Hi,
We have trouble running larger dataset for 2D classification job on the master node of VM for out of memory issue. Is there a way to run submit the job to worker nodes(compute nodes).
Thanks,
Asif.
Hi,
We have trouble running larger dataset for 2D classification job on the master node of VM for out of memory issue. Is there a way to run submit the job to worker nodes(compute nodes).
Thanks,
Asif.
If your CryoSPARC instance is of type Master-Worker or Cluster, you should queue the job to an appropriate compute/worker resource.
If you are managing your own CryoSPARC instance and appropriate worker resources have not yet been configured, please review the installation section of the guide.
Hi wtempel,
I do get options for other job types to run on different lanes which we created as scripts, but this step 2D classification does not allow me to choose any lanes.
Our set up is,
Thanks,
Asif.
Please confirm that you are not trying to submit a Select 2D job, which is supposed to run on the master host and then post
screenshots of your GUI
the output of the command
cryosparcm cli "get_scheduler_targets()"
Hi wtempel,
I am Asif’s colleague in this case. It is the Select 2D job type that always failed, not 2D classification. When I run a Select 2D job, most of times, I don’t see the lane options, sometimes, I do see them. But no matter what lane I choose, it always runs on master node. Our settings are described by Asif above. I attached a failed job log here for you.
Another observation is Inspect Particle Picks job also fails sometimes, which is also run on master node. I suspect it is because the input is too big and the memory may not be enough for master node.
Any diagnosis is much appreciated.
BG
Here is another failed submission showing no lane is selected and it still failed. Note the last screenshot I attached shows it is running on a specific lane I chose (Foundry Cluster).
Certain Interactive jobs are designed to be run on the master node. The master node needs to have sufficient memory to handle the combined requirements of concurrently running interactive CryoSPARC jobs and any other workloads.
@BryanG Please can you post the job log (accessible via Metadata|Log) for the terminated Select 2D job.
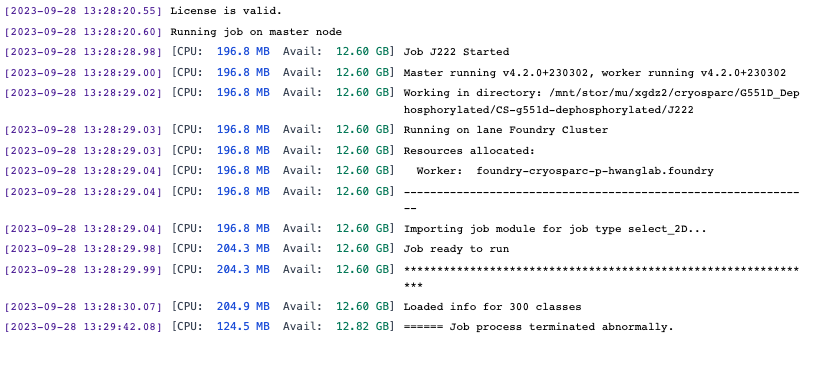
Hi wtempel,
Here it is,
================= CRYOSPARCW ======= 2023-09-28 13:28:22.417424 =========
Project P9 Job J222
Master foundry-cryosparc-p-hwanglab.foundry Port 39002
===========================================================================
========= monitor process now starting main process at 2023-09-28 13:28:22.417479
MAINPROCESS PID 28810
========= monitor process now waiting for main process
MAIN PID 28810
interactive.run_select2D cryosparc_compute.jobs.jobregister
INTERACTIVE JOB STARTED === 2023-09-28 13:28:30.050148 ==========================
========= sending heartbeat at 2023-09-28 13:28:38.990009
========= sending heartbeat at 2023-09-28 13:28:49.000186
========= sending heartbeat at 2023-09-28 13:28:59.020130
========= sending heartbeat at 2023-09-28 13:29:09.034087
========= sending heartbeat at 2023-09-28 13:29:19.052409
========= sending heartbeat at 2023-09-28 13:29:30.097406
========= main process now complete at 2023-09-28 13:29:42.000999.
========= monitor process now complete at 2023-09-28 13:29:42.084525.
Thanks.
Bryan
Thanks @BryanG.
I learned that older CryoSPARC versions, it may have appeared as if it were possible to queue an interactive job on a worker lane. This bug was fixed in CryoSPARC v3 v4.3.
This is from v4. Sometimes I see the lane options for those interactive jobs, including 2D select, or inspect particle pickings, sometimes I don’t…
Thanks,
Bryan
Sorry, I made a typo; meant to write CryoSPARC v4.3.