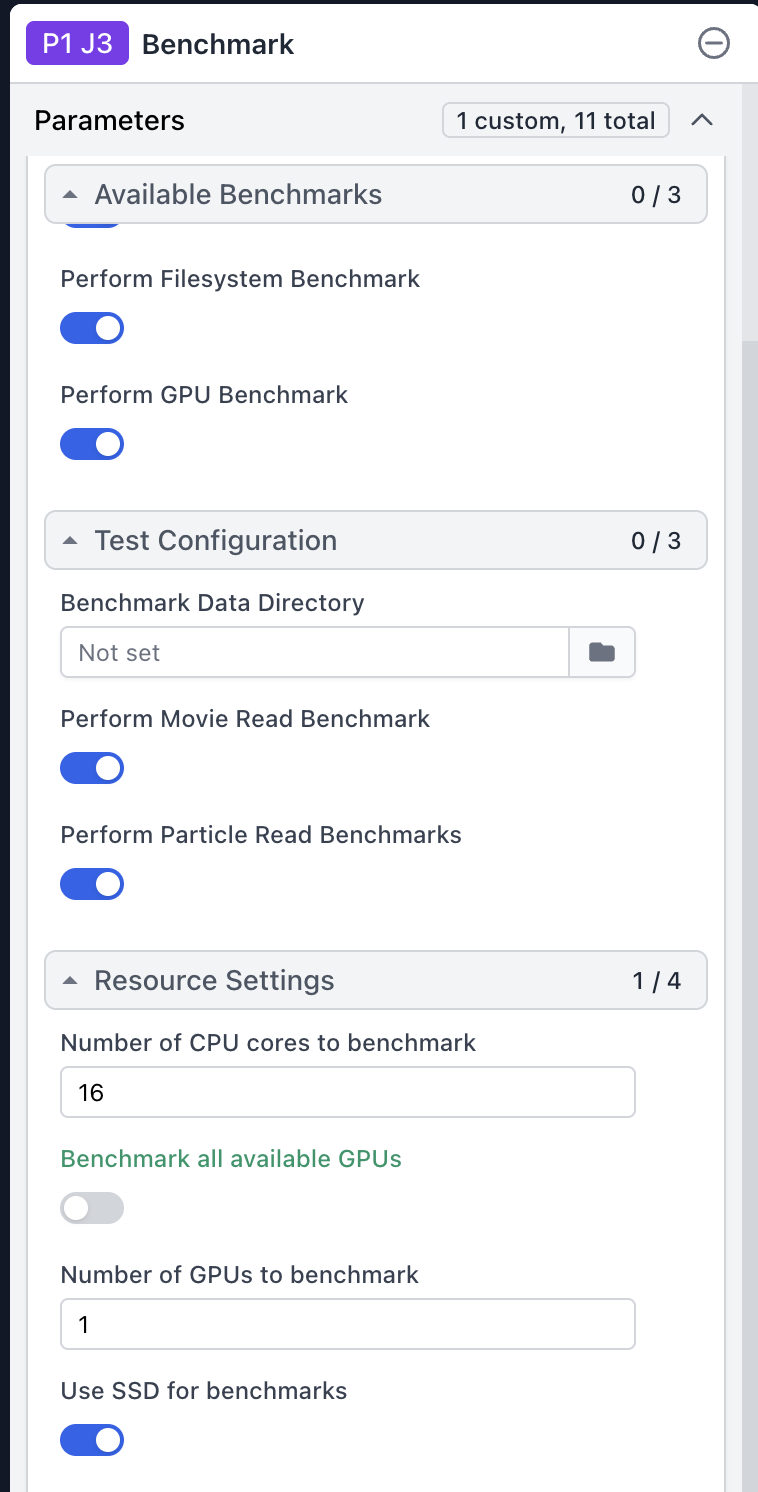
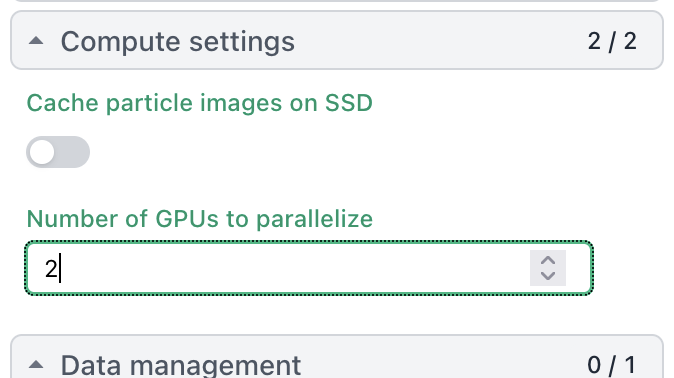
[{‘cache_path’: ‘/home/tom/scratch/’, ‘cache_quota_mb’: None, ‘cache_reserve_mb’: 10000, ‘desc’: None, ‘gpus’: [{‘id’: 0, ‘mem’: 33645461504, ‘name’: ‘NVIDIA GeForce RTX 5090’}, {‘id’: 1, ‘mem’: 33668988928, ‘name’: ‘NVIDIA GeForce RTX 5090’}], ‘hostname’: ‘tom-TRX50-AI-TOP’, ‘lane’: ‘default’, ‘monitor_port’: None, ‘name’: ‘tom-TRX50-AI-TOP’, ‘resource_fixed’: {‘SSD’: True}, ‘resource_slots’: {‘CPU’: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47], ‘GPU’: [0, 1], ‘RAM’: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]}, ‘ssh_str’: ‘tom@tom-TRX50-AI-TOP’, ‘title’: ‘Worker node tom-TRX50-AI-TOP’, ‘type’: ‘node’, ‘worker_bin_path’: ‘/home/tom/bin/cryosparc_worker/bin/cryosparcw’}]