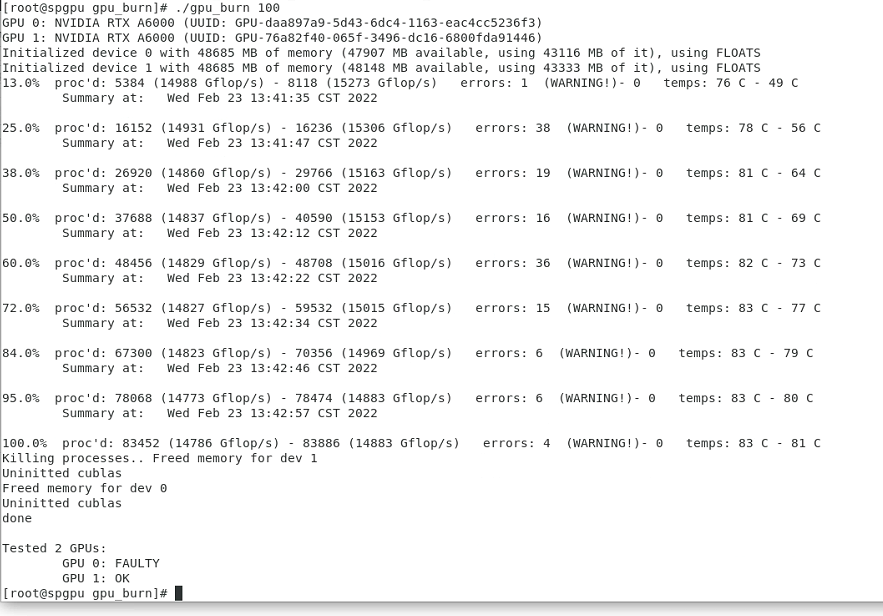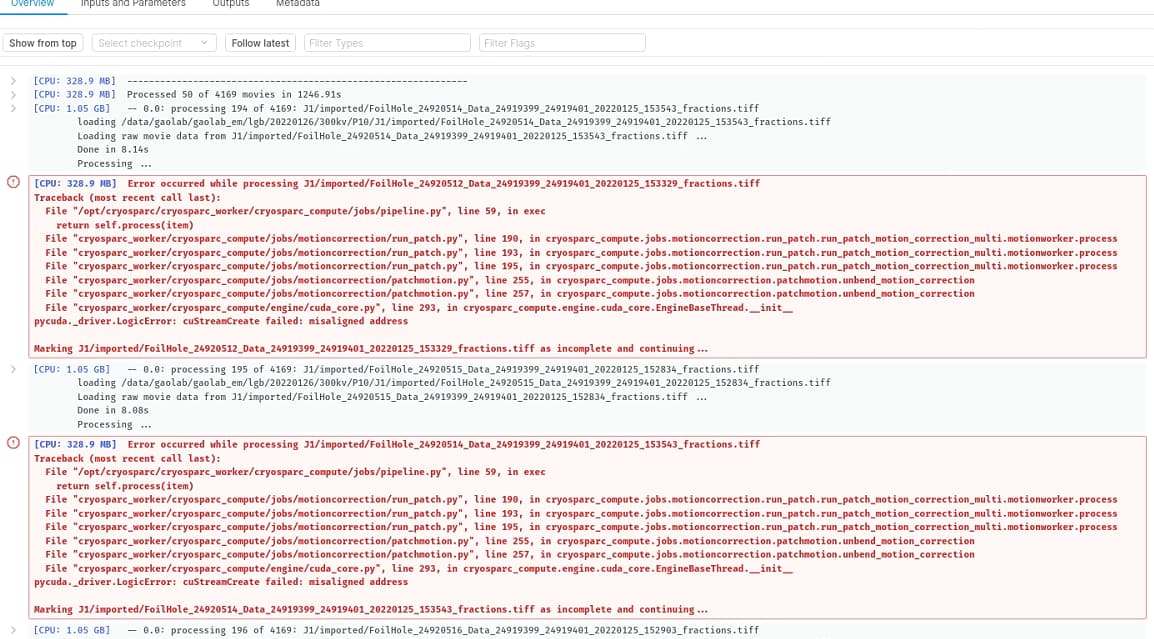
When I run patch motion correction, I always get the error as shown in the figure, only 1000 of 4000 pictures complete the calculation
Welcome to the forum @zhe. Please can you tell us more about your case:
- movie format (
movie_blob/shape) from the Overview tab of Job J1 - cryoSPARC worker info:
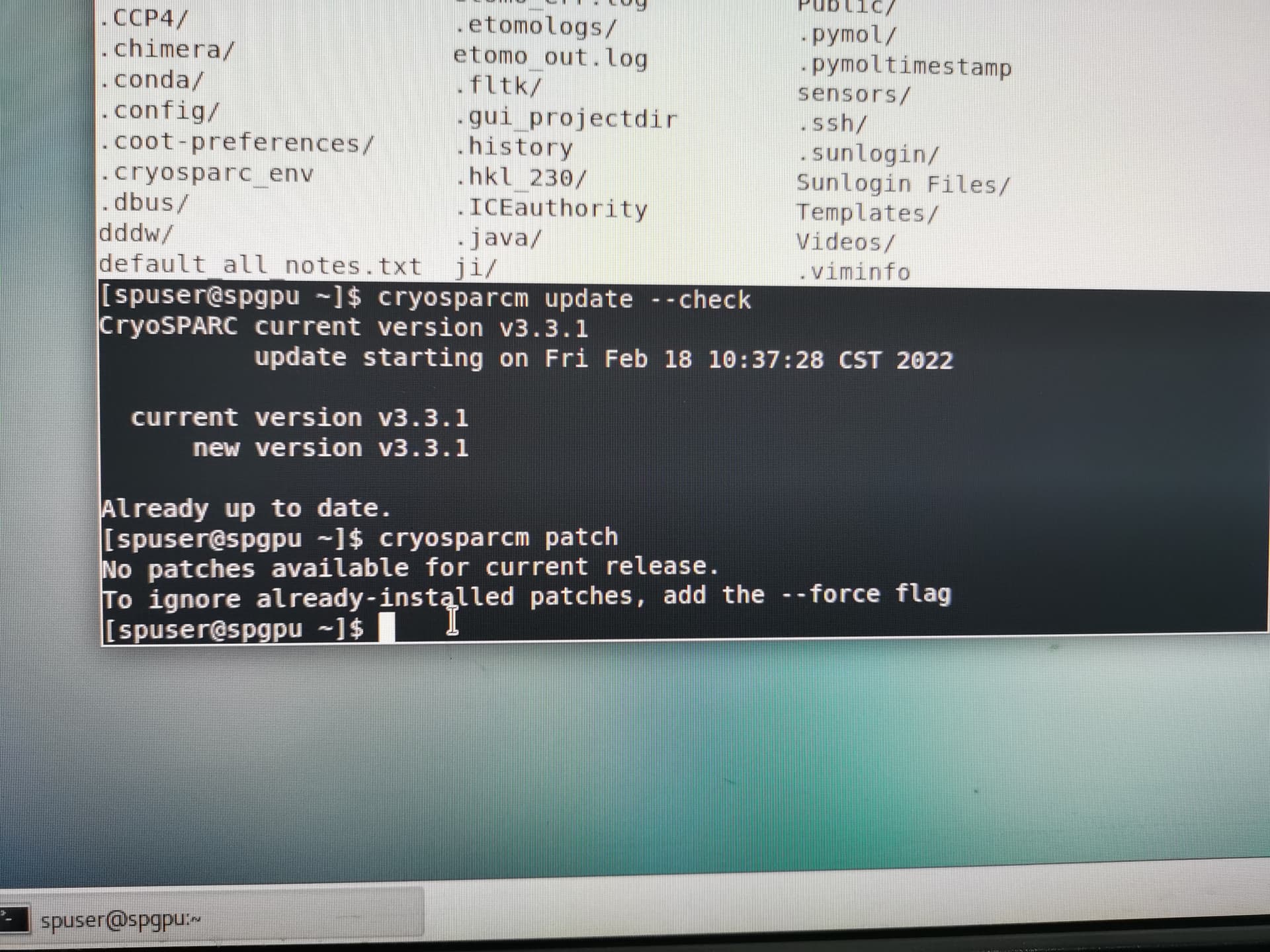
- cryoSPARC version and patch level
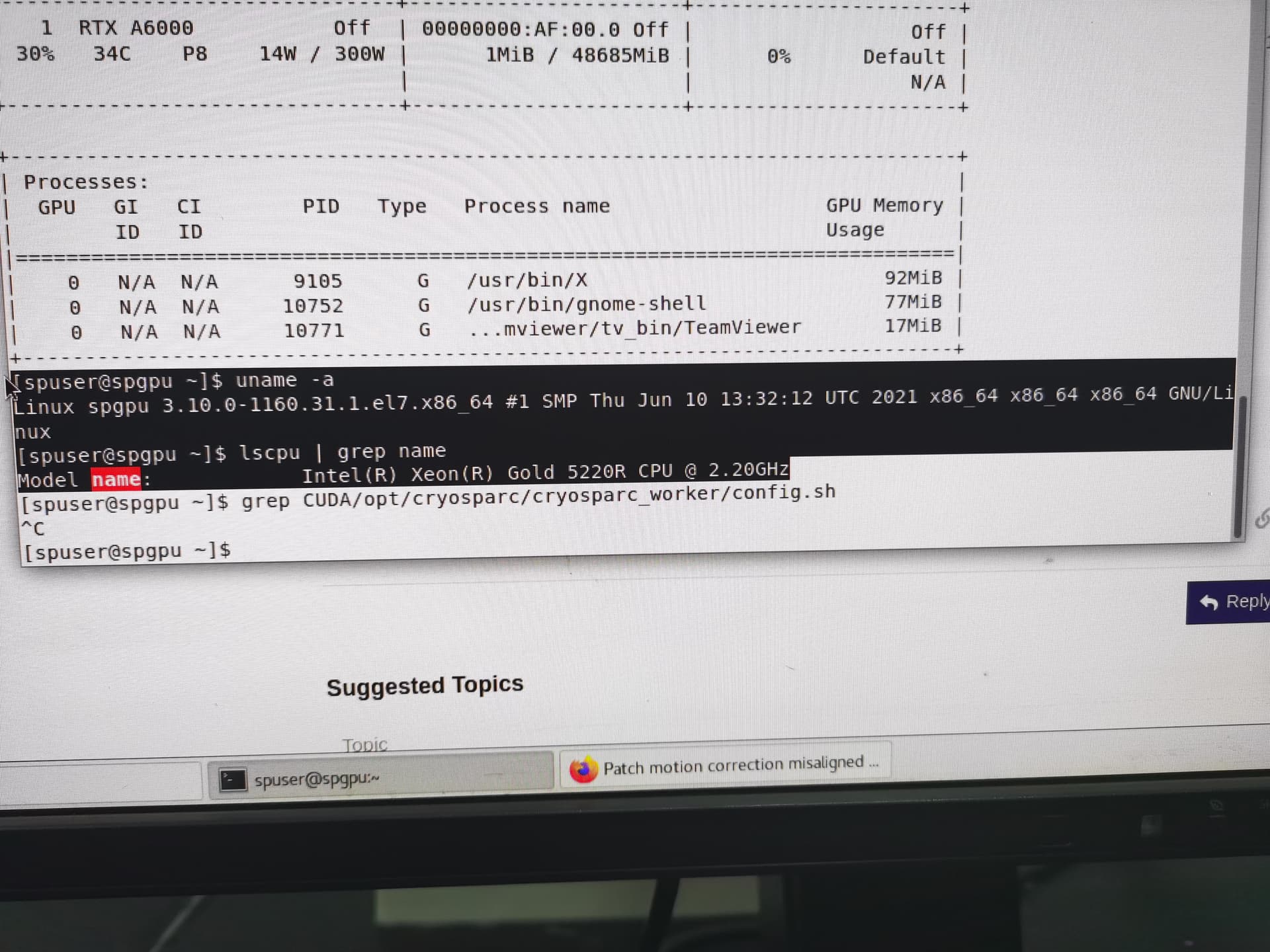
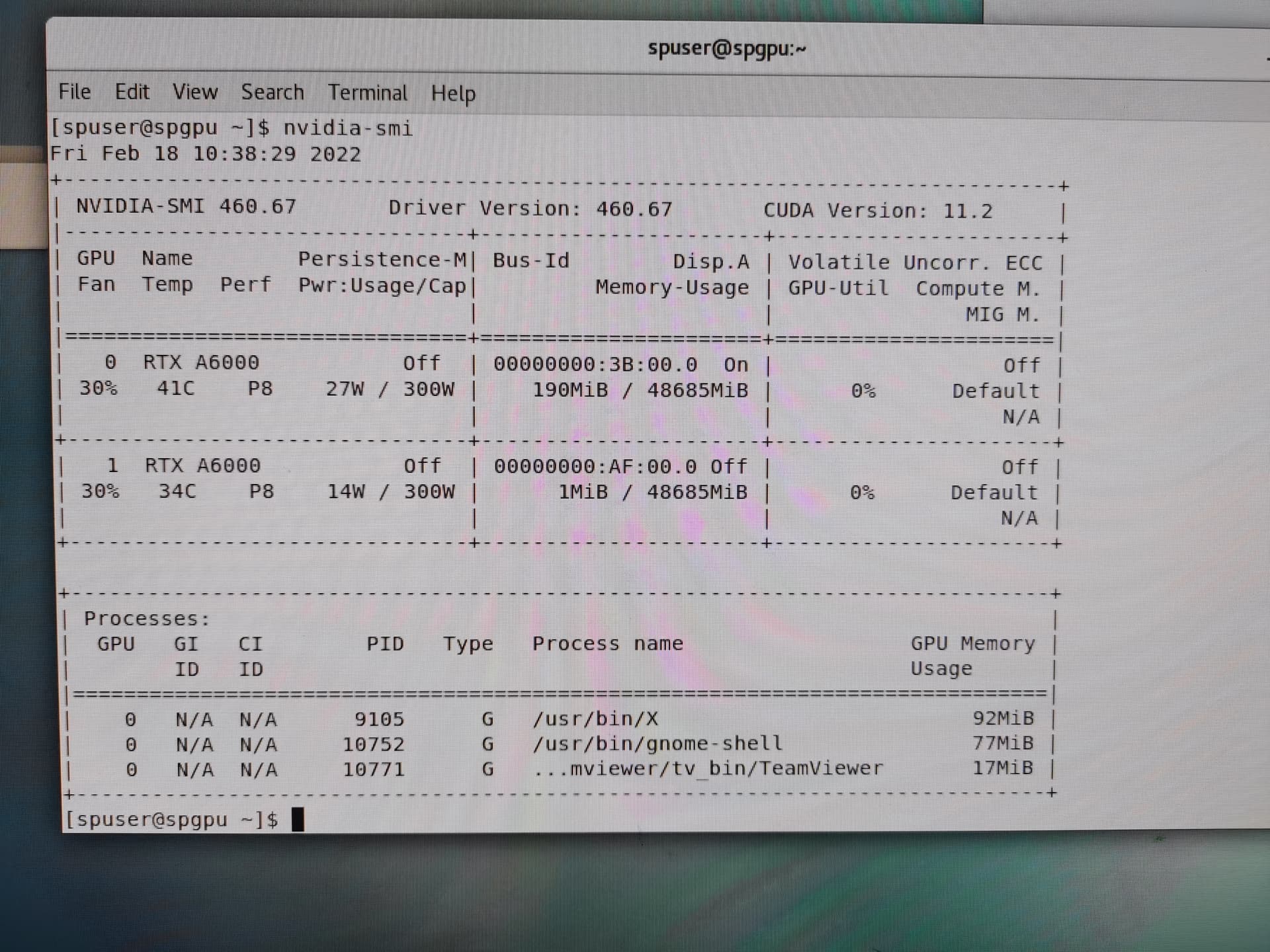
- gpu models and driver version (from
nvidia-smi) - linux kernel version (from
uname -a) - cpu version (
lscpu | grep name) - worker cuda version (
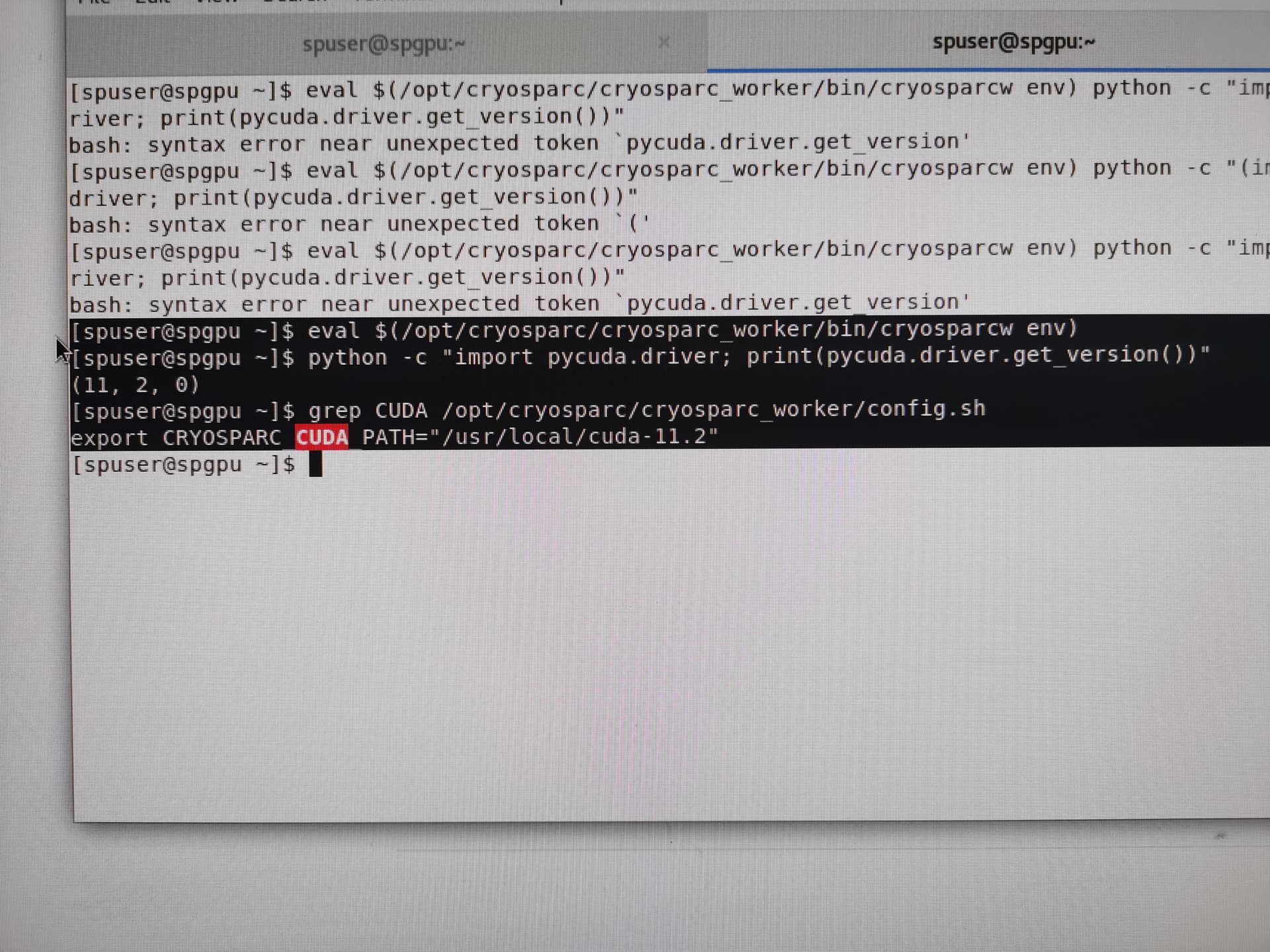
grep CUDA /opt/cryosparc/cryosparc_worker/config.sh) - worker pycuda version:
eval $(/opt/cryosparc/cryosparc_worker/bin/cryosparcw env)
python -c "import pycuda.driver; print(pycuda.driver.get_version())"
Thank you very much for your reply. The information I found is as follows. thank you very much. Since I can only attach one picture at a time, I reply all the pictures in multiple pieces of information at the back
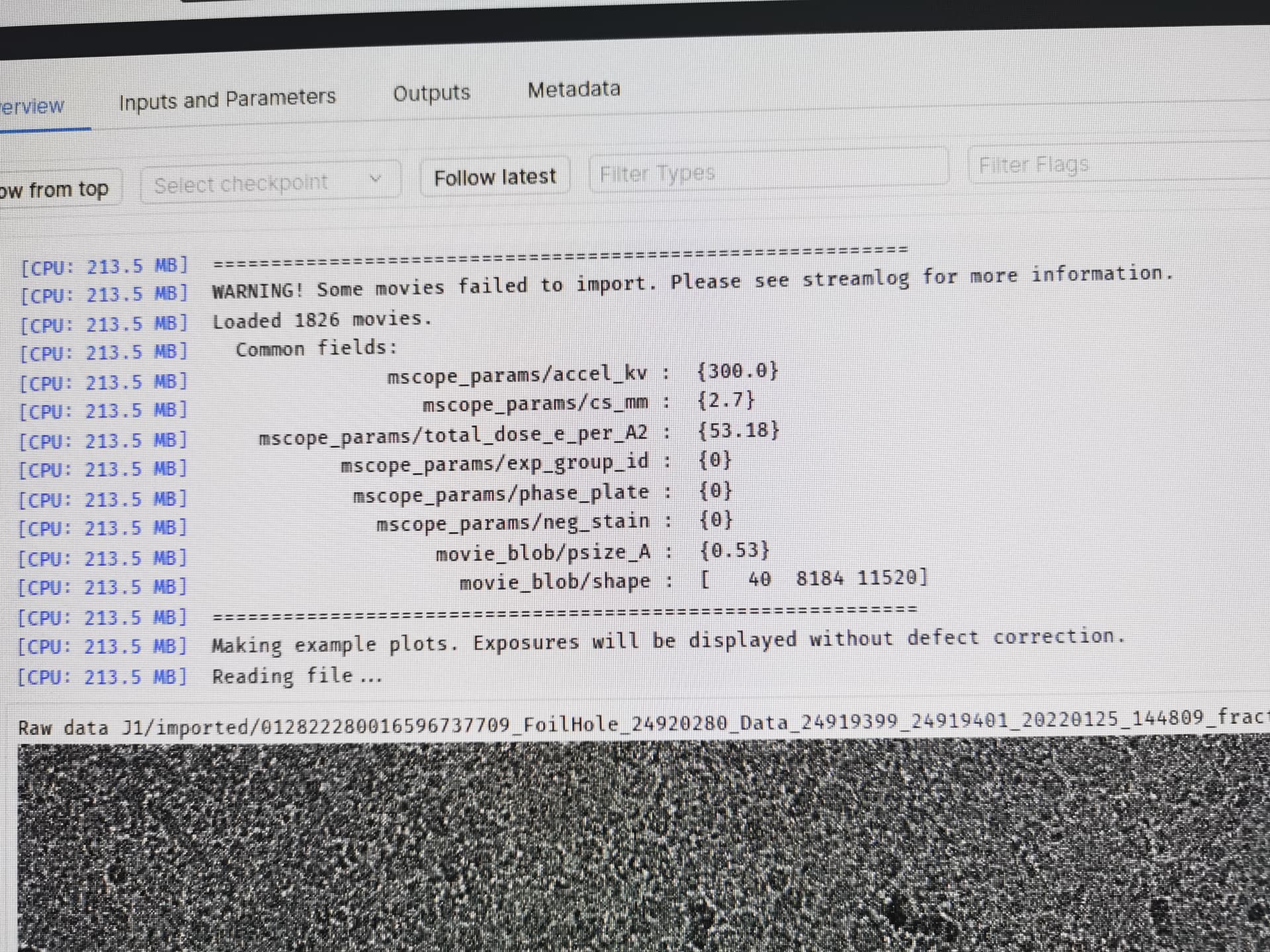
@zhe The import output you posted shows a warning near the top. Inspection of the entire output (“Show from top”) may reveal an underlying issue that needs to be resolved.
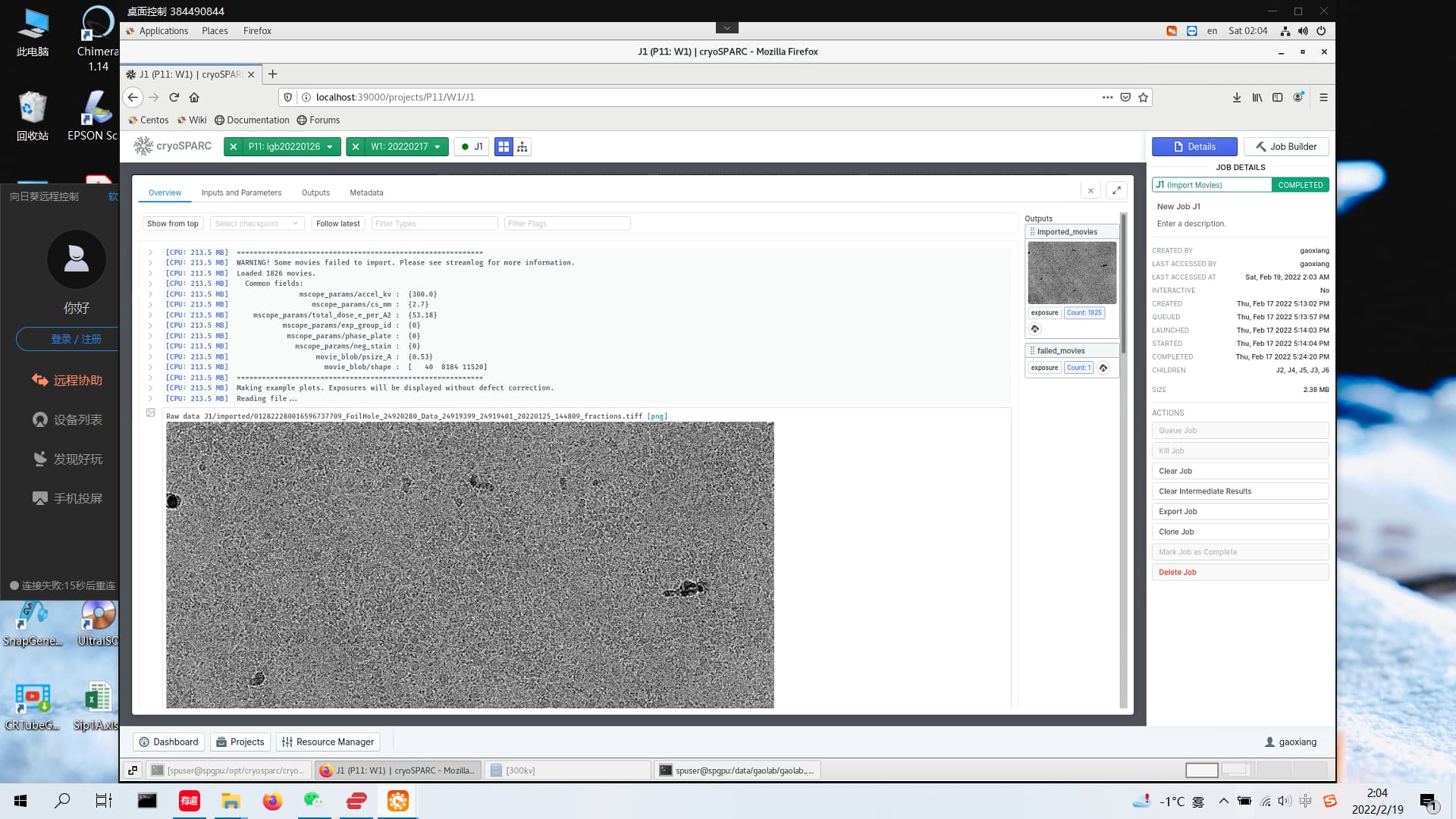
Yes, there is a warning. But this is because one photo failed to be imported. Here is the complete screenshot. I’m very sorry for the trouble to your work.
@zhe Is there any indication why the import failed?
On the other hand, other users have reported CUDA-related errors on kernel v3-based systems. The specific errors were different, and I am not sure the proposed interventions would solve the motion correction error you are experiencing.
How much RAM (free -g) does your system have?
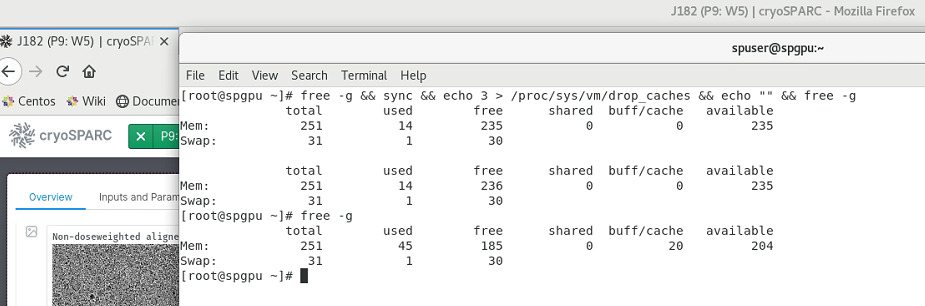
As this picture shows, my friend helped me free up memory space. I’m a biology phD myself and not very computer savvy. Thank you very much for your help
@zhe What happens when you connect the movies that were marked as incomplete in the old patch motion job as input to a new patch motion job that is otherwise identical to the old job? Do any of those previously “incomplete” movies complete in the new job?