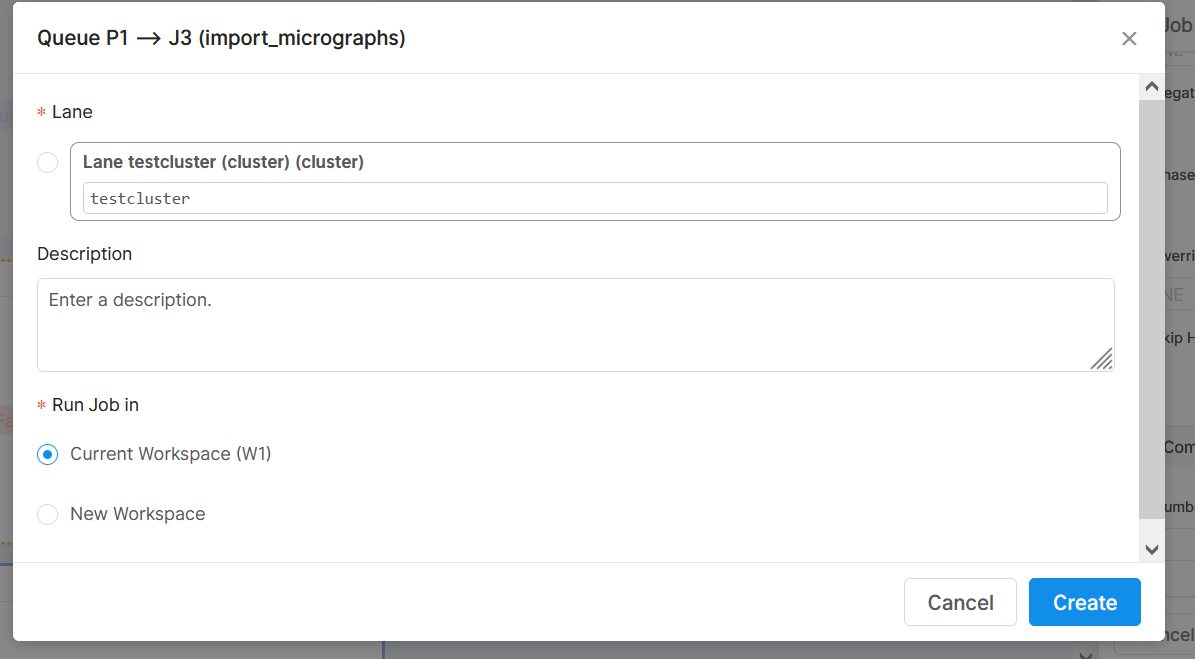
I have installed cryosparc v3.3.2 and added the new cluster lane. I am unable to see the queue in the gui and I can only submit the jobs to default queue to the master node. I can see the clusterlane in resource manager but not during job submission
I had no issues in the previous version v2.15. Any directions will be helpful.
Welcome to the forum @asif.
Please can you post the outputs of these commands: cryosparcm cli "get_scheduler_lanes()"
and cryosparcm cli "get_scheduler_targets()".
[{‘cache_path’: ‘/scratch/{USER}/', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'desc': None, 'hostname': 'testcluster', 'lane': 'testcluster', 'name': 'testcluster', 'qdel_cmd_tpl': '/usr/bin/scancel {{ cluster_job_id }}', 'qinfo_cmd_tpl': '/usr/bin/sinfo', 'qstat_cmd_tpl': '/usr/bin/squeue -j {{ cluster_job_id }}', 'qsub_cmd_tpl': '/usr/bin/sbatch {{ script_path_abs }}', 'script_tpl': '#!/usr/bin/env bash\n#### cryoSPARC cluster submission script template for SLURM\n## Available variables:\n## {{ run_cmd }} - the complete command string to run the job\n## {{ num_cpu }} - the number of CPUs needed\n## {{ num_gpu }} - the number of GPUs needed. \n## Note: the code will use this many GPUs starting from dev id 0\n## the cluster scheduler or this script have the responsibility\n## of setting CUDA_VISIBLE_DEVICES so that the job code ends up\n## using the correct cluster-allocated GPUs.\n## {{ ram_gb }} - the amount of RAM needed in GB\n## {{ job_dir_abs }} - absolute path to the job directory\n## {{ project_dir_abs }} - absolute path to the project dir\n## {{ job_log_path_abs }} - absolute path to the log file for the job\n## {{ worker_bin_path }} - absolute path to the cryosparc worker command\n## {{ run_args }} - arguments to be passed to cryosparcw run\n## {{ project_uid }} - uid of the project\n## {{ job_uid }} - uid of the job\n## {{ job_creator }} - name of the user that created the job (may contain spaces)\n## {{ cryosparc_username }} - cryosparc username of the user that created the job (usually an email)\n##\n## What follows is a simple SLURM script:\n\n#SBATCH --job-name cryosparc_{{ project_uid }}_{{ job_uid }}\n#SBATCH -c 4 \n#SBATCH --gres=gpu:1\n#SBATCH -p Gpu \n#SBATCH --mem=10G \n##SBATCH -o {{ job_dir_abs }}\n##SBATCH -e {{ job_dir_abs }}\n\n\navailable_devs=""\nfor devidx in (seq 0 15);\ndo\n if [[ -z $(nvidia-smi -i $devidx --query-compute-apps=pid --format=csv,noheader) ]] ; then\n if [[ -z “$available_devs” ]] ; then\n available_devs=$devidx\n else\n available_devs=$available_devs,$devidx\n fi\n fi\ndone\nexport CUDA_VISIBLE_DEVICES=$available_devs\n\n{{ run_cmd }} | egrep -o '[0-9]+'\n’, ‘send_cmd_tpl’: ‘{{ command }}’, ‘title’: ‘testcluster’, ‘type’: ‘cluster’, ‘worker_bin_path’: ‘/storage/hpc/data/amq7y/cryosparc_3.3.2/cryosparc_worker/bin/cryosparcw’}]
Let me know if you want me to attach the results for the command.
Hi @asif I wonder if a downstream job (after import) would offer the cluster as a queuing target. Import jobs may not offer queuing to the cluster unless export CRYOSPARC_DISABLE_IMPORT_ON_MASTER=true
is included in cryosparc_master/config.sh (guide).
The default of this variable is false; a change in the value must be followed by cryosparcm restart.