Hi there, we have a cryosparc instance hosted on our university computing facility. The setup uses a virtual machine to host the cryosparc master, and the Slurm job scheduler to distribute the computing requests to different cryosparc workers. The virtual machine is configured with 8 CPU and 24GB of memory. Things are working quite well in general; however, we experience memory issues on the cryosparc master periodically.
The issues involve interactive job types running on only the master lane, most notably “inspect particle picks”, “select 2D classes”, and “manually curate exposures” because it is quite common for us to have 10k+ micrographs and 10M+ particles ![]() .
.
Below are two examples of the error message:
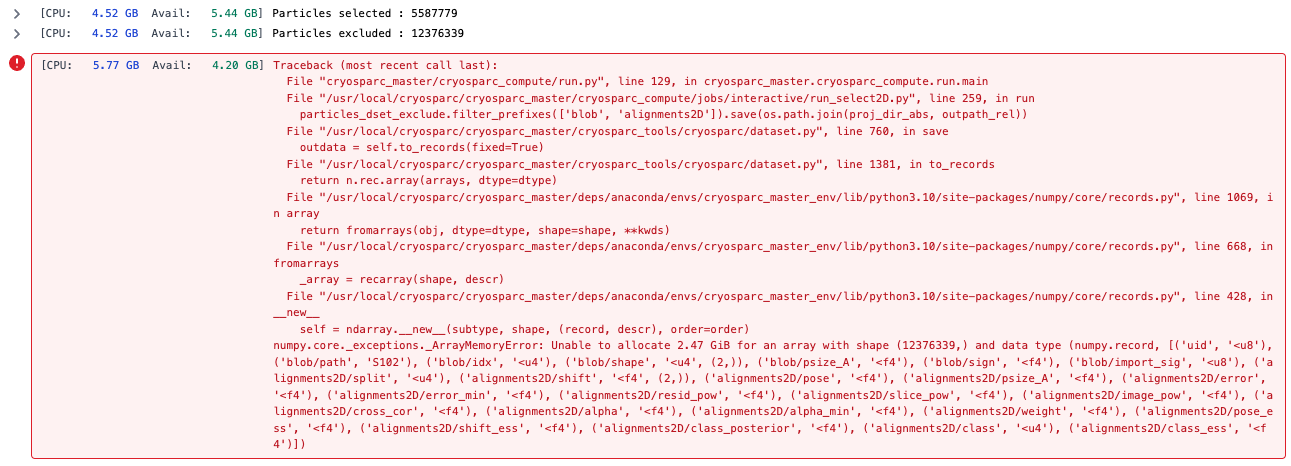
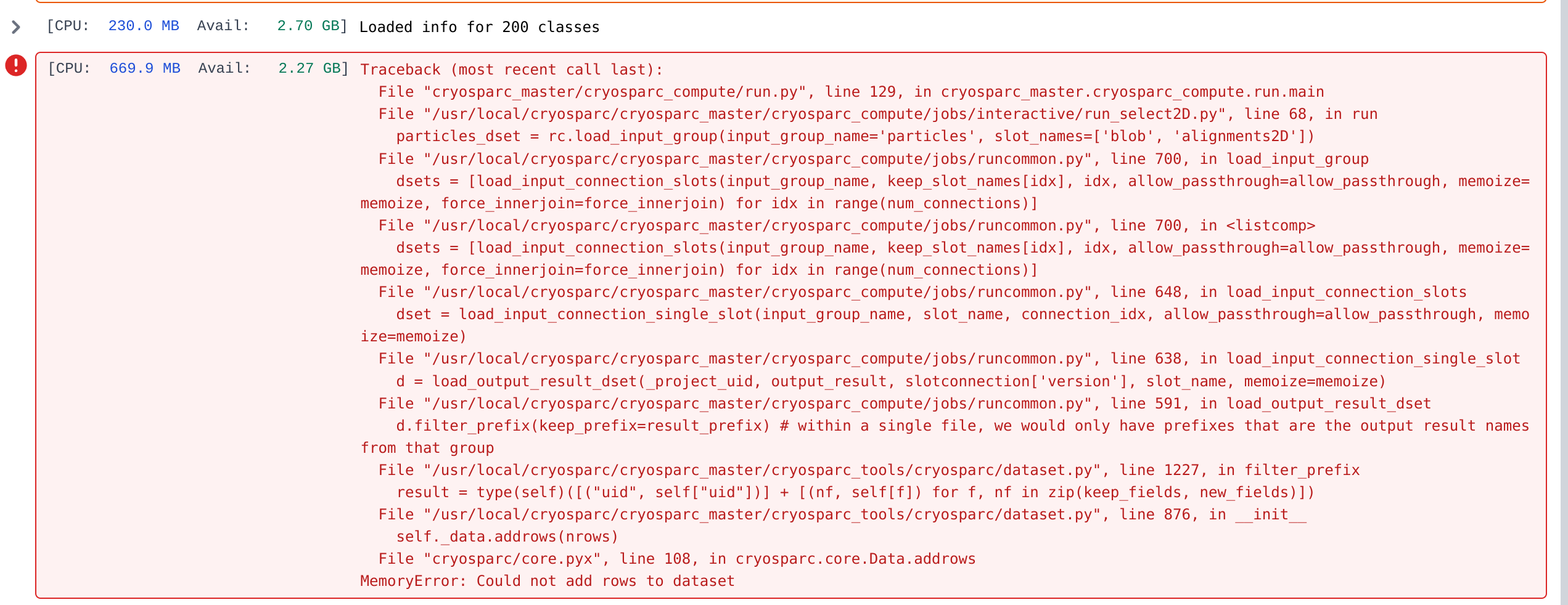
When facing this type of error, our solution is to restart the VM. After all, that was how NASA fixed the Hubble gyroscope.
Admittedly, this is not satisfying. And to improve the situation, here are the questions for the cryosparc dev team.
-
It seems that cryosparc master always ask for 1 CPU and 24 GB of memory for these interactive job, which is based on job queuing page (pasted below). But how cryosparc master manages the available memory? As you can see from the error message above, the available memory can be between 3 GB and 10 GB.
-
Is it possible to make these interactive jobs run on cryosparc workers as well, as the workers usually have access to much more memory?

Thank you for your help!