Hi
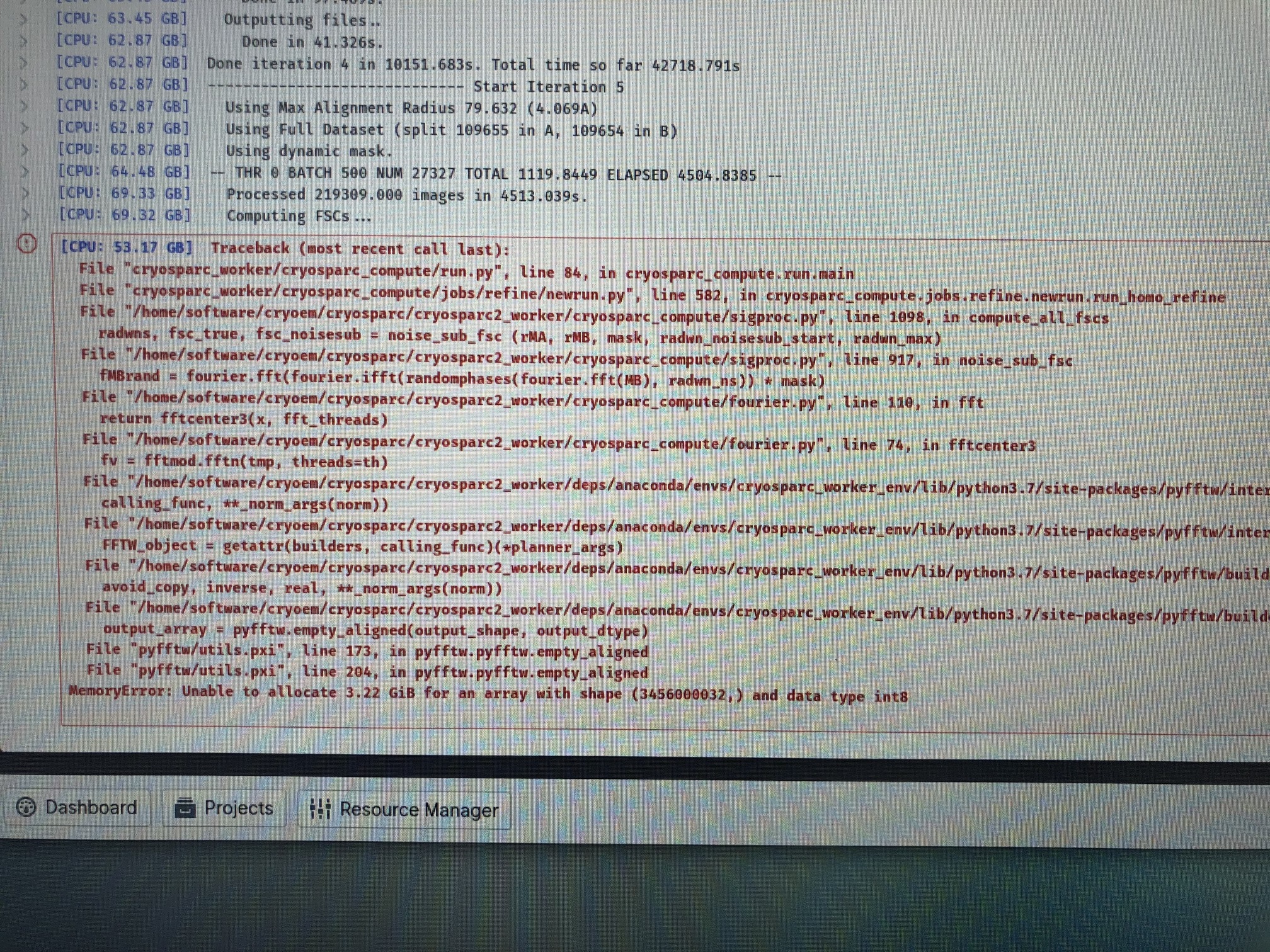
I saw the issue related to a new non-uniform refinement program but it looks like my problem is slightly different, I am creating a new topic here. New non-uniform refinement failed after 5-6 iterations - please see the picture. It looks like it is a memory issue but we have enough space (10 TB) in drive and I don’t know what to do. Iteration stopped at 5-6 but the map we got is better than the one we got using legacy NU refinement program - so we really want to get this program to work to a completion.
just for the information:
Hi Thanks for your prompted response. Here is the traceback:
[CPU: 53.17 GB] **Traceback (most recent call last): File "cryosparc_worker/cryosparc_compute/run.py", line 84, in cryosparc_compute.run.main File "cryosparc_worker/cryosparc_compute/jobs/refine/newrun.py", line 582, in cryosparc_compute.jobs.refine.newrun.run_homo_refine File "/home/software/cryoem/cryosparc/cryosparc2_worker/cryosparc_compute/sigproc.py", line 1098, in compute_all_fscs radwns, fsc_true, fsc_noisesub = noise_sub_fsc (rMA, rMB, mask, radwn_noisesub_start, radwn_max) File "/home/software/cryoem/cryosparc/cryosparc2_worker/cryosparc_compute/sigproc.py", line 917, in noise_sub_fsc fMBrand = fourier.fft(fourier.ifft(randomphases(fourier.fft(MB), radwn_ns)) * mask) File "/home/software/cryoem/cryosparc/cryosparc2_worker/cryosparc_compute/fourier.py", line 110, in fft return fftcenter3(x, fft_threads) File "/home/software/cryoem/cryosparc/cryosparc2_worker/cryosparc_compute/fourier.py", line 74, in fftcenter3 fv = fftmod.fftn(tmp, threads=th) File "/home/software/cryoem/cryosparc/cryosparc2_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.7/site-packages/pyfftw/interfaces/numpy_fft.py", line 169, in fftn calling_func, **_norm_args(norm)) File "/home/software/cryoem/cryosparc/cryosparc2_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.7/site-packages/pyfftw/interfaces/_utils.py", line 128, in _Xfftn FFTW_object = getattr(builders, calling_func)(*planner_args) File "/home/software/cryoem/cryosparc/cryosparc2_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.7/site-packages/pyfftw/builders/builders.py", line 382, in fftn avoid_copy, inverse, real, **_norm_args(norm)) File "/home/software/cryoem/cryosparc/cryosparc2_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.7/site-packages/pyfftw/builders/_utils.py", line 197, in _Xfftn output_array = pyfftw.empty_aligned(output_shape, output_dtype) File "pyfftw/utils.pxi", line 173, in pyfftw.pyfftw.empty_aligned File "pyfftw/utils.pxi", line 204, in pyfftw.pyfftw.empty_aligned MemoryError: Unable to allocate 3.22 GiB for an array with shape (3456000032,) and data type int8**
Is it possible if you can run the following command on your worker node and paste the output here: lscpu && free -g && uname -a && nvidia-smi && ulimit -l
The job was trying to use 69GB at the time when it crashed - it seems most likely that the system just ran out of RAM. Do you know what is using most of the system RAM? You can check using for example htop
We have been having some similar problems, one thing that seemed to help was to change the Cache quota (MB) from 10Gb to 2Tb…we thought it was a bug in CryoSPARC (why wasn’t it deleting old files to make room in the cache?) but we realized after thinking about how much data we were working with that there may not have been enough room to keep everything on the cache.
A side note - I can’t remember right now if this is CSPARC or RELION, or if this is true at all, but I think with Fourier padding, any of the jobs which do calculations in f-space may actually need 4-times as much cpu space (2^2) than you would expect. This might explain why some jobs can handle the large files size but others cannot.
Thanks for sharing your experience. It sounds like increasing cache quota will be the way to go. But I am not a computer geek. What should I do to change the cache quota ? Any Linux link to look at the instruction? Thanks
Honestly I have no idea if it will help, now that I look at our error messages the one that the cache fixed was different - the one related to yours looks like it has more to do with the GPU / CUDA versions as @apunjani has asked you for (and as is presented in other posts).
However, to solve this error: ReadTimeout: HTTPConnectionPool(host='hitergpu03.mskcc.org', port=39002): Read timed out. (read timeout=300)
increasing cryoSPARCs --ssdquota parameter as described here seemed to help.
Thanks Alex for the information. This is a quick follow-up regarding the problem I encountered for a new NU refinement program.
In the end, I found that there was no swap space set up. So, I added 16G of swap space, which solved the memory issue problem running a new NU-refinement program.
Hi, what do you mean by swap space? How did you add it?
I have the same problem - it seems that in local non-uniform refinement in CS3.0.1 the CPU memory requirement just grows and grows with each iteration, far beyond what CS requested from SLURM. So it crashes pretty quickly, even if far more memory is hard-allocated.
Thanks for any info!
Leonid
Hi Leonid
Just to be clear: I am not a computer expert - I am literally learning Linux on the fly every time I encounter the problem with CS or other EM programs. Apparently, swap space can be allocated from the portion of hard drive, which will supplement memory space when RAM runs out. So, I allocated 4GB to swap space into our Linux workstation and then I added an additional 16GB to it. Once I did it, there has been no crash of a new NU refinement due to memory shortage. We use Centos 7. You can find how to create swap space in the link something like this: https://www.netweaver.uk/create-swap-file-centos-7/