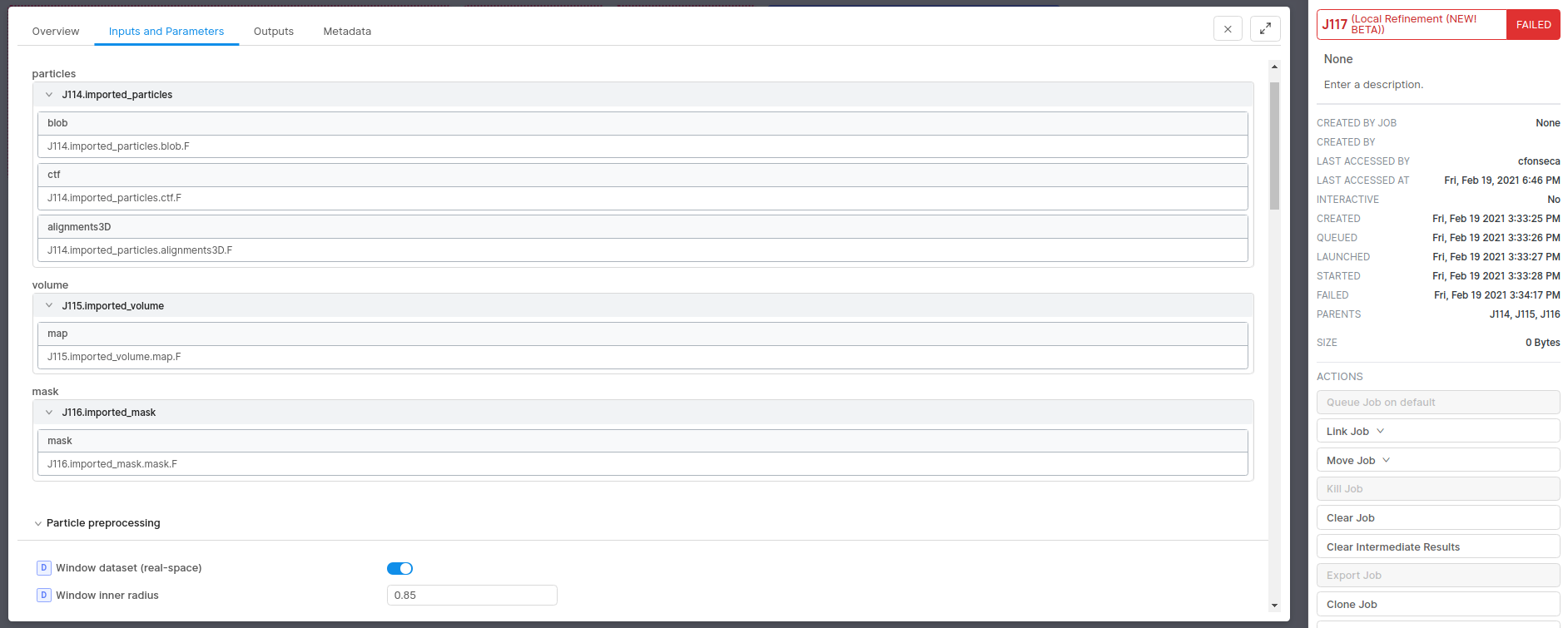
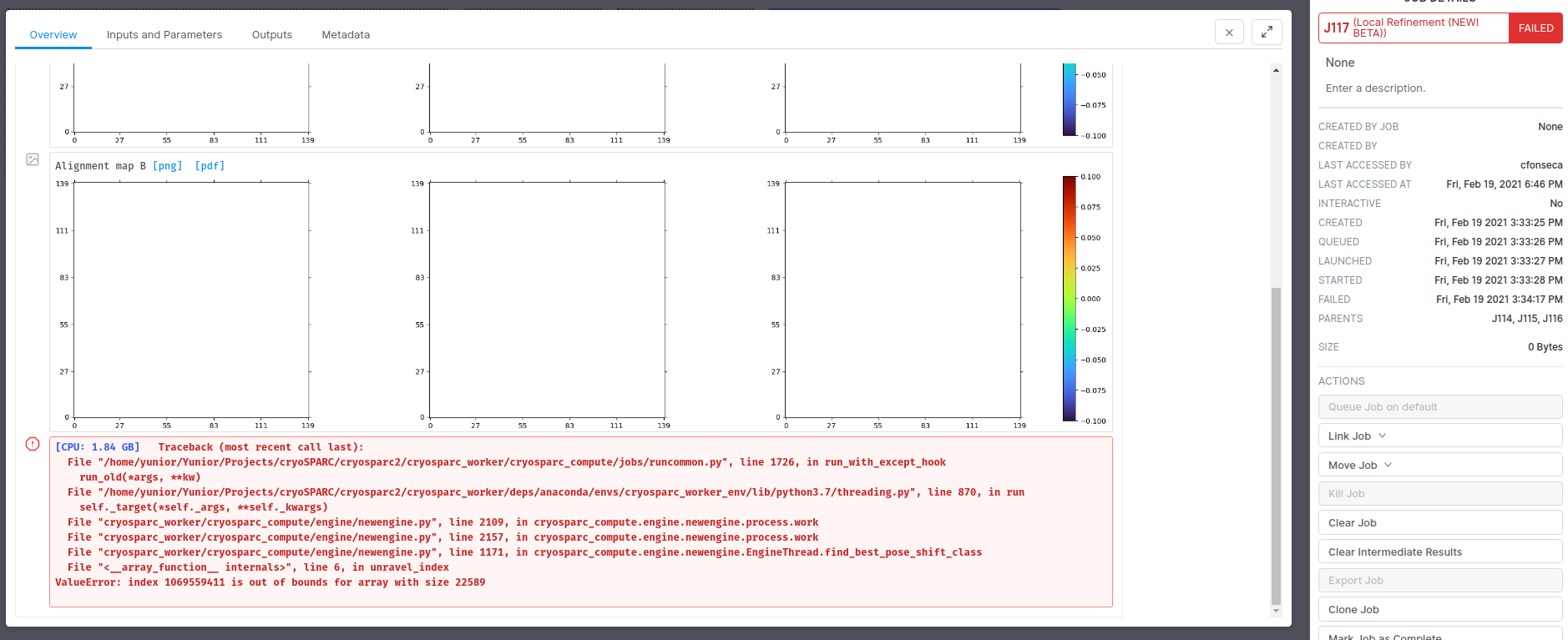
I’m trying to do a new local refinement. The job fails after the iteration 0. I haven’t had this issue with the old local refinement:
[CPU: 1.95 GB] Traceback (most recent call last):
File "/home/yunior/Yunior/Projects/cryoSPARC/cryosparc2/cryosparc_worker/cryosparc_compute/jobs/runcommon.py", line 1726, in run_with_except_hook
run_old(*args, **kw)
File "/home/yunior/Yunior/Projects/cryoSPARC/cryosparc2/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.7/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "cryosparc_worker/cryosparc_compute/engine/newengine.py", line 2109, in cryosparc_compute.engine.newengine.process.work
File "cryosparc_worker/cryosparc_compute/engine/newengine.py", line 2157, in cryosparc_compute.engine.newengine.process.work
File "cryosparc_worker/cryosparc_compute/engine/newengine.py", line 1171, in cryosparc_compute.engine.newengine.EngineThread.find_best_pose_shift_class
File "<__array_function__ internals>", line 6, in unravel_index
ValueError: index 1069559411 is out of bounds for array with size 22589