Hi everyone, I am running the new combined version of cryosparc on a supercomputer in our University. A recent update seems have combined cryosparc master and cryosparc localworker ( the local worker is now called default lane or master node).
I found the ‘master node’ only shows up in ‘import movie’ job but for all other jobs, only the cluster nodes are shown there. Does anyone have any clue how to fix this?
Welcome to the forum @Chuanqi.
Please can you post
- the outputs of these commands on the CryoSPARC master computer
hostname -f cryosparcm call env | grep HOSTNAME cryosparcm cli "get_scheduler_targets()" - a screenhot of the UI showing the queuing choices for Import Movies
- an equivalent screenshot for one of the other jobs
- bun077.hpc.net.uq.edu.au
- HOSTNAME=bun077
CRYOSPARC_FORCE_HOSTNAME=true
CRYOSPARC_HOSTNAME_CHECK=bun077.hpc.net.uq.edu.au
CRYOSPARC_MASTER_HOSTNAME=bun077 -
[{'cache_path': '/scratch/project/kobe_mamm/chuanqih/ssdcache/', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'custom_var_names': [], 'custom_vars': {}, 'desc': None, 'hostname': 'A100.10gb.MIG', 'lane': 'A100.10gb.MIG', 'name': 'A100.10gb.MIG', 'qdel_cmd_tpl': 'scancel {{ cluster_job_id }}', 'qinfo_cmd_tpl': 'sinfo', 'qstat_cmd_tpl': 'squeue -j {{ cluster_job_id }}', 'qstat_code_cmd_tpl': 'squeue -j {{ cluster_job_id }} --format=%T -h', 'qsub_cmd_tpl': 'sbatch {{ script_path_abs }}', 'script_tpl': '#!/usr/bin/env bash\n#### cryoSPARC cluster submission script template for SLURM\n## Available variables:\n## {{ run_cmd }} - the complete command string to run the job\n## {{ num_cpu }} - the number of CPUs needed\n## {{ num_gpu }} - the number of GPUs needed. \n## Note: the code will use this many GPUs starting from dev id 0\n## the cluster scheduler or this script have the responsibility\n## of setting CUDA_VISIBLE_DEVICES so that the job code ends up\n## using the correct cluster-allocated GPUs.\n## {{ ram_gb }} - the amount of RAM needed in GB\n## {{ job_dir_abs }} - absolute path to the job directory\n## {{ project_dir_abs }} - absolute path to the project dir\n## {{ job_log_path_abs }} - absolute path to the log file for the job\n## {{ worker_bin_path }} - absolute path to the cryosparc worker command\n## {{ run_args }} - arguments to be passed to cryosparcw run\n## {{ project_uid }} - uid of the project\n## {{ job_uid }} - uid of the job\n## {{ job_creator }} - name of the user that created the job (may contain spaces)\n## {{ cryosparc_username }} - cryosparc username of the user that created the job (usually an email)\n##\n## What follows is a simple SLURM script:\n\n#SBATCH --job-name cryosparc_{{ project_uid }}_{{ job_uid }}\n#SBATCH -n 1\n#SBATCH -c {{ num_cpu }}\n#SBATCH --account=a_kobe\n#SBATCH --gres=gpu:nvidia_a100_80gb_pcie_1g.10gb:{{ num_gpu }}\n#SBATCH --partition=gpu_cuda\n#SBATCH --time=12:00:00\n#SBATCH --mem={{ (ram_gb*4000)|int }}MB\n#SBATCH --output={{ job_log_path_abs }}\n#SBATCH --error={{ job_log_path_abs }}\n\n{{ run_cmd }}\n\n', 'send_cmd_tpl': '{{ command }}', 'title': 'A100.10gb.MIG', 'tpl_vars': ['num_cpu', 'ram_gb', 'job_uid', 'cluster_job_id', 'job_log_path_abs', 'cryosparc_username', 'job_creator', 'project_uid', 'num_gpu', 'command', 'run_cmd', 'project_dir_abs', 'run_args', 'job_dir_abs', 'worker_bin_path'], 'type': 'cluster', 'worker_bin_path': '/home/uqchuan/cryosparc/cryosparc_worker/bin/cryosparcw'}, {'cache_path': '/scratch/project/kobe_mamm/chuanqih/ssdcache/', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'custom_var_names': [], 'custom_vars': {}, 'desc': None, 'hostname': 'A100', 'lane': 'A100', 'name': 'A100', 'qdel_cmd_tpl': 'scancel {{ cluster_job_id }}', 'qinfo_cmd_tpl': 'sinfo', 'qstat_cmd_tpl': 'squeue -j {{ cluster_job_id }}', 'qstat_code_cmd_tpl': 'squeue -j {{ cluster_job_id }} --format=%T -h', 'qsub_cmd_tpl': 'sbatch {{ script_path_abs }}', 'script_tpl': '#!/usr/bin/env bash\n#### cryoSPARC cluster submission script template for SLURM\n## Available variables:\n## {{ run_cmd }} - the complete command string to run the job\n## {{ num_cpu }} - the number of CPUs needed\n## {{ num_gpu }} - the number of GPUs needed. \n## Note: the code will use this many GPUs starting from dev id 0\n## the cluster scheduler or this script have the responsibility\n## of setting CUDA_VISIBLE_DEVICES so that the job code ends up\n## using the correct cluster-allocated GPUs.\n## {{ ram_gb }} - the amount of RAM needed in GB\n## {{ job_dir_abs }} - absolute path to the job directory\n## {{ project_dir_abs }} - absolute path to the project dir\n## {{ job_log_path_abs }} - absolute path to the log file for the job\n## {{ worker_bin_path }} - absolute path to the cryosparc worker command\n## {{ run_args }} - arguments to be passed to cryosparcw run\n## {{ project_uid }} - uid of the project\n## {{ job_uid }} - uid of the job\n## {{ job_creator }} - name of the user that created the job (may contain spaces)\n## {{ cryosparc_username }} - cryosparc username of the user that created the job (usually an email)\n##\n## What follows is a simple SLURM script:\n\n#SBATCH --job-name cryosparc_{{ project_uid }}_{{ job_uid }}\n#SBATCH -n 1\n#SBATCH -c {{ num_cpu }}\n#SBATCH --account=a_kobe\n#SBATCH --gres=gpu:a100:{{ num_gpu }}\n#SBATCH --partition=gpu_cuda\n#SBATCH --time=12:00:00\n#SBATCH --mem={{ (ram_gb*4000)|int }}MB\n#SBATCH --output={{ job_log_path_abs }}\n#SBATCH --error={{ job_log_path_abs }}\n\n{{ run_cmd }}\n\n', 'send_cmd_tpl': '{{ command }}', 'title': 'A100', 'tpl_vars': ['num_cpu', 'ram_gb', 'job_uid', 'cluster_job_id', 'job_log_path_abs', 'cryosparc_username', 'job_creator', 'project_uid', 'num_gpu', 'command', 'run_cmd', 'project_dir_abs', 'run_args', 'job_dir_abs', 'worker_bin_path'], 'type': 'cluster', 'worker_bin_path': '/home/uqchuan/cryosparc/cryosparc_worker/bin/cryosparcw'}, {'cache_path': '/scratch/project/kobe_mamm/chuanqih/ssdcache/', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'custom_var_names': [], 'custom_vars': {}, 'desc': None, 'hostname': 'H100', 'lane': 'H100', 'name': 'H100', 'qdel_cmd_tpl': 'scancel {{ cluster_job_id }}', 'qinfo_cmd_tpl': 'sinfo', 'qstat_cmd_tpl': 'squeue -j {{ cluster_job_id }}', 'qstat_code_cmd_tpl': 'squeue -j {{ cluster_job_id }} --format=%T -h', 'qsub_cmd_tpl': 'sbatch {{ script_path_abs }}', 'script_tpl': '#!/usr/bin/env bash\n#### cryoSPARC cluster submission script template for SLURM\n## Available variables:\n## {{ run_cmd }} - the complete command string to run the job\n## {{ num_cpu }} - the number of CPUs needed\n## {{ num_gpu }} - the number of GPUs needed. \n## Note: the code will use this many GPUs starting from dev id 0\n## the cluster scheduler or this script have the responsibility\n## of setting CUDA_VISIBLE_DEVICES so that the job code ends up\n## using the correct cluster-allocated GPUs.\n## {{ ram_gb }} - the amount of RAM needed in GB\n## {{ job_dir_abs }} - absolute path to the job directory\n## {{ project_dir_abs }} - absolute path to the project dir\n## {{ job_log_path_abs }} - absolute path to the log file for the job\n## {{ worker_bin_path }} - absolute path to the cryosparc worker command\n## {{ run_args }} - arguments to be passed to cryosparcw run\n## {{ project_uid }} - uid of the project\n## {{ job_uid }} - uid of the job\n## {{ job_creator }} - name of the user that created the job (may contain spaces)\n## {{ cryosparc_username }} - cryosparc username of the user that created the job (usually an email)\n##\n## What follows is a simple SLURM script:\n\n#SBATCH --job-name cryosparc_{{ project_uid }}_{{ job_uid }}\n#SBATCH -n 1\n#SBATCH -c {{ num_cpu }}\n#SBATCH --account=a_kobe\n#SBATCH --gres=gpu:h100:{{ num_gpu }}\n#SBATCH --partition=gpu_cuda\n#SBATCH --time=12:00:00\n#SBATCH --mem={{ (ram_gb*4000)|int }}MB\n#SBATCH --output={{ job_log_path_abs }}\n#SBATCH --error={{ job_log_path_abs }}\n\n{{ run_cmd }}\n\n', 'send_cmd_tpl': '{{ command }}', 'title': 'H100', 'tpl_vars': ['num_cpu', 'ram_gb', 'job_uid', 'cluster_job_id', 'job_log_path_abs', 'cryosparc_username', 'job_creator', 'project_uid', 'num_gpu', 'command', 'run_cmd', 'project_dir_abs', 'run_args', 'job_dir_abs', 'worker_bin_path'], 'type': 'cluster', 'worker_bin_path': '/home/uqchuan/cryosparc/cryosparc_worker/bin/cryosparcw'}, {'cache_path': '/scratch/user/uqchuan/tmp/cryosparc/ssd', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'custom_var_names': [], 'custom_vars': {}, 'desc': None, 'hostname': 'A100_1d', 'lane': 'A100_1d', 'name': 'A100_1d', 'qdel_cmd_tpl': 'scancel {{ cluster_job_id }}', 'qinfo_cmd_tpl': 'sinfo', 'qstat_cmd_tpl': 'squeue -j {{ cluster_job_id }}', 'qstat_code_cmd_tpl': 'squeue -j {{ cluster_job_id }} --format=%T -h', 'qsub_cmd_tpl': 'sbatch {{ script_path_abs }}', 'script_tpl': '#!/usr/bin/env bash\n#### cryoSPARC cluster submission script template for SLURM\n## Available variables:\n## {{ run_cmd }} - the complete command string to run the job\n## {{ num_cpu }} - the number of CPUs needed\n## {{ num_gpu }} - the number of GPUs needed. \n## Note: the code will use this many GPUs starting from dev id 0\n## the cluster scheduler or this script have the responsibility\n## of setting CUDA_VISIBLE_DEVICES so that the job code ends up\n## using the correct cluster-allocated GPUs.\n## {{ ram_gb }} - the amount of RAM needed in GB\n## {{ job_dir_abs }} - absolute path to the job directory\n## {{ project_dir_abs }} - absolute path to the project dir\n## {{ job_log_path_abs }} - absolute path to the log file for the job\n## {{ worker_bin_path }} - absolute path to the cryosparc worker command\n## {{ run_args }} - arguments to be passed to cryosparcw run\n## {{ project_uid }} - uid of the project\n## {{ job_uid }} - uid of the job\n## {{ job_creator }} - name of the user that created the job (may contain spaces)\n## {{ cryosparc_username }} - cryosparc username of the user that created the job (usually an email)\n##\n## What follows is a simple SLURM script:\n\n#SBATCH --job-name cryosparc_{{ project_uid }}_{{ job_uid }}\n#SBATCH -n 1\n#SBATCH -c {{ num_cpu }}\n#SBATCH --account=a_kobe\n#SBATCH --gres=gpu:a100:{{ num_gpu }}\n#SBATCH --partition=gpu_cuda\n#SBATCH --mem=80000MB\n##SBATCH --mem={{ (ram_gb*15000)|int }}MB\n#SBATCH --output={{ job_log_path_abs }}\n#SBATCH --error={{ job_log_path_abs }}\n#SBATCH --time=01:00:00\n\n{{ run_cmd }}\n\n', 'send_cmd_tpl': '{{ command }}', 'title': 'A100_1d', 'tpl_vars': ['num_cpu', 'ram_gb', 'job_uid', 'cluster_job_id', 'job_log_path_abs', 'cryosparc_username', 'job_creator', 'project_uid', 'num_gpu', 'command', 'run_cmd', 'project_dir_abs', 'run_args', 'job_dir_abs', 'worker_bin_path'], 'type': 'cluster', 'worker_bin_path': '/home/uqchuan/cryosparc/cryosparc_worker/bin/cryosparcw'}, {'cache_path': '/scratch/project/kobe_mamm/chuanqih/ssdcache/', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'custom_var_names': [], 'custom_vars': {}, 'desc': None, 'hostname': 'L40', 'lane': 'L40', 'name': 'L40', 'qdel_cmd_tpl': 'scancel {{ cluster_job_id }}', 'qinfo_cmd_tpl': 'sinfo', 'qstat_cmd_tpl': 'squeue -j {{ cluster_job_id }}', 'qstat_code_cmd_tpl': 'squeue -j {{ cluster_job_id }} --format=%T -h', 'qsub_cmd_tpl': 'sbatch {{ script_path_abs }}', 'script_tpl': '#!/usr/bin/env bash\n#### cryoSPARC cluster submission script template for SLURM\n## Available variables:\n## {{ run_cmd }} - the complete command string to run the job\n## {{ num_cpu }} - the number of CPUs needed\n## {{ num_gpu }} - the number of GPUs needed. \n## Note: the code will use this many GPUs starting from dev id 0\n## the cluster scheduler or this script have the responsibility\n## of setting CUDA_VISIBLE_DEVICES so that the job code ends up\n## using the correct cluster-allocated GPUs.\n## {{ ram_gb }} - the amount of RAM needed in GB\n## {{ job_dir_abs }} - absolute path to the job directory\n## {{ project_dir_abs }} - absolute path to the project dir\n## {{ job_log_path_abs }} - absolute path to the log file for the job\n## {{ worker_bin_path }} - absolute path to the cryosparc worker command\n## {{ run_args }} - arguments to be passed to cryosparcw run\n## {{ project_uid }} - uid of the project\n## {{ job_uid }} - uid of the job\n## {{ job_creator }} - name of the user that created the job (may contain spaces)\n## {{ cryosparc_username }} - cryosparc username of the user that created the job (usually an email)\n##\n## What follows is a simple SLURM script:\n\n#SBATCH --job-name cryosparc_{{ project_uid }}_{{ job_uid }}\n#SBATCH -n 1\n#SBATCH -c {{ num_cpu }}\n#SBATCH --account=a_kobe\n#SBATCH --gres=gpu:l40:{{ num_gpu }}\n#SBATCH --partition=gpu_cuda\n#SBATCH --time=12:00:00\n#SBATCH --mem={{ (ram_gb*4000)|int }}MB\n#SBATCH --output={{ job_log_path_abs }}\n#SBATCH --error={{ job_log_path_abs }}\n\n{{ run_cmd }}\n\n', 'send_cmd_tpl': '{{ command }}', 'title': 'L40', 'tpl_vars': ['num_cpu', 'ram_gb', 'job_uid', 'cluster_job_id', 'job_log_path_abs', 'cryosparc_username', 'job_creator', 'project_uid', 'num_gpu', 'command', 'run_cmd', 'project_dir_abs', 'run_args', 'job_dir_abs', 'worker_bin_path'], 'type': 'cluster', 'worker_bin_path': '/home/uqchuan/cryosparc/cryosparc_worker/bin/cryosparcw'}]
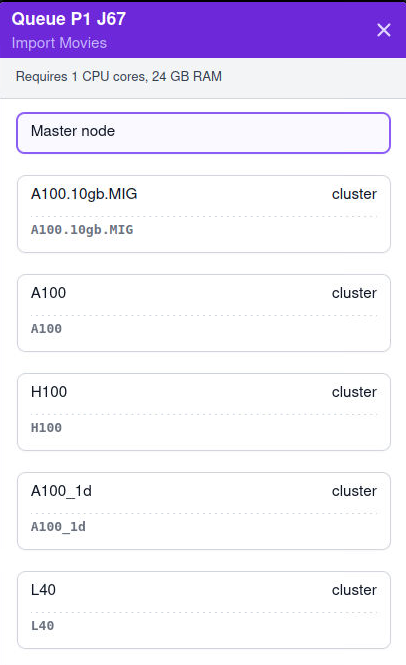
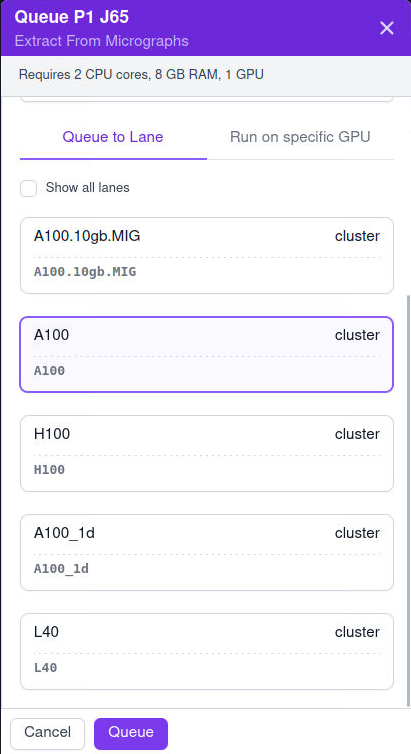
Thank you for looking into my instance @wtempel. As you see, the ‘master node’ is only available for import movies job.
@Chuanqi Based on the configuration you posted (all scheduler targets are of "type": "cluster"), the behavior you observed is expected.
If both of the following are true:
- SLURM will never allocate bun077.hpc.net.uq.edu.au to a cluster job
- and bun077.hpc.net.uq.edu.au meets the requirements for a CryoSPARC worker node
you can connect bun077.hpc.net.uq.edu.au as a node-type target and thereby make bun077.hpc.net.uq.edu.au available for queuing jobs via the CryoSPARC-builtin scheduler.
Before you go ahead with that, you may want to check whether CRYOSPARC_FORCE_HOSTNAME and CRYOSPARC_HOSTNAME_CHECK can be removed from the configuration if you redefine
CRYOSPARC_MASTER_HOSTNAME=bun077.hpc.net.uq.edu.au (inside cryosparc_master/config, CryoSPARC restart needed after changes to this file).
Only try this if all SLURM compute nodes and bun077 itself can correctly resolve the full bun077.hpc.net.uq.edu.au hostname.
Why?
-
If you essentially want to use bun077.hpc.net.uq.edu.au as a combined CryoSPARC master/worker, configuration is simplified if the
hostname -foutputCRYOSPARC_MASTER_HOSTNAMEvaluecryosparc_worker/bin/cryosparcw connect --workerparameter
all match.
-
CRYOSPARC_FORCE_HOSTNAMEandCRYOSPARC_HOSTNAME_CHECKhave the potential to cause confusion and disruption if used incorrectly, such as whencryosparcmis called on the wrong computer.