I would appreciate your advice regarding a membrane protein dataset.
I purified my membrane protein in 0.00015% LMNG and 0.0003% CHS. The protein concentration is 8.5 mg/mL. The protein assembles as a dimer (~86 kDa), and the estimated molecular weight including the detergent micelle is ~150 kDa.
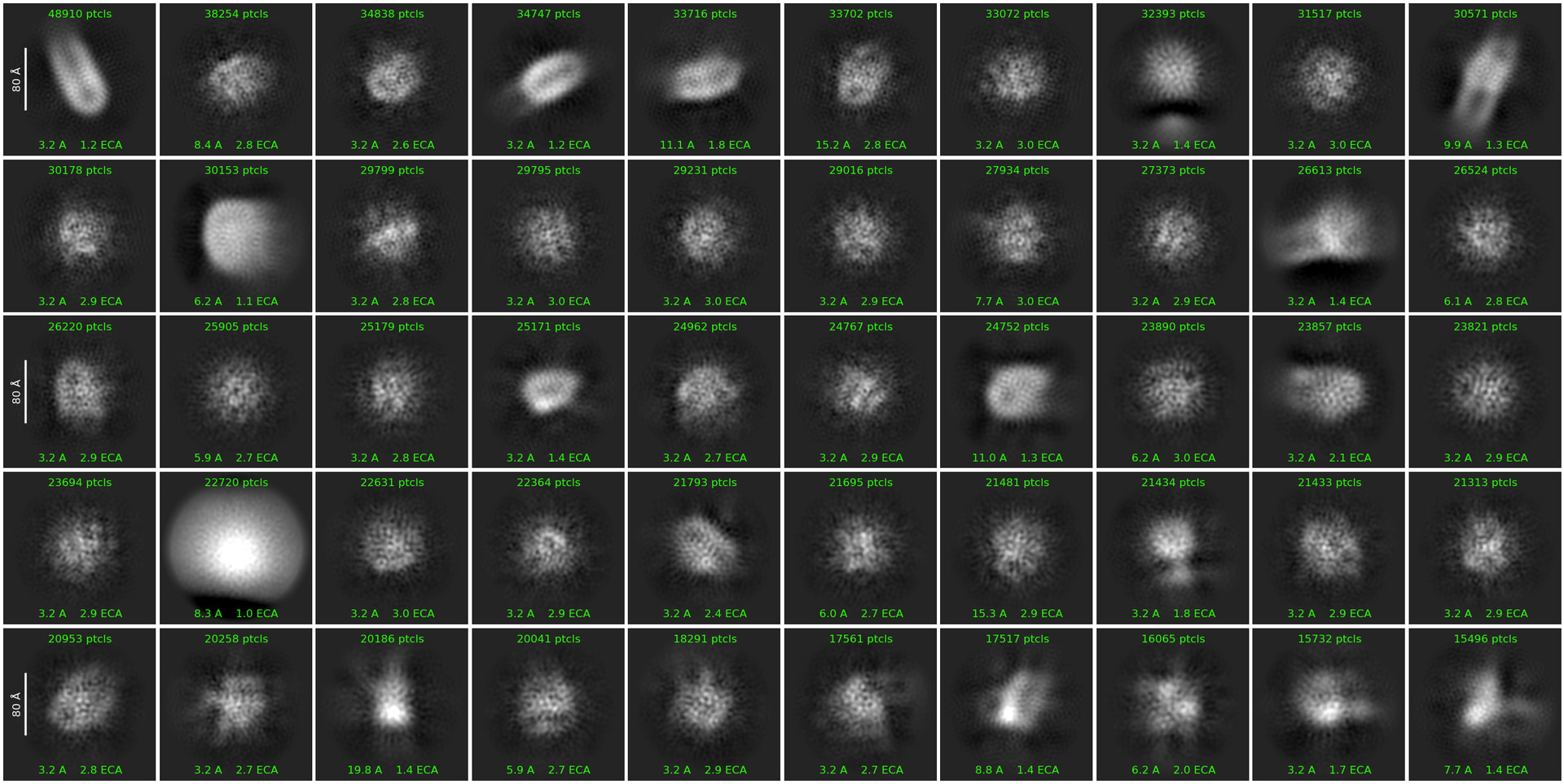
I collected ~2000 micrographs on a Talos Arctica (200 kV) at 92k magnification, with a total electron dose of 40 e⁻/Ų. I performed 2D classification and homogeneous refinement with C2 symmetry applied.
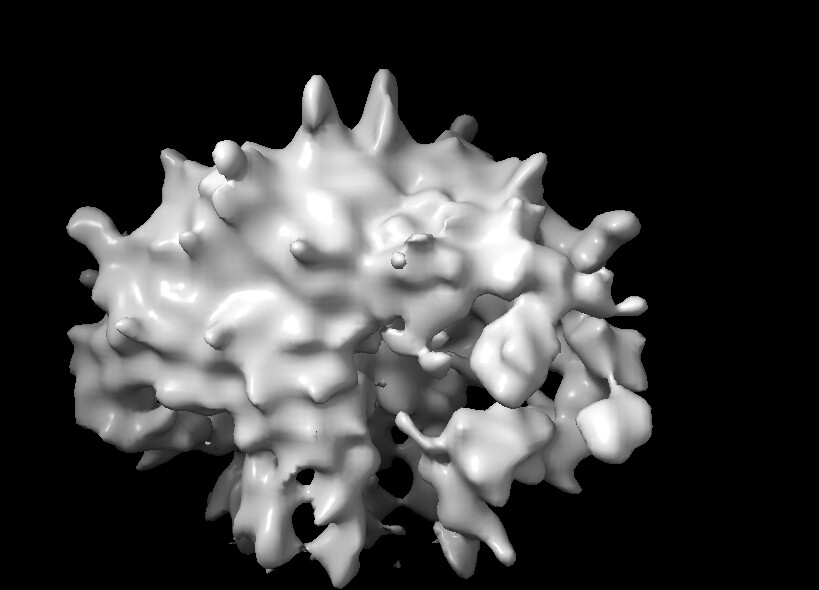
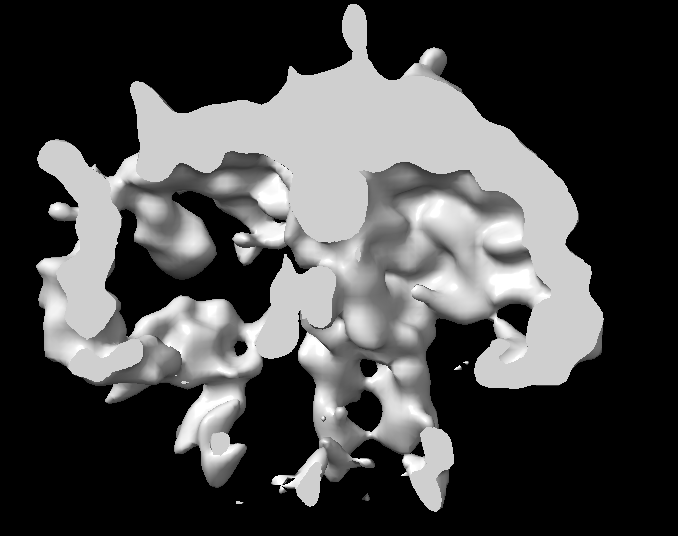
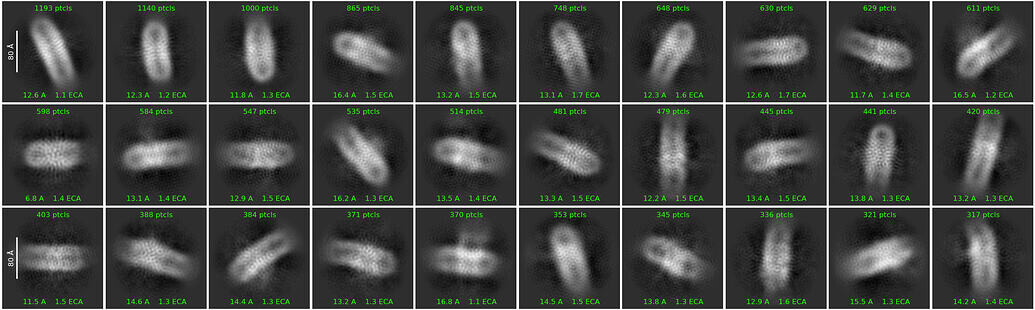
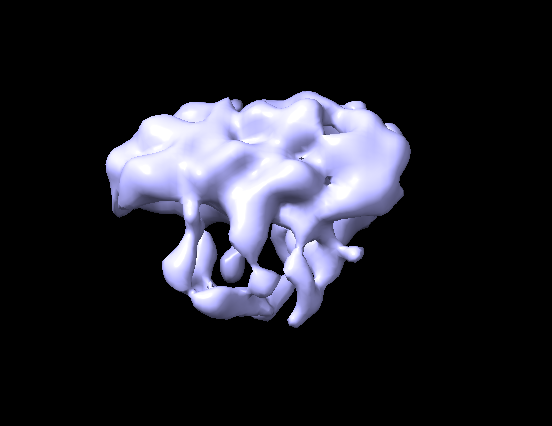
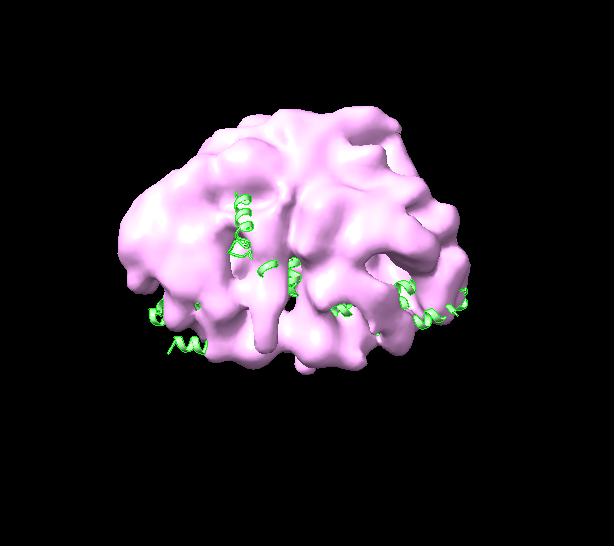
The issue is that I do not observe clearly resolved transmembrane helices in the 2D classes. The homogeneous refinement produces a density map that resembles the overall protein shape, but the transmembrane helices are not resolved well enough to justify moving to data collection on a Krios.
Could you please advise whether there are data processing strategies that might improve the quality of the 2D classes or the reconstructed map, or whether this is more likely a sample-related limitation?
Have you confirmed the detergent concentration is above CMC for the buffer? Just asking as listed is a few fold lower than LMNG water CMC. LMNG does have general slow offrate compared to some others detergents.
Judging from 2D getting maybe 1/4 to 1/5 particles from first round of 2d classification, this isn’t a high percent so can improve picking process. Can you share a good looking high/low defocus micrograph with your current good particles for the 3d refinement identified (manual picker or inspect particle pick job), is the ice nice and super thin for these small particles? Tried the AI pickers? Increase the extraction box sizeto 1.5X or 2X current and repeat, judging from good 2D particles the box is too small.
2D classification, you ran small particle job so that helps, increase the classes from 50 to 200, with the number of bad particles increase the iterations from the 80 to 200, have more random junk and less desired particles makes it harder to classify. This job will take a while to run but you can check the iterations as its going to see if its improving. I’ve gone up to 500 iterations and you can see improvement in the 2d classes at the cost of losing more good particles.
Your second round of 2d classification i’m only seeing side views, no top views or tilted. Side views always the easiest to pick as you get the contrast from the whole detergent belt. This goes back to the micrographs, do you have the contrast to see top/bottom views? The size of the belt suggest the 30,153 particles 2D group may have some top views but not seeing any in this second round of 2d. Top views can be harder, the belt isn’t always perfectly circular and can be odd shaped making it harder to align them up.
3D, Does C1 look similar to C2? How did the heterogenous refinement looks? From your current 3d model take that along with some other junk 3d volumes (3-9 junk volumes) from ab initio and put the whole 1 million initial particles through heterogenous refinement, a straight to 3D job. This is where i often observed the best improvement and hopefully get more particles then current amount from 2D.
Usual checkups at each stage: look at the 2d/3d accepted/reject particles on the micrographs, does it look like your throwing away good particles?
These don’t look all that bad after the second round of 2D. What do your micrographs look like? From the first round you have a lot of noise picks. Trying to get a sense of whether the sample looks ok or whether your picking needs some work.
If the sample looks fine in your raw micrographs (good particle numbers in thin ice), I think you may need to collect a lot more data. This looks like it could work.
As others have said, work in C1 for now and use ab-initio to reconstruct it with a somewhat bigger box size.
I usually solubilize the whole cell first with LMNG above CMC 20 times then reduce the conc of detregent micelle bit by bit until i reach to SEC with LMNG below cmc because the LMNG has low off rate .
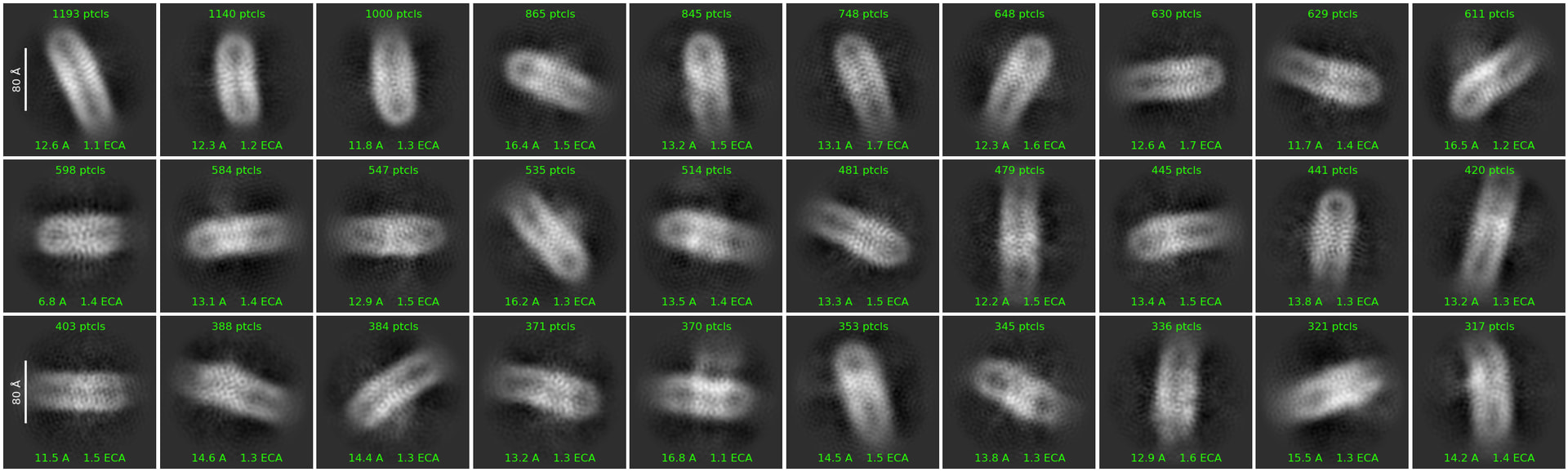
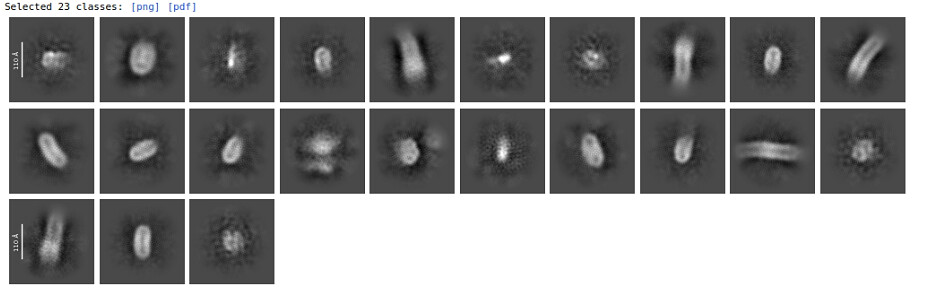
I extracted the particles with bigger box size see this image 1st round of 2D 2million particles 200 classes
A lot of those 2D classes are not your target. From the top left, try selecting the 2nd, 9th, 11th, 12th, 17th, and 22nd classes and carry out another homogeneous refinement.
Or try heterogeneous refinement.
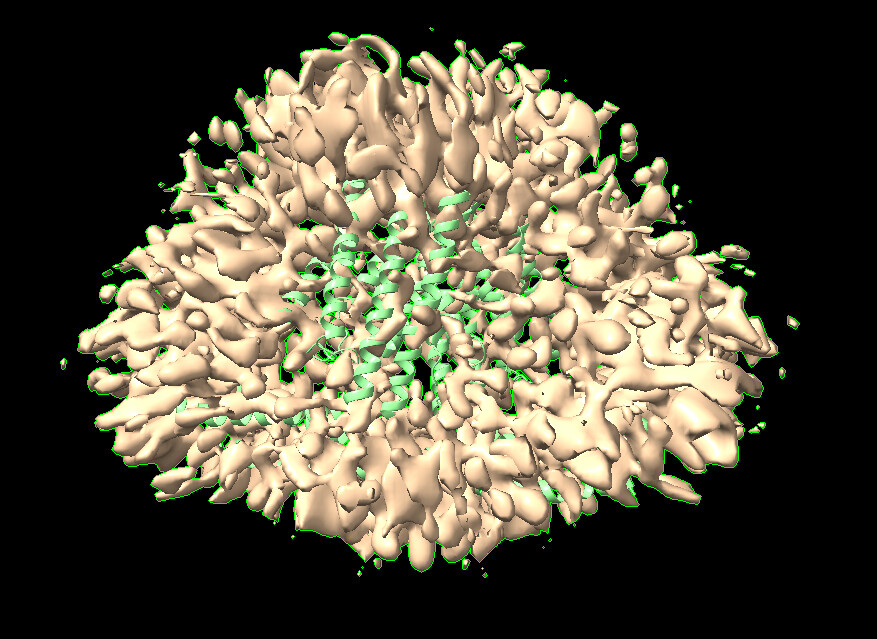
Hate to be the bearer of bad news, but that is overfitted nonsense density. There is no contiguous density for the helices, and the spiky explosion is overfitting.
edit:
These classes, extracted into a larger box and heterogeneously refined, might get you somewhere.
edit 2:
But looking at particle count, it looks like you simply don’t have enough data to get high resolution currently from the higher quality particles.
edit 3:
You could try re-picking with these classes and trying again. But be careful with the thresholding during inspect particle picks.
Thanks, side by side view of the micrograph with and without picks would be helpful. As rbs_sci mentioned, you seem to have many picks that are noise. I would run the denoiser on the micrographs and template pick if you haven’t already. Then set the thresholds aggressively so you mainly only get picks on your target.
Fairly heterogenous micrograph, perhaps trying for a complex. Lots of small things being picked that i would avoid, not likely what you want and they only make the 2D classification a struggle. Dense micrographs that have nice homogenous particles are great, but heterogenous ones makes it a fair bit harder to identify good particles. Always a trade off, in the end more desired particles always better but need to identify them.
Looks like picking many things that are much too small. GPCRs with 7 TMs, even single TM proteins that dimerize in the cytosol have 10nm diameter transmembrane region when you factor in the detergent belts, usually ~3nm of belt on each side. Such i see a lot of small things that aren’t likely desired. There are some nice interesting looking particles: 1) green - the side views for the ~10nm are easy to pick out, there are many things that look like side views that are much smaller that i wouldn’t use 2) yellow - this looks like a nice top/bottom view that has expected contrast with the size desired 3) red - these look interesting are about the expected size. With the current info these are the particles to go after, ideally after picking/inspect jobs these make up no less then 1/5 of the total particles that are being extracted and sent to 2D classification.
Can try a number of things, AI pickers always nice and i recommend them, doing a manual pick on 50-100 random micrographs will give a good feel for the dataset and what to expect from it. Blob picker set the min size to pixel equivalent of 10nm and max to 15nm, play around with “maximum number of local maxima”, reduce this to as low as 300, inspect particle job and enrich desired picks.
While better picking is the best start for this dataset, improving the sample to get more homogenous particles likely the best avenue when shooting for high resolution.