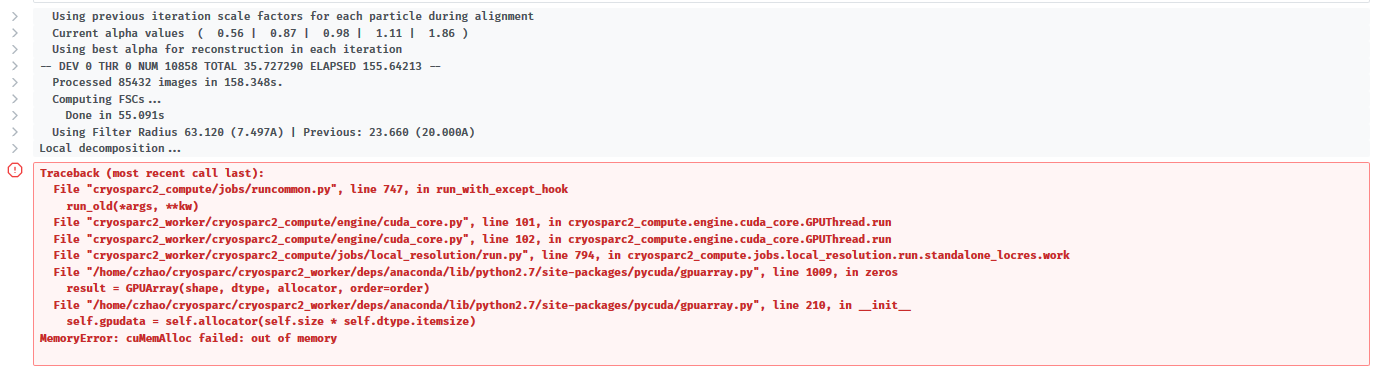
Only very recently, I started to encounter out of GPU memory error when running local refinement job with non-uniform refinement option turned on. The error (screenshot attached) occurs at iteration 0 during decomposition of the reference model.
My voxel size is 364 x 364 x 364, and I only have 85,432 particles (which might not be relevant). I have run much bigger jobs (600 x 600 x 600) before on the same machine (GeForce GTX 1080 Ti card) without any problems. And when I monitor the GPU memory usage using “nvidia-smi -l 1”, the highest usage before crash is less than 3 GB, which is much less than the total ~10 GB listed.
I have rebooted the machine and restarted cryosparc but the same error persists. Does anyone have any idea of how to solve this problem?
I have run some tests and I finally realized that this behavior might be a bug that are highly specific to certain cases. Here are the observations:
- Using a different set of particles, with same reference model and mask, no error.
- Using the same set of particles, same reference model and mask, but with a different starting poses for NU local refinement, no error.
- Using the same set of particles, same starting poses, same reference model and mask, but with a smaller local angular and translational search range, no error.
- However, using the same set of particles, same starting poses, default local search range, no matter what reference model and mask I tried, the out of memory error persists.
From these observations I feel that the error is not a real error but a bug (as I have mentioned earlier, I indeed never saw GPU memory usage went to even half the full size before the crash). I feel that the local decomposition step probably looks at a model directly reconstructed from the input particles with their poses, and that the local search range determines to some level how this reconstructed model is going to be looked at.
I would appreciate it if the developers could look at this bug to prevent it from happening.
Hi @chenzhao, thanks for reporting this in detail and sorry for the delay in responding. This is definitely a strange edge case… we will attempt to figure out the connection between the poses and memory usage, though it is unclear what that could be. Non-uniform refinement at the local decomposition stage does not really use the pose information of the particles, as it only operates on the maps themselves. However the memory usage is variable depending on the signal content of the map.
Given that it’s been a while, you’ve probably use one of the workarounds that you mentioned, but please let us know of any more issues.