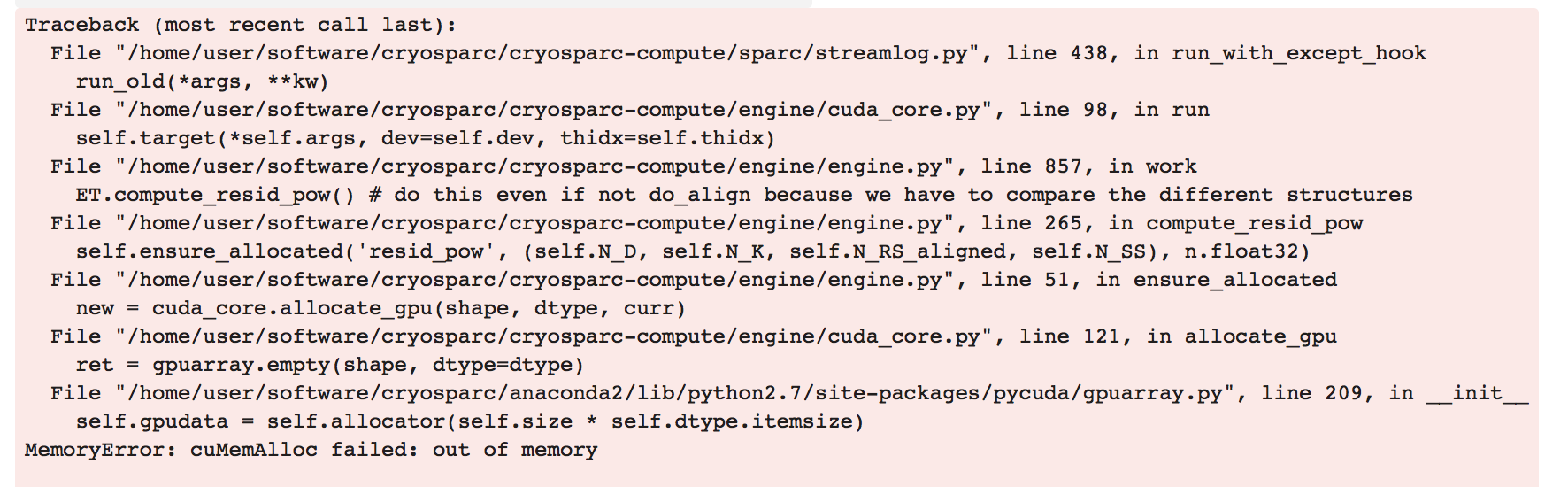
Hi,
I’m running a heterogeneous refinement job - 6 structures, 128px box. I have run many with the same box size and number of structures (or larger - up to 256 pixel box size) without problem, but every now and then it runs out of GPU memory, usually in one of the later iterations where it uses the full dataset. is there anything informative in the attached error as to why this is happening? I performed more or less the same run (same number of structures, box size and number of particles) with slightly different initial models and it completed without issue.
Cheers
Oli
Incidentally, the same job fails with the same error with a 64 px box size, which makes me suspicious - I don’t think it can be as simple as just running out of memory, I think there must be a bug of some sort here
Cheers
Oli
I seem to be getting the intermittent cuMemAlloc failed if there is IO on the same volume cryosparc is using (e.g. I am also extracting new particles in relion while running cryosparc on a different set of stacks).
@DanielAsarnow I’ve seen that too… but in this case there wasn’t anything else going on, just cryoSPARC. Also in this case it successfully completed most of the time with a 128px box, but always failed with this error when using a 64px box, which is weird.
Did you try changing the number of threads to 1 (advanced compute option)?
You can also explicitly specify the CUDA device number there, maybe it’s GPU specific.
I did not, but I’ll try that, thanks!
@apunjani I’ve come to the conclusion that there is definitely something going on here. The memory use just doesn’t add up to the cuMemAlloc errors I’m getting.
I just need to establish whether or not it’s hardware specific, and whether or not it’s related to having another process using a few hundred MB of GPU memory at the same time (but no actual load). The I/O component Oli and I noted is fairly consistent, as well, implying it might be latency related. Can I change the CUDA version somehow to test if it’s a CUDA error (vs. a cryosparc one)?
@apunjani It is definitely not related to other GPU. processes - I had a heterogeneous refinement job running this morning, nothing else on the GPUs (2 Titan-X cards), and it was running fine for 1.5hrs and then died, claiming it had run out of memory.
Also the fact that for another case, using a 128px box works most of the time where a 64px box always fails would suggest that it can’t be due to running out of GPU memory (or if it is, there is a memory leak somewhere)
Cheers
Oli