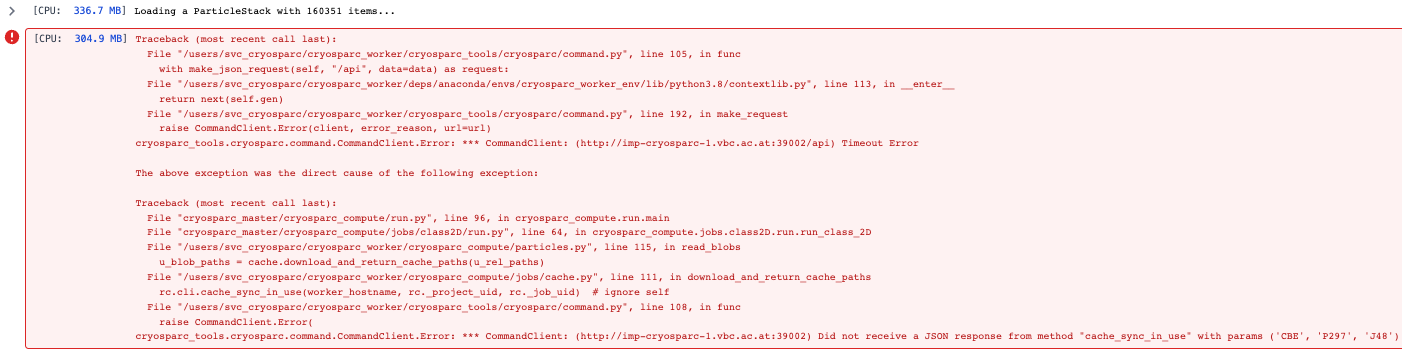
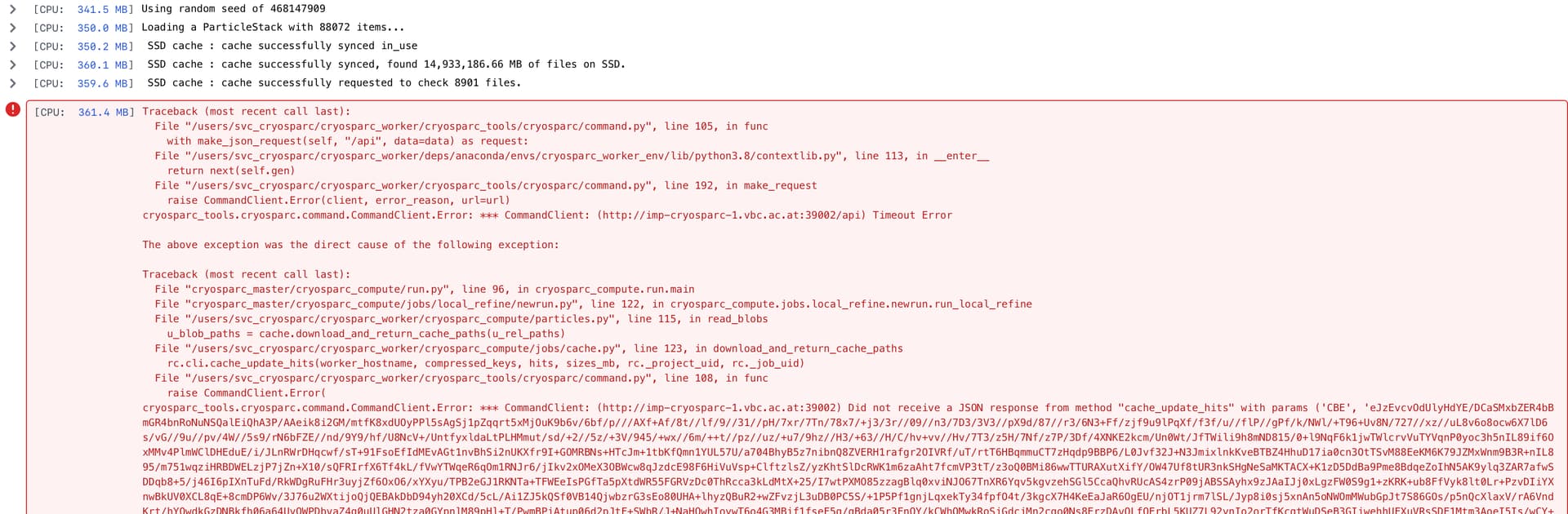
it seems to me, that the db queries (?, I’m not too familiar with mongodb) are taking long, at least contributing to the timeout, from the database.log around the time 2023-08-28 10:04 of the original posted error:
grep cache_files database.log
2023-08-28T10:01:30.795+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6253, $clusterTime: { clusterTime: Timestamp(1693209676, 1540), signature: { hash: BinData(0, 4262F521BEDC8E6E28D1746AA026CA184DEE1F10), keyId: 7231586738655723533 } }, $db: "meteo
r" } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 300013, w: 300013 } }, Database: { acquireCount: { w: 300013 } }, Collection: { acquireCount: { w: 200013 } }, oplog: { acquireCount: { w: 100000 } } } protocol:op_msg 13370ms
2023-08-28T10:01:45.136+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6254, $clusterTime: { clusterTime: Timestamp(1693209690, 5651), signature: { hash: BinData(0, 25753227525096010A74419DCA11BFF3EE998F7B), keyId: 7231586738655723533 } }, $db: "meteo
r" } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 300018, w: 300018 } }, Database: { acquireCount: { w: 300018 } }, Collection: { acquireCount: { w: 200018 } }, oplog: { acquireCount: { w: 100000 } } } protocol:op_msg 13181ms
2023-08-28T10:01:59.315+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6255, $clusterTime: { clusterTime: Timestamp(1693209705, 925), signature: { hash: BinData(0, C4514395E28C82C6EFE054B54E9E75EBAF60C66C), keyId: 7231586738655723533 } }, $db: "meteor
" } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 300035, w: 300035 } }, Database: { acquireCount: { w: 300035 } }, Collection: { acquireCount: { w: 200035 } }, oplog: { acquireCount: { w: 100000 } } } protocol:op_msg 13109ms
2023-08-28T10:02:13.714+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6256, $clusterTime: { clusterTime: Timestamp(1693209719, 2610), signature: { hash: BinData(0, 3B99C2E5B0DA91970C3E6D6C733B6220AB9FE1D4), keyId: 7231586738655723533 } }, $db: "meteo
r" } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 300022, w: 300022 } }, Database: { acquireCount: { w: 300022 } }, Collection: { acquireCount: { w: 200022 } }, oplog: { acquireCount: { w: 100000 } } } protocol:op_msg 13281ms
2023-08-28T10:02:27.961+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6257, $clusterTime: { clusterTime: Timestamp(1693209733, 5711), signature: { hash: BinData(0, EE88DA0092CE4E99815AD389FC81F424E6E16468), keyId: 7231586738655723533 } }, $db: "meteo
r" } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 300010, w: 300010 } }, Database: { acquireCount: { w: 300010 } }, Collection: { acquireCount: { w: 200010 } }, oplog: { acquireCount: { w: 100000 } } } protocol:op_msg 13160ms
2023-08-28T10:02:42.469+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6258, $clusterTime: { clusterTime: Timestamp(1693209747, 7134), signature: { hash: BinData(0, D1EACFB4CA85CB1DFE52D881B39063CBF449EF10), keyId: 7231586738655723533 } }, $db: "meteo
r" } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 300037, w: 300037 } }, Database: { acquireCount: { w: 300037 } }, Collection: { acquireCount: { w: 200037 } }, oplog: { acquireCount: { w: 100000 } } } protocol:op_msg 13481ms
2023-08-28T10:02:57.053+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6259, $clusterTime: { clusterTime: Timestamp(1693209762, 3759), signature: { hash: BinData(0, 6B783AE91FD247849CCFDD237B3F87007B7B6DF7), keyId: 7231586738655723533 } }, $db: "meteo
r" } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 300021, w: 300021 } }, Database: { acquireCount: { w: 300021 } }, Collection: { acquireCount: { w: 200021 } }, oplog: { acquireCount: { w: 100000 } } } protocol:op_msg 13553ms
2023-08-28T10:03:11.569+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6260, $clusterTime: { clusterTime: Timestamp(1693209777, 440), signature: { hash: BinData(0, 2844C48BD4937CB7AE0611BFBF46B2BFB6DD5BC9), keyId: 7231586738655723533 } }, $db: "meteor
" } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 300016, w: 300016 } }, Database: { acquireCount: { w: 300016 } }, Collection: { acquireCount: { w: 200016 } }, oplog: { acquireCount: { w: 100000 } } } protocol:op_msg 13412ms
2023-08-28T10:03:14.456+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6261, $clusterTime: { clusterTime: Timestamp(1693209791, 4753), signature: { hash: BinData(0, BF3981340E1853BF34429C0A53971D09B08F9E5A), keyId: 7231586738655723533 } }, $db: "meteo
r" } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 59243, w: 59243 } }, Database: { acquireCount: { w: 59243 } }, Collection: { acquireCount: { w: 39499 } }, oplog: { acquireCount: { w: 19744 } } } protocol:op_msg 2578ms
2023-08-28T10:03:52.537+0200 I WRITE [conn4246] update meteor.cache_files command: { q: { hostname: "CBE", status: { $in: [ "hit", "miss" ] } }, u: { $set: { status: "miss" } }, multi: true, upsert: false } planSummary: IXSCAN { hostname: 1, status: 1 } keysExamined:2036582 docsExamined:2036581 nMatched:1132679 nModified:903902 keysInserted:1807804 keysDeleted:2711706 numY
ields:15972 locks:{ Global: { acquireCount: { r: 919875, w: 919875 } }, Database: { acquireCount: { w: 919875 } }, Collection: { acquireCount: { w: 15973 } }, oplog: { acquireCount: { w: 903902 } } } 36328ms
2023-08-28T10:03:52.538+0200 I COMMAND [conn4246] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("202c8933-e527-4e47-a63f-e0a9bff593d9") }, $clusterTime: { clusterTime: Timestamp(1693209795, 20), signature: { hash: BinData(0, A2C7D4BB8B4281C22062737BD1717D746178136A), keyId: 7231586738655723533 } }, $db: "meteor", $readPreference
: { mode: "primary" } } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 919875, w: 919875 } }, Database: { acquireCount: { w: 919875 } }, Collection: { acquireCount: { w: 15973 } }, oplog: { acquireCount: { w: 903902 } } } protocol:op_msg 36328ms
2023-08-28T10:04:21.334+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6314, $clusterTime: { clusterTime: Timestamp(1693209848, 18), signature: { hash: BinData(0, B89EBFEAFC1AD8DF8AC72989985770C2605DC5B4), keyId: 7231586738655723533 } }, $db: "meteor"
} numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 268359, w: 268359 } }, Database: { acquireCount: { w: 268359 } }, Collection: { acquireCount: { w: 184201 } }, oplog: { acquireCount: { w: 84158 } } } protocol:op_msg 11485ms
2023-08-28T10:04:35.750+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6315, $clusterTime: { clusterTime: Timestamp(1693209861, 2625), signature: { hash: BinData(0, FE0C4E507FB29DFE00FDF1D3F8224C58545696B1), keyId: 7231586738655723533 } }, $db: "meteo
r" } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 300046, w: 300046 } }, Database: { acquireCount: { w: 300046 } }, Collection: { acquireCount: { w: 200046 } }, oplog: { acquireCount: { w: 100000 } } } protocol:op_msg 13325ms
2023-08-28T10:04:50.051+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6316, $clusterTime: { clusterTime: Timestamp(1693209875, 5744), signature: { hash: BinData(0, C90FFC27F67189ACF0A20C3E38A12E0998A5A875), keyId: 7231586738655723533 } }, $db: "meteo
r" } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 300035, w: 300035 } }, Database: { acquireCount: { w: 300035 } }, Collection: { acquireCount: { w: 200035 } }, oplog: { acquireCount: { w: 100000 } } } protocol:op_msg 13025ms
2023-08-28T10:05:04.029+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6317, $clusterTime: { clusterTime: Timestamp(1693209890, 392), signature: { hash: BinData(0, 826A123AECDA8528D39C9E3526648A1194CCE0D6), keyId: 7231586738655723533 } }, $db: "meteor
" } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 300032, w: 300032 } }, Database: { acquireCount: { w: 300032 } }, Collection: { acquireCount: { w: 200032 } }, oplog: { acquireCount: { w: 100000 } } } protocol:op_msg 12921ms
2023-08-28T10:05:18.348+0200 I COMMAND [conn3924] command meteor.$cmd command: update { update: "cache_files", ordered: true, lsid: { id: UUID("17a626e6-0731-4c7e-817f-7d4fe9bb2ab2") }, txnNumber: 6318, $clusterTime: { clusterTime: Timestamp(1693209904, 205), signature: { hash: BinData(0, C8778B548BFAF5182EDB26C41F65A2FE28BDB306), keyId: 7231586738655723533 } }, $db: "meteor
" } numYields:0 reslen:229 locks:{ Global: { acquireCount: { r: 300037, w: 300037 } }, Database: { acquireCount: { w: 300037 } }, Collection: { acquireCount: { w: 200037 } }, oplog: { acquireCount: { w: 100000 } } } protocol:op_msg 13201ms