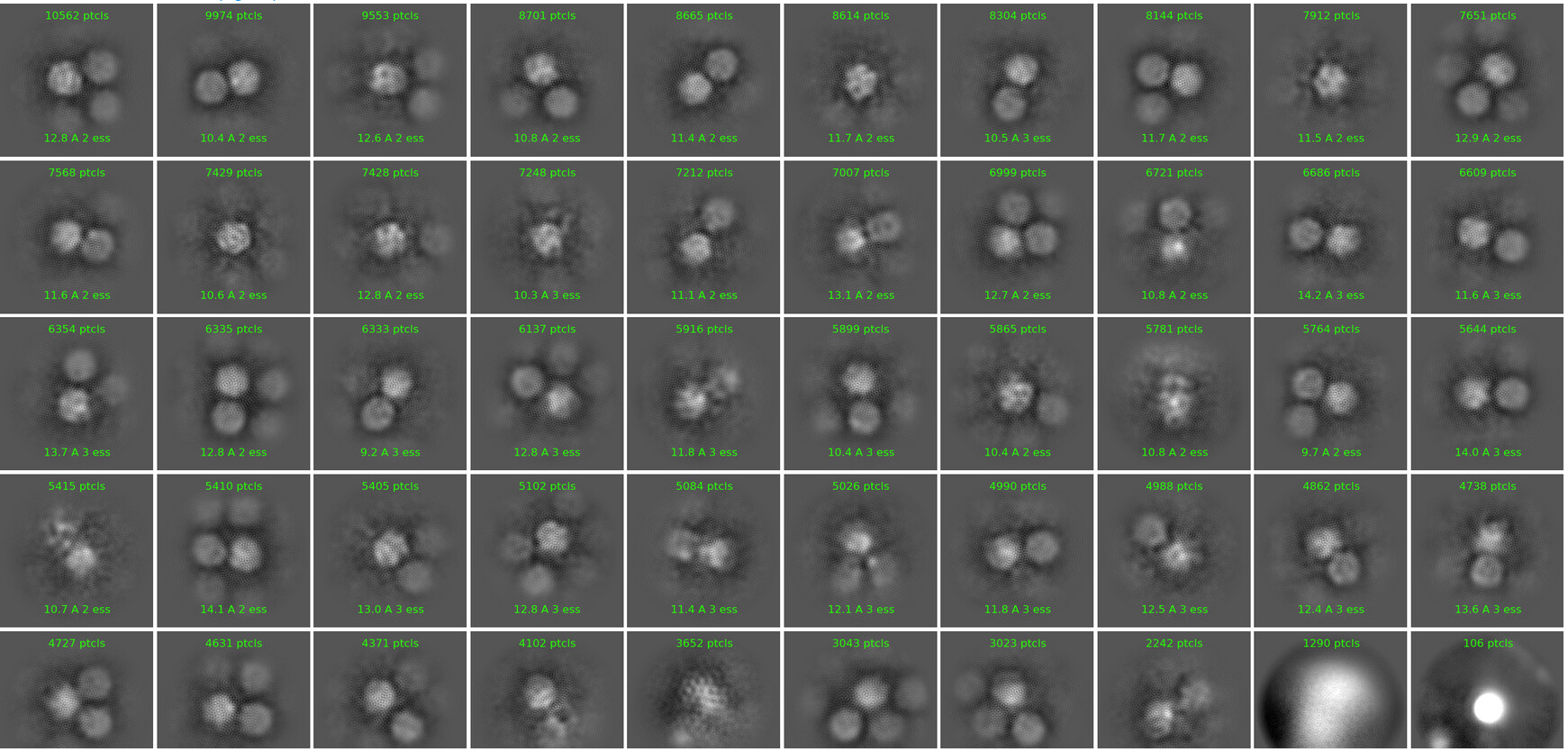
Dear All,
Allow me to start a new topic since it’s a bit different. I ran into the streaky 2D issue with one small protein sample. Particle size 65A, pixel size 0.671, boxsize 384->192, defocus 0.4 to 2 um.
I have tried
Force Max over poses/shifts ON, EM-iteration 20 and Batchsize per class 200. I got streaky classes.
Force Max over poses/shifts OFF, EM-iteration 20 and Batchsize per class 200. I got smooth spheres with no feature.
Anything wrong? Your suggestion are much appreciated.
I fall back to Force Max over poses/shifts ON, tighten the mask, increase full iteration to 20, EM 40. The results somewhat improved, but majority of classes still shown streaky feature.
My question is how come many pointed out that Force Max over poses/shifts OFF plays significant role in 2D classification for small proteins. Why I got smooth balls in the end? How can I further improve the quality of 2D classification and get rid of the streaky features? Is it due to wrong CTF or CTF dislocation, given the big enough boxes size?
Hi jamon - the picture you posted with force/max off is from iteration 8 - how did it look after the full run? And what initial classification uncertainty factor are you using?
Hi,
I have found that using Force Max over poses/shifts OFF is very useful but you should definitely increase the number of EM-iterations to avoid the sphere issue you are getting. At least for me that solves the problem, try at least 40 iterations (I have even used 60) and hopefully, they will end up aligning.
Good luck!
Hello! Very interesting post. Jamon, have you applied a high pass filter (40 - 80 A)? With such a small particle, it must be hard to get the ice thin enough… By using the Manual Curation in CS, can you tell if the ice thickness defines good and bad classes?
In my case, using a tight box during extraction worked better than having a large box with a tight mask, but 1) I am a beginner so I am probably doing something wrong; 2) my particles are elongated, not globular like yours.
Thanks for all the inputs. I did test several rounds and let the previous job (2) running for a while with Force Max over poses/shifts OFF, EM-iteration 20 and Batchsize per class 200. It was obvious that stuck in some local minimal
I test again yesterday with your suggestions Force Max over poses/shifts OFF, EM-iteration 40 and Batchsize per class 400. The situation imporved a lot which surprised me since I have used similar parameters before. Not sure where went wrong.
Hi @jamon, indeed as @olibclarke mentioned, turning off Force-max can make a substantial difference especially after more iterations with a larger batch. All these changes make the algorithm slower.
We are working on improving the tuning of 2D classification so that the job can figure out the right strategy on it’s own, but it is quite difficult to determine the best parameters from the data without running for many iterations.
There are several factors that affect what will happen early on in 2D classification and whether or not the algorithm can converge immediately or will first move towards spheres and then slowly converge from there. The main considerations are the the overall SNR, the alignable features present in the data, and the type/statistics of the noise in the data (Gaussian shot noise, structured noise, contaminants/denatured protein at the air-water interface, etc). It’s quite difficult to tune smartly around all these.