Hi cryosparcteam,
When I using cryosparc to do refinement.It meet a error like the this:
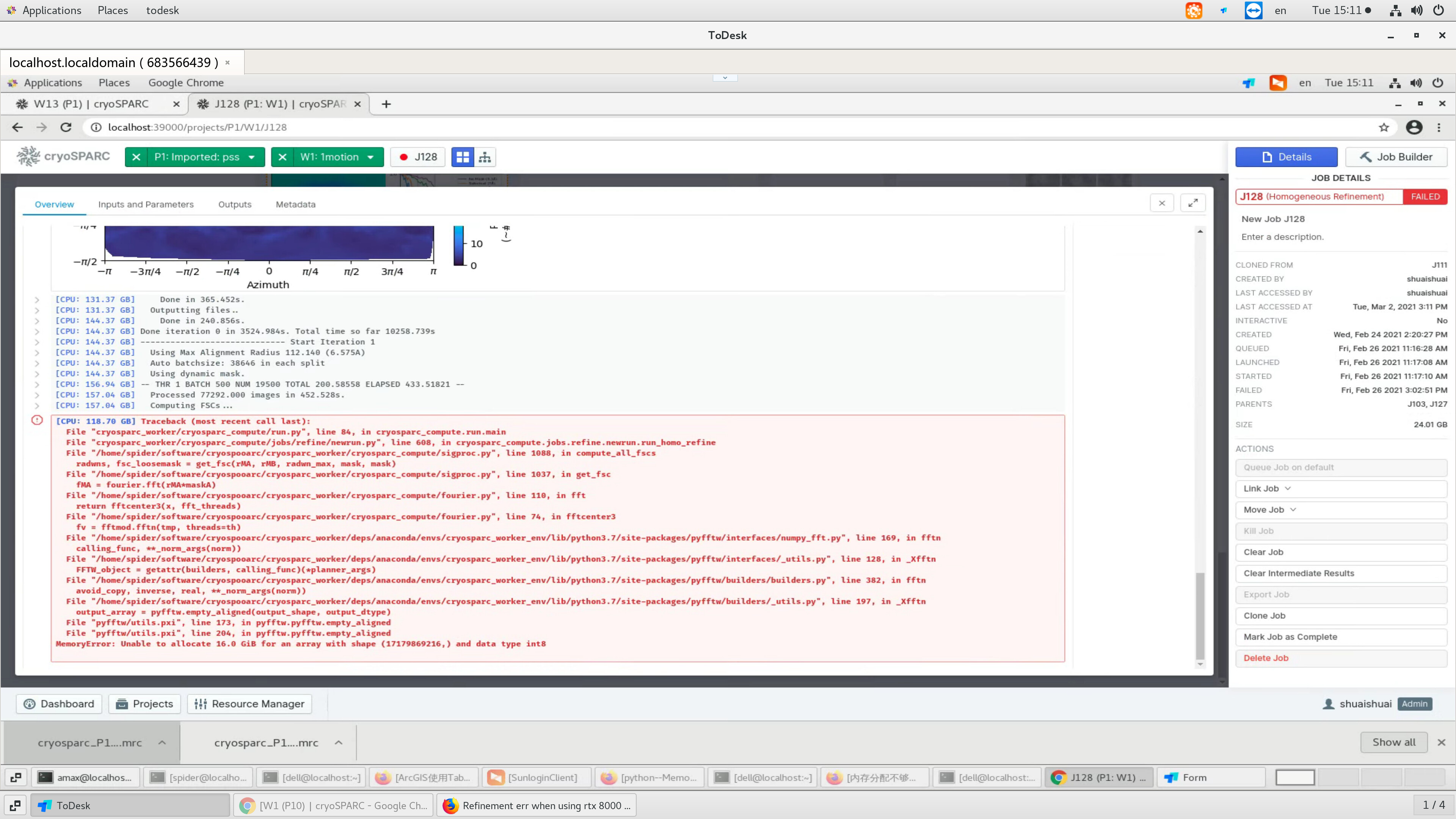
File "cryosparc_worker/cryosparc_compute/run.py", line 84, in cryosparc_compute.run.main
File "cryosparc_worker/cryosparc_compute/jobs/refine/newrun.py", line 608, in cryosparc_compute.jobs.refine.newrun.run_homo_refine
File "/home/spider/software/cryospooarc/cryosparc_worker/cryosparc_compute/sigproc.py", line 1088, in compute_all_fscs
radwns, fsc_loosemask = get_fsc(rMA, rMB, radwn_max, mask, mask)
File "/home/spider/software/cryospooarc/cryosparc_worker/cryosparc_compute/sigproc.py", line 1038, in get_fsc
fMB = fourier.fft(rMB*maskB)
File "/home/spider/software/cryospooarc/cryosparc_worker/cryosparc_compute/fourier.py", line 110, in fft
return fftcenter3(x, fft_threads)
File "/home/spider/software/cryospooarc/cryosparc_worker/cryosparc_compute/fourier.py", line 74, in fftcenter3
fv = fftmod.fftn(tmp, threads=th)
File "/home/spider/software/cryospooarc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.7/site-packages/pyfftw/interfaces/numpy_fft.py", line 169, in fftn
calling_func, **_norm_args(norm))
File "/home/spider/software/cryospooarc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.7/site-packages/pyfftw/interfaces/_utils.py", line 128, in _Xfftn
FFTW_object = getattr(builders, calling_func)(*planner_args)
File "/home/spider/software/cryospooarc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.7/site-packages/pyfftw/builders/builders.py", line 382, in fftn
avoid_copy, inverse, real, **_norm_args(norm))
File "/home/spider/software/cryospooarc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.7/site-packages/pyfftw/builders/_utils.py", line 197, in _Xfftn
output_array = pyfftw.empty_aligned(output_shape, output_dtype)
File "pyfftw/utils.pxi", line 173, in pyfftw.pyfftw.empty_aligned
File "pyfftw/utils.pxi", line 204, in pyfftw.pyfftw.empty_aligned
MemoryError: Unable to allocate 16.0 GiB for an array with shape (17179869216,) and data type int8
My GPU workstation
CPU Intel® Xeon® Gold 6226R CPU @ 2.90GHz
GPU RTX8000
Memory 256G
ssd 2T
My particle boxsize is 1024.
Is this because of the memory too low?
Is there any suggesstions,thanks very much.
There is another question:
when I using rtx8000 to computer boxsize>1024,it didn’t respose longtime,is this a bug?The output like this blew:
License is valid.
Launching job on lane default target localhost ...
Running job on master node hostname localhost
[CPU: 81.6 MB] Project P1 Job J118 Started
[CPU: 81.7 MB] Master running v3.1.0, worker running v3.1.0
[CPU: 81.9 MB] Running on lane default
[CPU: 81.9 MB] Resources allocated:
[CPU: 81.9 MB] Worker: localhost
[CPU: 81.9 MB] CPU : [0, 1, 2, 3]
[CPU: 81.9 MB] GPU : [0]
[CPU: 81.9 MB] RAM : [0, 1, 2]
[CPU: 81.9 MB] SSD : False
[CPU: 81.9 MB] --------------------------------------------------------------
[CPU: 81.9 MB] Importing job module for job type homo_reconstruct...
[CPU: 534.2 MB] Job ready to run
[CPU: 534.2 MB] ***************************************************************
[CPU: 783.8 MB] Loading a ParticleStack with 10000 items...
[CPU: 783.8 MB] Done.
[CPU: 783.8 MB] Windowing particles
[CPU: 825.6 MB] Done.
[CPU: 825.6 MB] ====== Gold Standard Split ======
[CPU: 825.6 MB] Particles have input alignments3D connected, so reusing pre-existing split
[CPU: 825.6 MB] Split A has 4941 particles
[CPU: 825.6 MB] Split B has 5059 particles
[CPU: 825.6 MB] ====== Reconstruction ======
[CPU: 825.6 MB] Input particles have box size 1500
[CPU: 825.6 MB] Input particles have pixel size 0.9120
[CPU: 825.8 MB] Volume refinement will be done with effective box size 1500
[CPU: 825.8 MB] Volume refinement will be done with pixel size 0.9120
[CPU: 825.8 MB] Particles will be zeropadded/truncated to size 1500 during backprojection
[CPU: 825.8 MB] Particles will be backprojected with box size 1500
[CPU: 827.2 MB] Reconstructing with C8 symmetry enforced
[CPU: 2.13 GB] Engine Started.