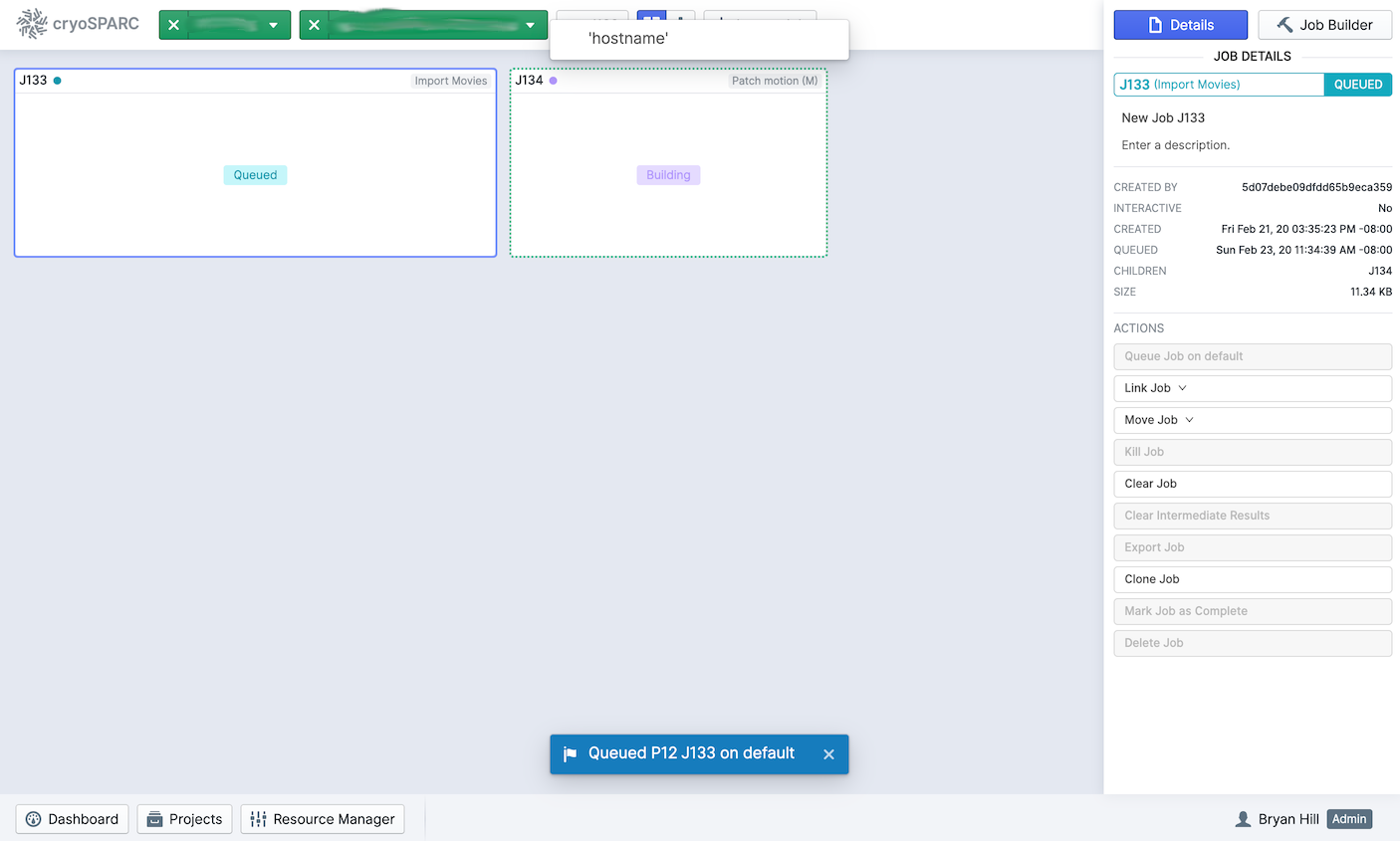
We’ve run into a strange issue where any job that is submitted, it will queue up but not run. The GUI (screenshot attached) briefly shows a dialog that says ‘hostname’ then the job will stay in the queue.
cryosparcm log command_core shows this repeatedly:
****** Scheduler Failed ****
---------- Scheduler running ---------------
Jobs Queued: [(u’P10’, u’J61’)]
Traceback (most recent call last):
File “cryosparc2_command/command_core/init.py”, line 187, in background_worker
scheduler_run_core() # sets last run time
File “cryosparc2_command/command_core/init.py”, line 1592, in scheduler_run_core
alloc_hostname = j[‘resources_allocated’][‘hostname’]
KeyError: ‘hostname’
****** Scheduler Failed ****
A look at the database log shows no errors.
All of our worker nodes show up in the Instance Information tab in the Resource Manager.
I’ve tried reinstalling and forcing deps to reinstall. Still the same error. There was a similar post with this error, but no resolution was posted.
Thanks for your response. No queued jobs, and I removed all workers and just have a default node lane. I added the workers back in but no luck.
I’ve been messing around with the __init__.py script located in <install path>/cryosparc2_master/cryosparc2_command/command_core
It seems the output from this code:
#find all running jobs
jobs_running = mongo.db['jobs'].find({'status' : {'$in' : com.job_alive_statuses}}, {'resources_allocated' : 1})
is returning something unexpected for the next block of code:
#subtract currently running jobs from slots avail
for j in jobs_running:
alloc_hostname = j['resources_allocated']['hostname']
alloc_slots = j['resources_allocated']['slots']
alloc_license = j['resources_allocated'].get('licenses_acquired', 0)
# fixed dont get used up so ignore here
if alloc_hostname in slots_avail:
for slottype in alloc_slots.iterkeys():
slots_avail[alloc_hostname][slottype] -= set(alloc_slots[slottype])
licenses_used += alloc_license
# now slots_avail is currently correct
I added a print statement to dump out the contents of the “jobs_running” dictionaries when I queue up a job.
for x in jobs_running:
print x.items()
With an entirely empty queue, and a single job submitted, the output is:
It’s a bit confusing for us as well- not sure why it happened which is why I gave you the brute force method to resolve it. Something must’ve went wrong during the scheduling process, but not sure what. Please let us know if it happens again!
Hello — I know it’s been a while, but I had this error just now and the brute force solution resolved it for me too. I believe what may have caused this is we lost a ZFS mount unexpectedly. I rebooted the system after we got it back, but maybe something didn’t close out right…?
I’ve hit this twice, a few months ago and just today. Going to take a look and try to figure out which job was breaking the works- I just cleared them all from the GUI to make things allocate again.
We hit this again a few more times, unsure wether the incidence rate has gone up after the update, or because a particular user’s interactions keep triggering it, but I narrowed it down to a single 2D streaming classification job being marked as deleted but also running. This breaks the scheduler and also the display of active jobs in the GUI. Setting this deleted job’s status to ‘failed’ cleared things up.
Thank you for sending the logs. We noticed an error that has been addressed in patch 221221 for CryoSPARC v4.1.1. Please see the guide for patch instructions . Does the streaming 2D classification job status issue persist even after (updating to CryoSPARC v4.1.1 if needed) and applying the patch?
I haven’t noticed the issue since applying the patch, but before the patch, I had noticed that another job the seemed to reliably trigger the issue of jobs not showing up in the GUI (but jobs kept queuing OK AFAICT) was a ‘Curate Exposures’ job.
Thanks for the feedback. If you again encounter this problem after patching, please post details. As I will now close this topic, please open a new one if necessary.