I have some trouble when working on RTX, namely:
During Ab-initio Reconstruction, the job is terminated without any error message or log. It is just terminated unexpectedly. The curious thing is I observe that behavior when working on 2x RTX 3090 (24GB). It works quite well when on 2x GTX 1070 (8GB), though. I also noticed that when I am working with RTX and doing patch motion correction (multi) I have got errors like that:
[CPU: 318.8 MB] Traceback (most recent call last):
File “cryosparc_worker/cryosparc_compute/run.py”, line 84, in cryosparc_compute.run.main
File “cryosparc_worker/cryosparc_compute/jobs/motioncorrection/run_patch.py”, line 402, in cryosparc_compute.jobs.motioncorrection.run_patch.run_patch_motion_correction_multi
AssertionError: Child process with PID 18325 has terminated unexpectedly!
It does not appear when working on GTX. Both stations have Ubuntu 20.04 LTS. One station has 2x RTX 3090 (24GB) CUDA 11.2 (errors also occur on 11.3). The other station has 2x GTX 1070 (8GB) CUDA 10.1. Dataset is ~850GB (2k frames).
Thanks for reporting this. Do you get this kind of error on every job that uses GPUs on the machine with the 3090s, or just occasionally? If you re-run the same job several times, does it always happen or is it inconsistent?
Also, how much system RAM do you have on the two machines?
Both stations have 256GB of RAM memory. When working on station with GTXs, ab-initio reconstruction calculations are going well, without any error or warning. Same thing is when doing patch motion correction. Things are going to worse when working with RTXs. Ab-initio reconstruction is terminated unexpectedly (without any particular error log). When we restart calculations several times, same thing happens but in different moment/time. Patch motion correction errors on RTXs happen on different time also. Fortunately, after some restarts, calculations end up successfully.
There might be more information in the job log… Would you be able to post the job log? You can access it by running cryosparcm joblog Pxx Jyy > log.txt which will save the contents of the job log to a text file called log.txt, which you can then post. If the file is extremely large, perhaps just paste the last 100 lines by running cryosparcm joblog Pxx Jyy | tail -100 > log.txt
Sorry for a delay with answering to your previous post. I’ve reinstalled OS (now we use Ubuntu 18 LTS) and also updated the CUDA to the newest version (11.4). Unfortunately, things are still going badly. We’ve tried to make many Ab-initio reconstructions and all of them failed with " ====== Job process terminated abnormally." message. Below I paste last 30 lines of two of them:
1st log:
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
========= sending heartbeat
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
========= sending heartbeat
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
HOST ALLOCATION FUNCTION: using cudrv.pagelocked_empty
========= main process now complete.
========= monitor process now complete.
2nd log:
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/util/logsumexp.py:40: RuntimeWarning: divide by zero encountered in log
return n.log(wa * n.exp(a - vmax) + wb * n.exp(b - vmax) ) + vmax
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/sigproc.py:890: RuntimeWarning: invalid value encountered in true_divide
frc[k, :copylen] = (AB / n.sqrt(AABB))[:copylen]
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/util/logsumexp.py:40: RuntimeWarning: divide by zero encountered in log
return n.log(wa * n.exp(a - vmax) + wb * n.exp(b - vmax) ) + vmax
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/sigproc.py:890: RuntimeWarning: invalid value encountered in true_divide
frc[k, :copylen] = (AB / n.sqrt(AABB))[:copylen]
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/util/logsumexp.py:40: RuntimeWarning: divide by zero encountered in log
return n.log(wa * n.exp(a - vmax) + wb * n.exp(b - vmax) ) + vmax
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/sigproc.py:890: RuntimeWarning: invalid value encountered in true_divide
frc[k, :copylen] = (AB / n.sqrt(AABB))[:copylen]
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/util/logsumexp.py:40: RuntimeWarning: divide by zero encountered in log
return n.log(wa * n.exp(a - vmax) + wb * n.exp(b - vmax) ) + vmax
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/sigproc.py:890: RuntimeWarning: invalid value encountered in true_divide
frc[k, :copylen] = (AB / n.sqrt(AABB))[:copylen]
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/util/logsumexp.py:40: RuntimeWarning: divide by zero encountered in log
return n.log(wa * n.exp(a - vmax) + wb * n.exp(b - vmax) ) + vmax
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/sigproc.py:890: RuntimeWarning: invalid value encountered in true_divide
frc[k, :copylen] = (AB / n.sqrt(AABB))[:copylen]
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/util/logsumexp.py:40: RuntimeWarning: divide by zero encountered in log
return n.log(wa * n.exp(a - vmax) + wb * n.exp(b - vmax) ) + vmax
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/sigproc.py:890: RuntimeWarning: invalid value encountered in true_divide
frc[k, :copylen] = (AB / n.sqrt(AABB))[:copylen]
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/util/logsumexp.py:40: RuntimeWarning: divide by zero encountered in log
return n.log(wa * n.exp(a - vmax) + wb * n.exp(b - vmax) ) + vmax
/home/michal/Apps/cryosparc/cryosparc_worker/cryosparc_compute/sigproc.py:890: RuntimeWarning: invalid value encountered in true_divide
frc[k, :copylen] = (AB / n.sqrt(AA*BB))[:copylen]
========= main process now complete.
========= monitor process now complete.
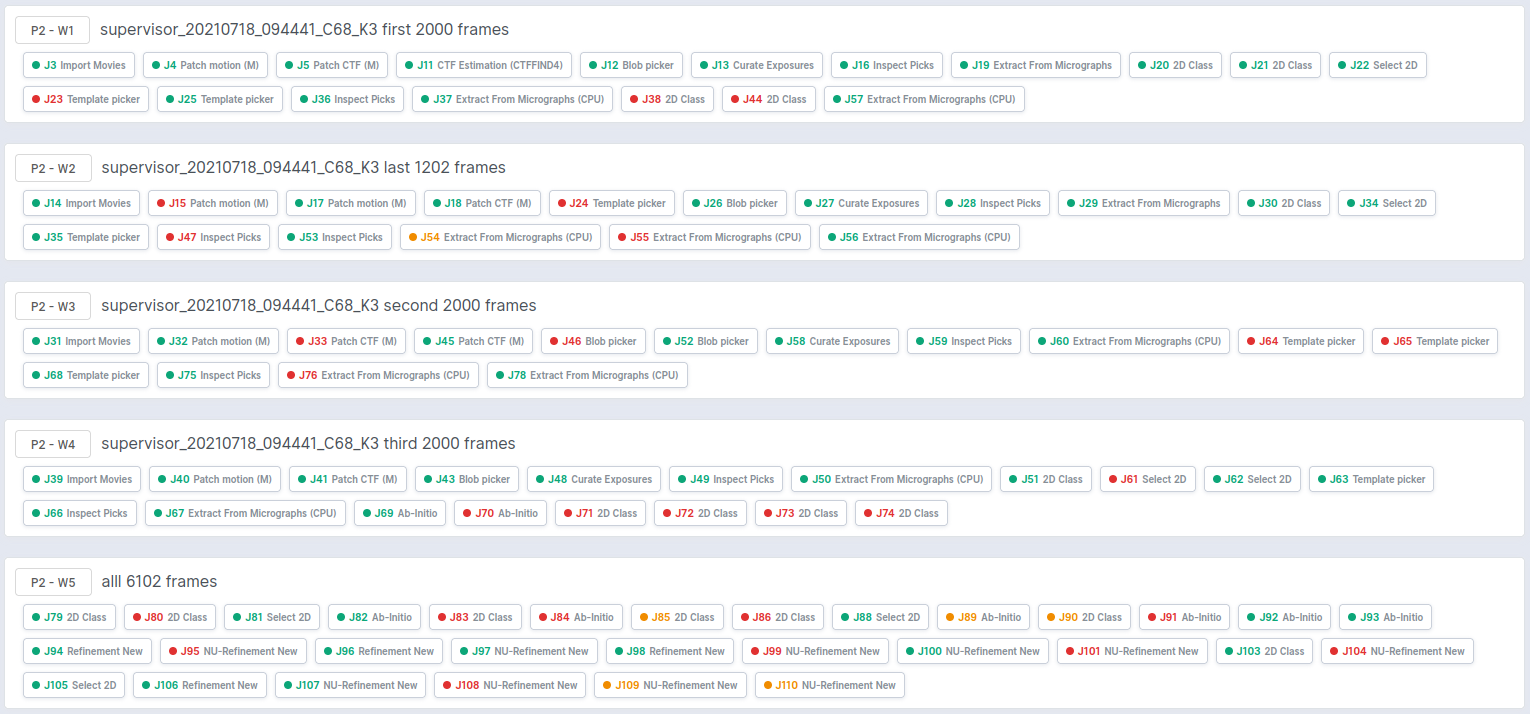
As you can see warnings are different at each time despite the data is the same. What is more we are still have many troubles when working on different jobs (on machine with GTX all of them are going smoothly without any errors) - please see attached print scr.
Hmmm, that is strange indeed. When you changed operating system to Ubuntu 18, did you fully re-install cryosparc, or did you transfer the files over to the new installation? Are other jobs working on the new system (i.e. is it only ab-initio that is failing)?
I have fully reinstalled cryosparc. As you can see there are many jobs that had failed but in many cases finished successfully when re-runned. Unfortunately it seems that there is no obvious pattern when jobs fail and when they finish successfully. ab-initio is still failing - I mean when calculations start we are pretty sure that it will crash at some point. Now I think maybe there are some wrong steps made during installation? Every time when I start with re-installed OS, I install CUDA drivers from nvidia (https://developer.nvidia.com/cuda-downloads?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu), nvidia-smi recognize 2xRTX 3090 and newly installed CUDA. Then I install current version of cryosparc - single workstation (master and worker combined). I do not change python version as I guess it is provided by conda during installation.
I’m sorry I dropped the ball on getting back to you on this. Are you still experiencing this issue? I don’t know off the top of my head what would be causing the symptoms you’re describing, but is it possible it’s the data? Have you run the T20S tutorial from the guide: