Hi,
Concerning the PCA mode of initialization in 3D classification, some thoguths/queries (maybe a q for @vperetroukhin?):
-
Are there any documents describing how this is done? I can’t find any description in the 3D classification job page or tutorial (I think there was in the earlier one for 3.3 but I can’t find it now?)
-
Broadly speaking this seems similar to the “conformational landscape analysis” idea in cryoDRGN, where volumes are calculated from kmeans clusters of the latent space, and then PCA is performed on the volumes. But in this case, the job can’t assume that there is a precalculated latent space, so are clusters just selected randomly, and if so what do the resulting PCs mean?
-
The idea of performing PCA on clustered volumes might be useful for interpreting 3D-VA results?
-
Would it be useful/possible to initialize 3D classification using 3D-VA components as inputs to generate more diverse volumes for initializing the classification?
Cheers
Oli
Hey @olibclarke!
Are there any documents describing how this is done? I can’t find any description in the 3D classification job page or tutorial (I think there was in the earlier one for 3.3 but I can’t find it now?)
You’re right – we dropped this elucidation for now largely because (at least in our testing) the PCA-based initialization never proved to be a critical component in getting good classification results. Have you seen improvements with it? In any case, the initialization works as follows:
-
We randomly select N batches of particles and back-project,
-
For each of the N volumes, we filter at the ‘initialization’ resolution, and then apply the supplied/auto solvent (or focus) mask,
-
Next, we treat each of these N volumes as a single point of an N_V dimensional space (where N_V is equal to the no. of non-zero voxels in the mask), and apply PCA on this N x N_V dataset.
-
We select the first C principal components, and then cluster this N x C dataset using a Gaussian Mixture Model with K components.
-
Finally, for each of the K clusters, we average each of the N_K < N volumes that are assigned to it and call this an initialization.
Broadly speaking this seems similar to the “conformational landscape analysis” idea in cryoDRGN, where volumes are calculated from kmeans clusters of the latent space, and then PCA is performed on the volumes. But in this case, the job can’t assume that there is a precalculated latent space, so are clusters just selected randomly, and if so what do the resulting PCs mean?
Yep that’s right – since we don’t have any learned latents we simply ‘vectorize’ the voxels in each of the N backprojected-and-masked volumes and apply PCA on this very-high-dimensional space. We initially thought this might be a (sometimes) useful thing to do to roughly categorize large discrete changes, but it doesn’t seem to produce good results (probably due to noise, but we haven’t investigated this extensively).
The idea of performing PCA on clustered volumes might be useful for interpreting 3D-VA results?
Can you elaborate on this further? What do you mean by PCA on clustered volumes exactly?
Would it be useful/possible to initialize 3D classification using 3D-VA components as inputs to generate more diverse volumes for initializing the classification?
This would definitely be possible and something we’ll look into! Improving initializations is on the roadmap. Out of curiosity, have you ever tried initializing 3D class with 3DVA outputs (one from each component in simple mode or K from cluster mode, etc.)?
Valentin
2 Likes
Hi Valentin,
he PCA-based initialization never proved to be a critical component in getting good classification results. Have you seen improvements with it?
No we haven’t - but when I have used it, all the initial volumes look more or less the same anyway, even when I know from 3D-VA etc that there is a lot of heterogeneity in the dataset. Maybe this is because the clusters are too large, so there is too little variability between the different reconstructions?
Can you elaborate on this further? What do you mean by PCA on clustered volumes exactly?
I was thinking along the lines of landscape analysis in cryodrgn (https://zhonge.github.io/cryodrgn/pages/landscape_analysis.html & chapter 6 of Ellen’s thesis), where the latent space is sampled at random points to generate ~500-1000 reconstructions (which are then analyzed by PCA). This reminded me of the approach you were using to initialize 3D-classification, but it seemed like sampling the space explored by 3D-VA might generate starting volumes that have more diversity. We have found it useful already to seed 3D-classification (and heterogeneous refinement) from states identified using cryoDRGN; I haven’t tried using random clusters from 3D-VA to initialize yet.
1 Like
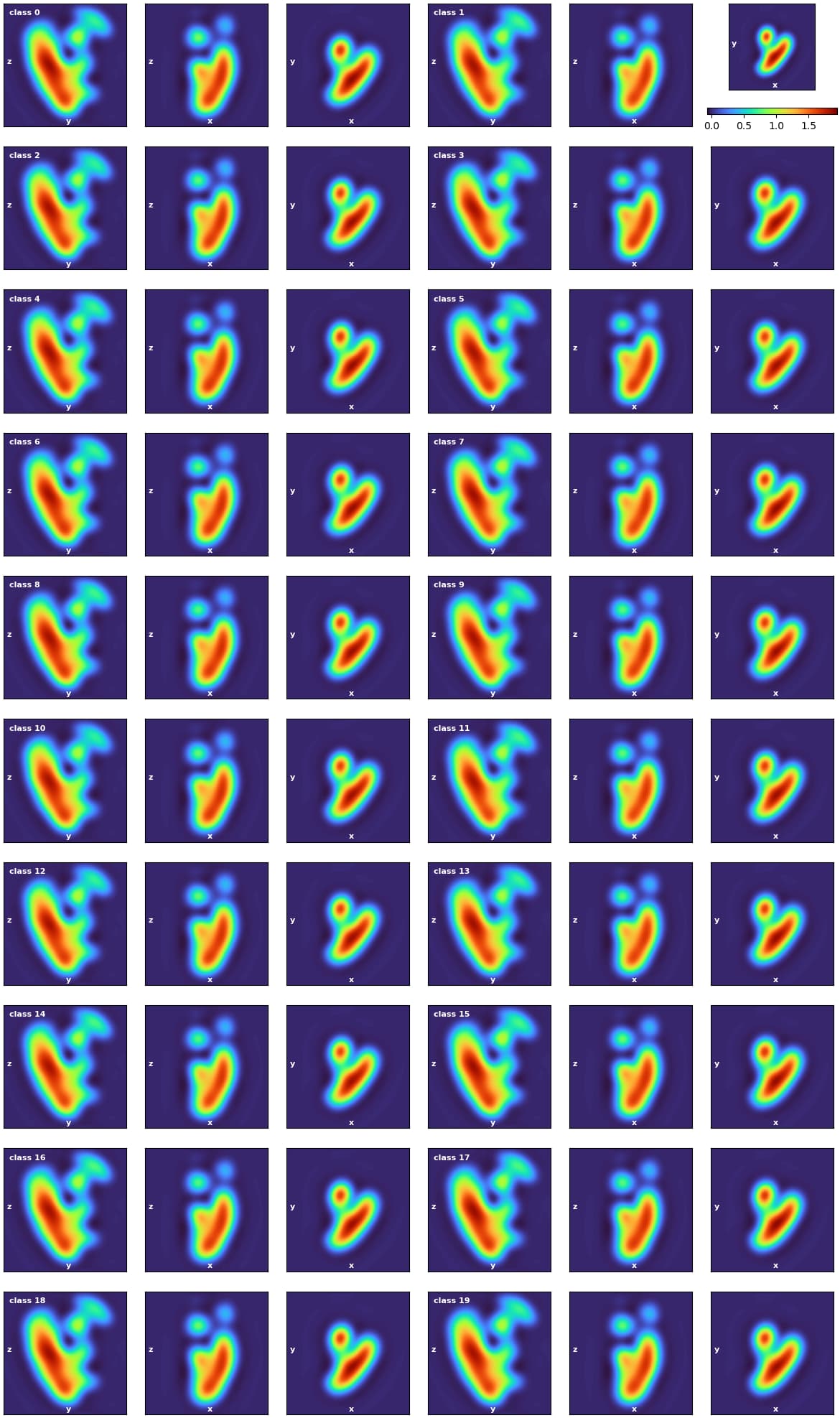
Hi @vperetroukhin - here is what I mean re all initial volumes looking the same:
These are PCA volumes generated from a particles originating from a heterogeneous refinement containing all classes in our ankyrin complex dataset (EMPIAR-11043 Architecture of the human erythrocyte ankyrin-1 complex), so there should be a lot of conformational and compositional heterogeneity, and indeed it is evident in the final classes of the classification, but the initial volumes look much more similar to each other than I would expect given that they originate from a dataset with a lot of heterogeneity (and where that heterogeneity is readily identifiable by 3D-VA).
Cheers
Oli
1 Like
My guess is the heterogeneity is probably understated a lot, if the samples are small than the less commonly represented states might always be below the noise floor.
It’s a really similar approach to computing old-school variance maps, I wonder if the regions where you expect the heterogeneity to appear would look different in one of those. (E.g. computed with star.py --subsample/relion_reconstruct, or the equivalent tools in cryoSPARC, and varmap.py).
Ok thanks for reporting! I think even accounting for Daniel’s comment, the PCA-based initialization needs some work to produce initial volumes that are better than the simple bootstrapping. We’ll take a deep dive into this shortly.
2 Likes