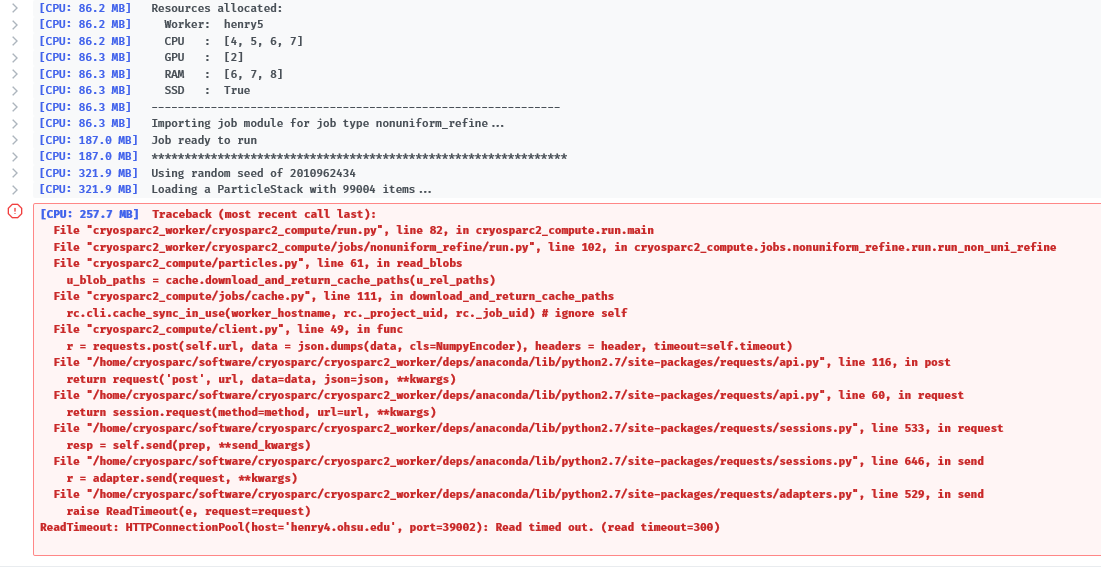
We have a setup with 1 master in charge of 3 workstations. Since the update, most (though not all) of our jobs have a difficult time starting up. We have noticed this issue happens more often with non-uniform refinement jobs. seems like the jobs start, but after they ensure the files are available on cache, then nothing happens and we get the following error
is your master node also a worker (i.e. does it run GPU processing jobs)
do you see this happen when other jobs are running, or even when nothing is happening on the system?
How many micrographs did these 99004 particles come from in this case?
Can you try stopping the cryosparc master, checking that there are no zombie processes running (use ps -ax | grep cryosparc), kill them if there are any, and then start cryosparc again?
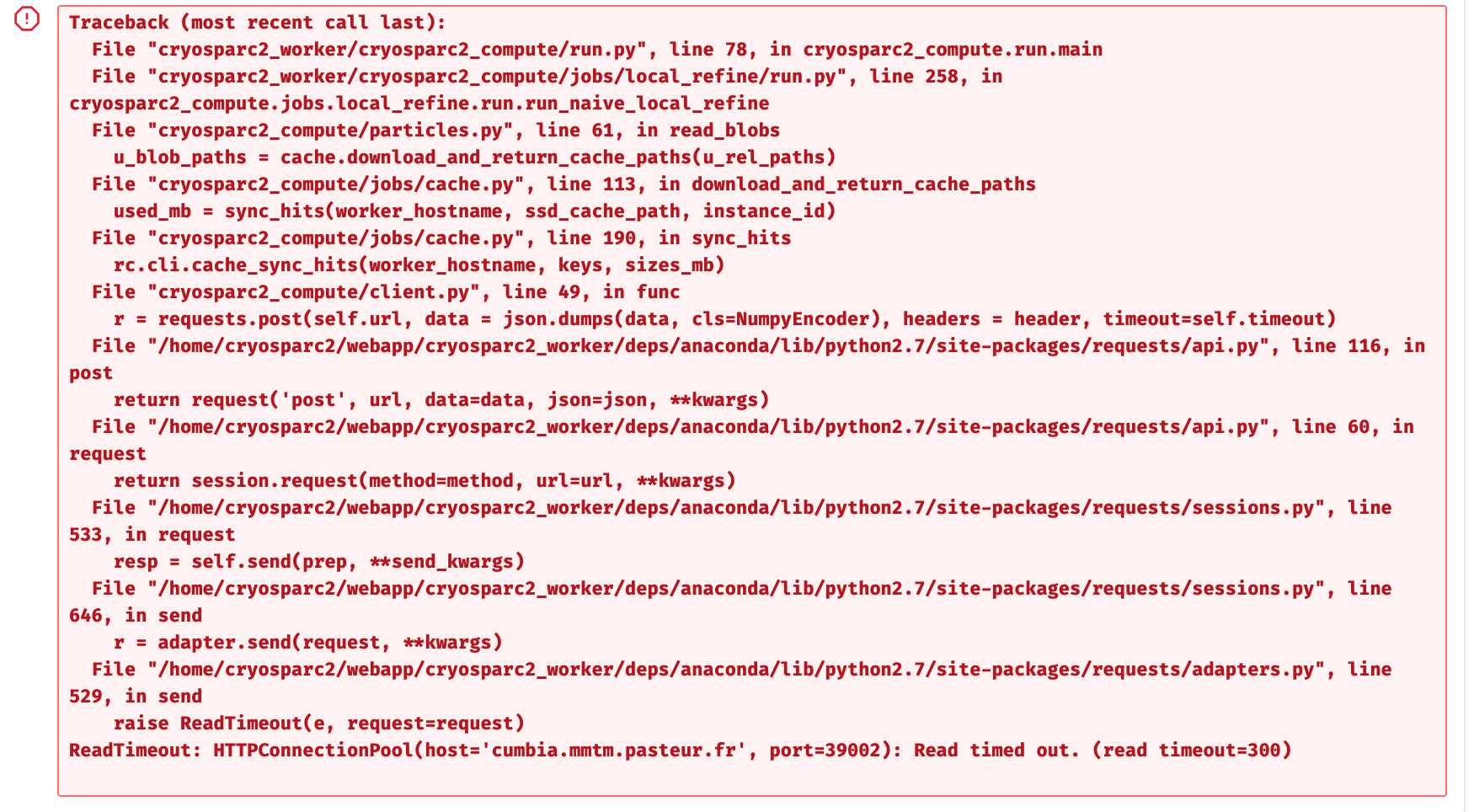
Hi, @ThyZAD, @apunjani could this issue be solved? I am also getting “read time out” error (please see the screenshot attached.) a lot lately and am unable to run the job. This is happening even with the Refinement and Ab-initio reconstruction jobs which I could run successfully before. In my case, this happens even when there is no other job running on the system. Any help in troubleshooting is appreciated.
Thanks.
Kapil