Hi, for example, when I am going to execute this command: cryosparcm cli ‘enqueue_job(“P34”,“J30”,“default”, False, [0,1, 2])’, in theory, cryosparc should execute that job in the GPUs that are indicated, in this case 0, 1 and 2, however, it was always executed in the GPU 0. I have the version v2.14.2. Any idea why this happens?
Hi, spunjani, this happens to me with all jobs. Sometimes I specify that they launch with GPU 1 and 2, and it activates GPU 0.
For example:
cryosparcm cli ‘make_job(“nonuniform_refine”,“P35”,“W29”, “Yunior Fonseca”, “None”, “None”, {“locres_use_mask”: “True”, “refine_symmetry_do_align”: “True”, “refine_noise_init_sigmascale”: “3”, “locres_stop_subsampling”: “5”, “use_monores”: “False”, “refine_num_final_iterations”: “0”, “refine_batchsize_epsilon”: “0.001”, “refine_res_init”: “30”, “refine_skip_premult”: “True”, “refine_scale_start_iter”: “0”, “refine_dynamic_mask_use_abs”: “False”, “use_phenix_sharpen”: “False”, “locres_cap”: “False”, “refine_clip”: “False”, “refine_do_init_scale_est”: “True”, “locres_zeropad_factor”: “2.0”, “refine_scale_min”: “False”, “locres_compute_facility”: “GPU”, “refine_noise_initw”: “200”, “refine_minisize”: “2000”, “locres_anneal_factor”: “0.0”, “refine_mask”: “dynamic”, “refine_dynamic_mask_thresh_factor”: “0.2”, “refine_dynamic_mask_far_ang”: “14.0”, “refine_window”: “True”, “refine_batchsize_snrfactor”: “40.0”, “refine_scale_ctf_use_current”: “False”, “refine_symmetry”: “C1”, “refine_locproc_start_res”: “8.0”, “locres_step_size”: “2”, “refine_scale_align_use_prev”: “False”, “refine_batchsize_init”: “0”, “refine_res_gsfsc_split”: “20”, “cross_validation”: “True”, “localfilter_kernel_type”: “lanczos”, “refine_dynamic_mask_near_ang”: “6.0”, “locres_awf”: “6”, “refine_dynamic_mask_start_res”: “12”, “locres_fsc_thresh”: “0.5”, “temporal_locres”: “False”, “locres_fsc_weighting”: “False”, “compute_use_ssd”: “None”, “refine_noise_model”: “symmetric”, “refine_early_stopping”: “1”, “refine_ignore_dc”: “True”, “extra_sharpen”: “False”, “refine_noise_priorw”: “50”}, {“particles”: “J73.imported_particles”, “volume”: “J80.imported_volume.map”})’
After thats,
cryosparcm cli ‘enqueue_job(“P35”,“J85”,“default”, False, [1,2])’
And then, when I check the GPU use(nvidia-smi), only GPU 0 is in use…
…
My question is this. Cryosparc parallelizes jobs, or is this parameter only to choose an available GPU from the list?
Hi @cfonseca
Not all jobs can be parallelized over multiple GPUs. The ones you can do this for are motion correction, CTF estimation, particle extraction and you can also use multiple GPUs in 2D classification.
In all cases the job has to have a “Number of GPUs to parallelize” parameter:
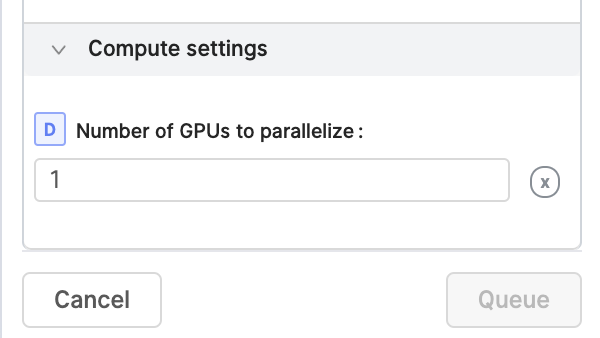
So you would have to set that parameter to a value greater than 1, to tell the job that it should use all the GPUs. For example, set it to 3 for 3 GPUs. I hope this helps!
1 Like
Thanks spunjani, yes, I understand you. In the case of 2D classification and other protocols, this parameter is found, but could you tell me if in the refinements or the abinitio jobs, I can parallelize them in several GPUs? What is the criteria to choose in the command, for example: cryosparcm cli ‘enqueue_job (“ P35 ”,“ J85 ”,“ default ”, False, [1,2])’ for jobs that do not parallel the gpus?
@stephan I’ve been seeing this same behavior where no matter what I select for GPU usage it always stays with GPU 0 even though I have 4 and I selected to use 3 for the job.
Hi everyone, something else do when queuing to a specific GPU is to specify a worker hostname in place of the fourth False argument in the posted examples. The third lane argument may be left unspecified (False)
Here’s an example with my setup:
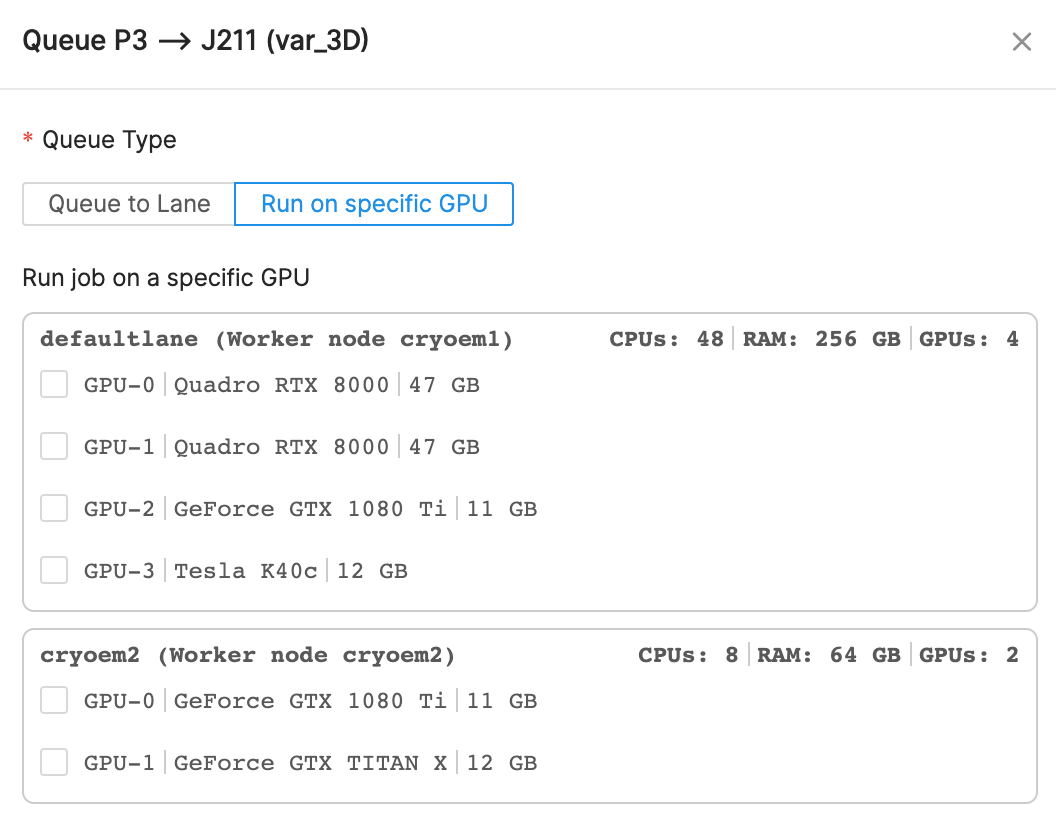
I have a lane called defaultlane. To this lane I added a worker node with hostname cryoem1 and 4 GPUs.
Here’s the full enqueue_job signature:
enqueue_job(project_uid, job_uid, lane=False, hostname=False, gpus=False, no_check_inputs_ready=False)
To queue to GPU-3 on defaultlane, I have to specify the hostname cryoem1:
cryosparcm cli "enqueue_job(project_uid='P3', job_uid='J211', hostname='cryoem1', gpus=[3])"
Hope that helps.
Hi nfrasser, I’m wondering how to have all these defaultlane information on my “Run on specific GPU” page.