thank you @wtempel ,
this helped.
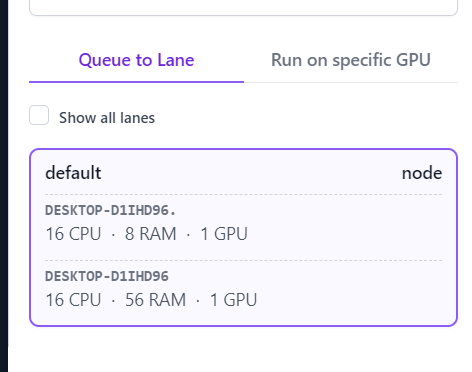
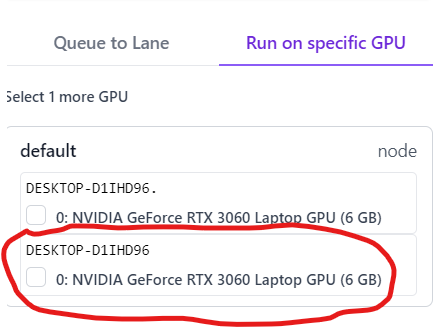
But now I have 2 nodes for the selection. One of them is not running  (probably the old one)
(probably the old one)
Is there a way to remove it?
Another question.
After the update I got the following error.
Any clues how to fix that ?
thank you
Traceback (most recent call last):
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pycuda/tools.py”, line 429, in context_dependent_memoize
return ctx_dict[cur_ctx][args]
KeyError: <pycuda._driver.Context object at 0x7ff2964e07b0>
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pytools/prefork.py”, line 48, in call_capture_output
popen = Popen(cmdline, cwd=cwd, stdin=PIPE, stdout=PIPE,
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/subprocess.py”, line 858, in init
self._execute_child(args, executable, preexec_fn, close_fds,
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/subprocess.py”, line 1704, in _execute_child
raise child_exception_type(errno_num, err_msg, err_filename)
FileNotFoundError: [Errno 2] No such file or directory: ‘nvcc’
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “cryosparc_master/cryosparc_compute/run.py”, line 96, in cryosparc_compute.run.main
File “cryosparc_master/cryosparc_compute/jobs/class2D/run.py”, line 336, in cryosparc_compute.jobs.class2D.run.run_class_2D
File “cryosparc_master/cryosparc_compute/engine/engine.py”, line 964, in cryosparc_compute.engine.engine.process
File “cryosparc_master/cryosparc_compute/engine/engine.py”, line 974, in cryosparc_compute.engine.engine.process
File “cryosparc_master/cryosparc_compute/engine/cuda_core.py”, line 156, in cryosparc_compute.engine.cuda_core.allocate_gpu
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pycuda/gpuarray.py”, line 549, in fill
func = elementwise.get_fill_kernel(self.dtype)
File “”, line 2, in get_fill_kernel
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pycuda/tools.py”, line 433, in context_dependent_memoize
result = func(*args)
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pycuda/elementwise.py”, line 493, in get_fill_kernel
return get_elwise_kernel(
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pycuda/elementwise.py”, line 162, in get_elwise_kernel
mod, func, arguments = get_elwise_kernel_and_types(
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pycuda/elementwise.py”, line 148, in get_elwise_kernel_and_types
mod = module_builder(arguments, operation, name,
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pycuda/elementwise.py”, line 45, in get_elwise_module
return SourceModule(“”"
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pycuda/compiler.py”, line 290, in init
cubin = compile(source, nvcc, options, keep, no_extern_c,
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pycuda/compiler.py”, line 254, in compile
return compile_plain(source, options, keep, nvcc, cache_dir, target)
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pycuda/compiler.py”, line 78, in compile_plain
checksum.update(preprocess_source(source, options, nvcc).encode(“utf-8”))
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pycuda/compiler.py”, line 50, in preprocess_source
result, stdout, stderr = call_capture_output(cmdline, error_on_nonzero=False)
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pytools/prefork.py”, line 226, in call_capture_output
return forker.call_capture_output(cmdline, cwd, error_on_nonzero)
File “/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pytools/prefork.py”, line 59, in call_capture_output
raise ExecError(“error invoking ‘%s’: %s”
pytools.prefork.ExecError: error invoking ‘nvcc --preprocess -arch sm_86 -I/home/david/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.8/site-packages/pycuda/cuda /tmp/tmpk4n1l5_d.cu --compiler-options -P’: [Errno 2] No such file or directory: ‘nvcc’