配置文件如下:
#!/usr/bin/env bash
#### cryoSPARC cluster submission script template for SLURM
## Available variables:
## {{ run_cmd }} - the complete command string to run the job
## {{ num_cpu }} - the number of CPUs needed
## {{ num_gpu }} - the number of GPUs needed.
## Note: The code will use this many GPUs starting from dev id 0.
## The cluster scheduler has the responsibility
## of setting CUDA_VISIBLE_DEVICES or otherwise enuring that the
## job uses the correct cluster-allocated GPUs.
## {{ ram_gb }} - the amount of RAM needed in GB
## {{ job_dir_abs }} - absolute path to the job directory
## {{ project_dir_abs }} - absolute path to the project dir
## {{ job_log_path_abs }} - absolute path to the log file for the job
## {{ worker_bin_path }} - absolute path to the cryosparc worker command
## {{ run_args }} - arguments to be passed to cryosparcw run
## {{ project_uid }} - uid of the project
## {{ job_uid }} - uid of the job
## {{ job_creator }} - name of the user that created the job (may contain spaces)
## {{ cryosparc_username }} - cryosparc username of the user that created the job (usually an email)
##
## What follows is a simple SLURM script:
#SBATCH --job-name cryosparc_{{ project_uid }}_{{ job_uid }}
{% set increased_num_cpu = 8 -%}
#SBATCH --cpus-per-task={{ [1, num_cpu, [increased_num_cpu*num_gpu, increased_num_cpu]|min]|max }}
#SBATCH --mem={{ (ram_gb * 1000 * 2) | int }}M
#SBATCH --gres=gpu:{{ num_gpu }}
#SBATCH --partition=gpu40
#SBATCH --output={{ job_dir_abs }}/slurm.out
#SBATCH --error={{ job_dir_abs }}/slurm.err
{{ run_cmd }}
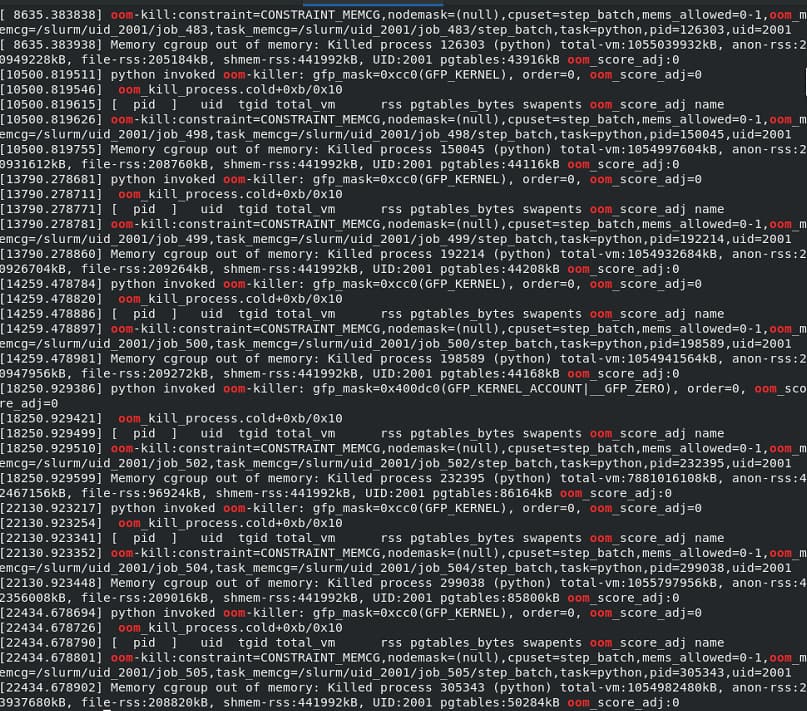
For example, Non-uniform Refinement allocates only 24G memory by default. If it exceeds a certain amount, it will be killed by Ubuntu OOM. How can cryosparc allocate reasonable memory? It actually needs 160 or even more memory.
System: ubuntu22.04
cryosparc version: 4.6.1