I am trying to run a new refinement job but it crashed after 4 iterations with the following error:
[CPU: 8.20 GB] Done iteration 4 in 4536.317s. Total time so far 6047.211s
[CPU: 8.20 GB] ----------------------------- Start Iteration 5
[CPU: 8.20 GB] Using Max Alignment Radius 92.933 (3.230A)
[CPU: 8.20 GB] Using Full Dataset (split 594419 in A, 594418 in B)
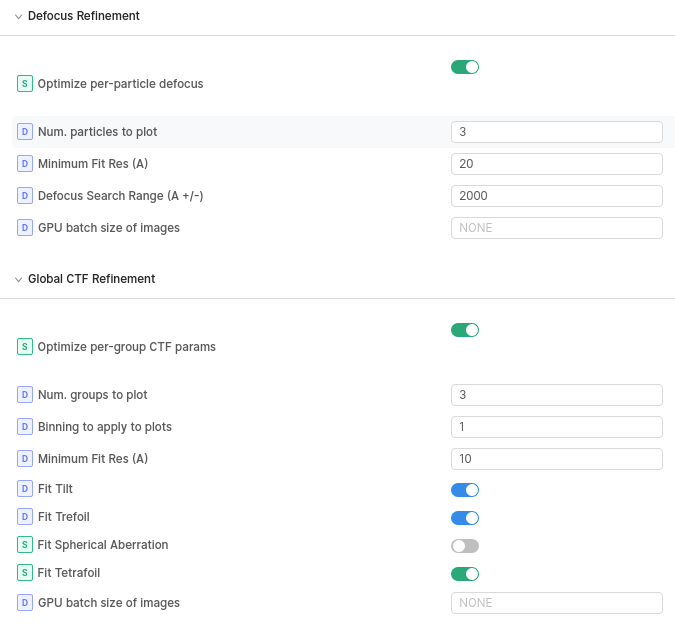
[CPU: 8.36 GB] Performing defocus refinement against current half-map references.
[CPU: 8.36 GB] Minimum resolution: 20.00A Maximum resolution 3.60A
[CPU: 8.20 GB] GPU batch size auto-fit is -122
[CPU: 8.20 GB] Starting particle processing for split A..
[CPU: 8.20 GB] Starting..
[CPU: 5.44 GB] Traceback (most recent call last):
File "cryosparc2_worker/cryosparc2_compute/run.py", line 78, in cryosparc2_compute.run.main
File "cryosparc2_worker/cryosparc2_compute/jobs/refine/newrun.py", line 401, in cryosparc2_compute.jobs.refine.newrun.run_homo_refine
File "cryosparc2_worker/cryosparc2_compute/jobs/refine/newrun.py", line 402, in cryosparc2_compute.jobs.refine.newrun.run_homo_refine
File "cryosparc2_worker/cryosparc2_compute/jobs/ctf_refinement/run_local.py", line 180, in cryosparc2_compute.jobs.ctf_refinement.run_local.full_defocus_refine
File "cryosparc2_worker/cryosparc2_compute/jobs/ctf_refinement/run_local.py", line 362, in cryosparc2_compute.jobs.ctf_refinement.run_local.do_defocus_refine
UnboundLocalError: local variable 'first_batch_df_vals' referenced before assignment
What GPU are you running on, and what was the box size of the particles/refinement?
The problem is actually here: GPU batch size auto-fit is -122
This means that the code tried to fit as many particles as possible on to the GPU, but there isn’t enough memory so it thinkings -122 particles will fit… which is a problem! We have to add a check for this scenario.
For now, to try and override this and see if it will still work, set the GPU batch size of images to a small number like 10 or 50, and see if the job runs without crashing.
My boxsize for refinement is 280. With the same number of particles, the normal refine job finished successfully but the new refinement job failed. Below is the list of GPUs that we have in our lab. We are using a job distribution system but the log file was lost so I don’t know which GPU that particular job was running on. It should be one of them: