I have an issue with our cluster configuration. We have updated to version 4.4.1 a while ago. Everything was running smoothly. We got some new GPU nodes which I wanted to add. Therefore, I adapted my template cluster_info.json and cluster_script.sh and executed cryosparcm cluster connect as always resulting in the following error (full error via PM):
TypeError: add_scheduler_target_cluster() got an unexpected keyword argument 'transfer_cmd_tpl'
cryosparcm cluster connect run successfully.
The jobs, however, are not getting submitted to the cluster anymore using the new lane.
Can somebody explain the behavior or is there a workaround for the new version?
Thanks a lot!
Here are the template cluster_files:
cluster_info.json
thank you for your fast reply and great questions with which I was able to figure it out myself.
The issues were the variables which was not that obvious but indicated by the command_core log.
After updating, the defaults for the variable were deleted since I did not hardcode them.
So I changed
I think they are not needed anymore, I will remove them now.
Thank you for the hint. So far, there were no problems. However, slurm properly assigns GPU ressources which probably makes the code block unneccessary in the future. I removed it now.
Thanks a lot!
Edit: I was noticing that it is not straight forward to setup up a multi-user cluster integration for cryosparc. We figured out a system where each user is able to submit cryosparc jobs with their own slurm user using a single master instance for everybody. In case it is interesting for others I could write a short documentation on how we set everything up. Just let me know.
I’m interested in learning more about how you set up a multi-user CryoSPARC cluster integration using a single master instance. I’ve seen your previous comment about this, and I was wondering if you’ve had a chance to write that documentation yet. If so, I’d be grateful if you could share it!
Can you give us a detailed description of how you set it up so that multiple users can use the same instance and the corresponding user can be displayed?
sorry I forgot about that/ and went too far down in my current to do list. I can give you now a short description and a detailed later (probably end of next week).
So, we installed the cryosparc master instance on a local server in our basement.
For computing, we are using our HPC cluster which is in another building due to security reasons.
There we have 40PB of cloud storage (long term), ~3PB scratch storage (short to mid term) where all of our gpu nodes have rwx access.
Basically, all cryosparc users from our group need an HPC account and an account in cryosparc with the same username.
Master instance and HPC cluster have the same unix account (identical name, group and id)
all cryosparc users are member of the same unix group (fruits)
The sudoes list needs to be edited to allow the master instance account (boss) to submit jobs for their group members boss ALL=(fruits) NOPASSWD: /usr/bin/sbatch, /usr/bin/scancel, /usr/bin/squeue, /usr/bin/sinfo
scratch and cloud spaces are mounted via a samba export on our master instance with the same path like on our HPC cluster.
the project directories are assigned to the users via chown (for quota calculation) but have rwx access for the boss account (for the master instance to access it).
To submit jobs in the name of the users, the cluster_info.json needs to be edited to:
where job_creator is the unix user on the HPC Cluster/cryosparc username (not the unix username under which the master instance is running).
I hope it already gives you an idea/ helps you with your setup.
Best,
Max
Thank you for sharing, but I believe that the sudoers file configuration is more than that
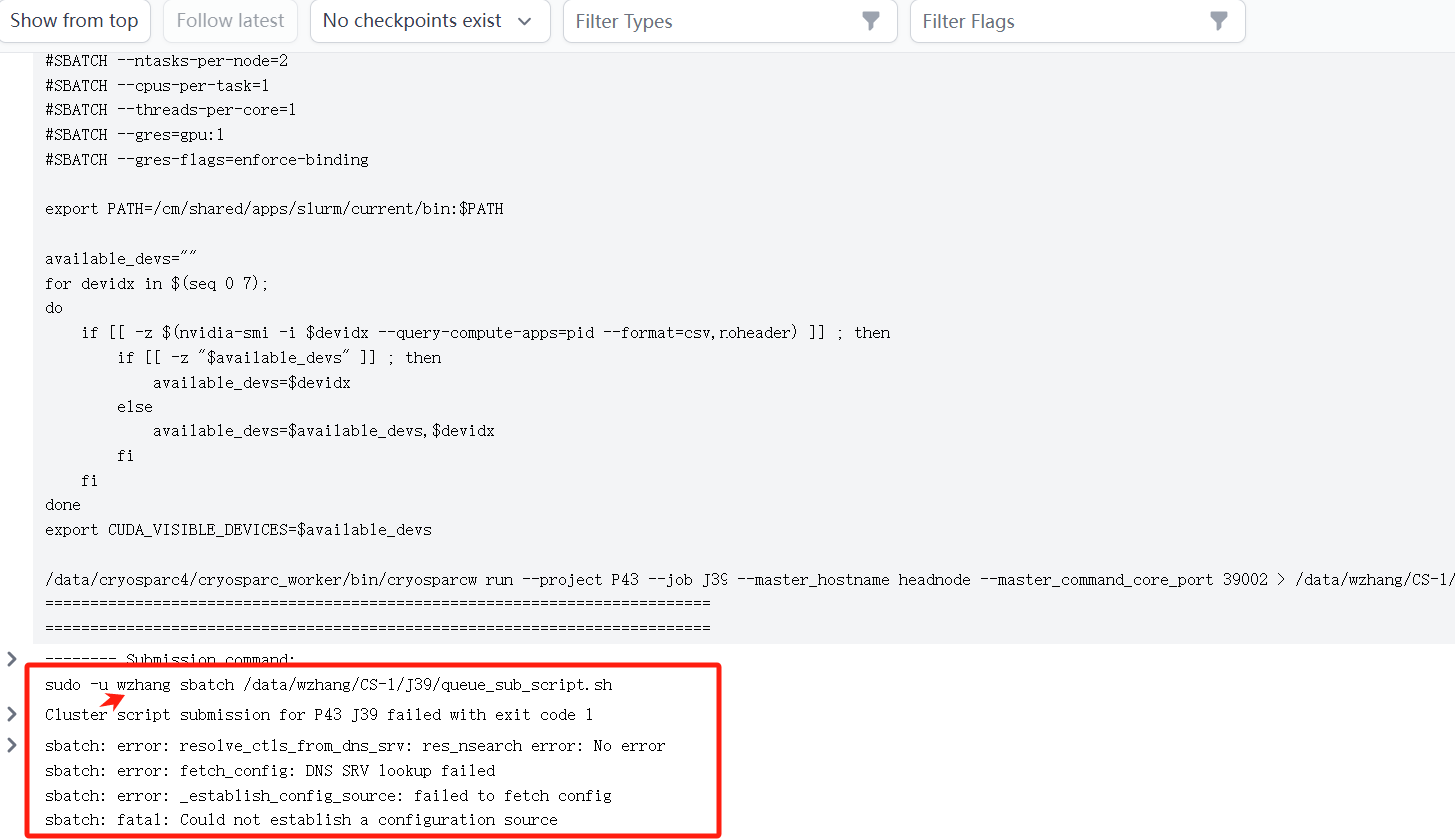
Because if you submit a task in this way, it will only retain some common variables such as /usr/bin, which will prompt that the slurm configuration file cannot be found. How did you do it?
Because in /etc/sudoer, only the environment variables specified in the file are configured
There are no problems with the previous ones. I also added the environment variables of our test cluster slurm in the sudoer file and submitted it, but the slurm configuration file content cannot be found, as shown in the figure
Using sudo in the cluster script template somewhat deviates from the intended operation of CryoSPARC under a non-privileged account (1, 2).
Please weigh any security implication carefully before deciding whether to use sudo within the script template.
I totally agree. This configuration should only be used if you know what you are doing. However, it does not allow for root rights. The allowed commands should be limited and only applied to a small group.