I still do not have a complete picture of the instance’s state, and therefore cannot suggest a path to recovery.
If that’d be fine to you, could I suggest a ~15 minutes live debug session? it might be faster.
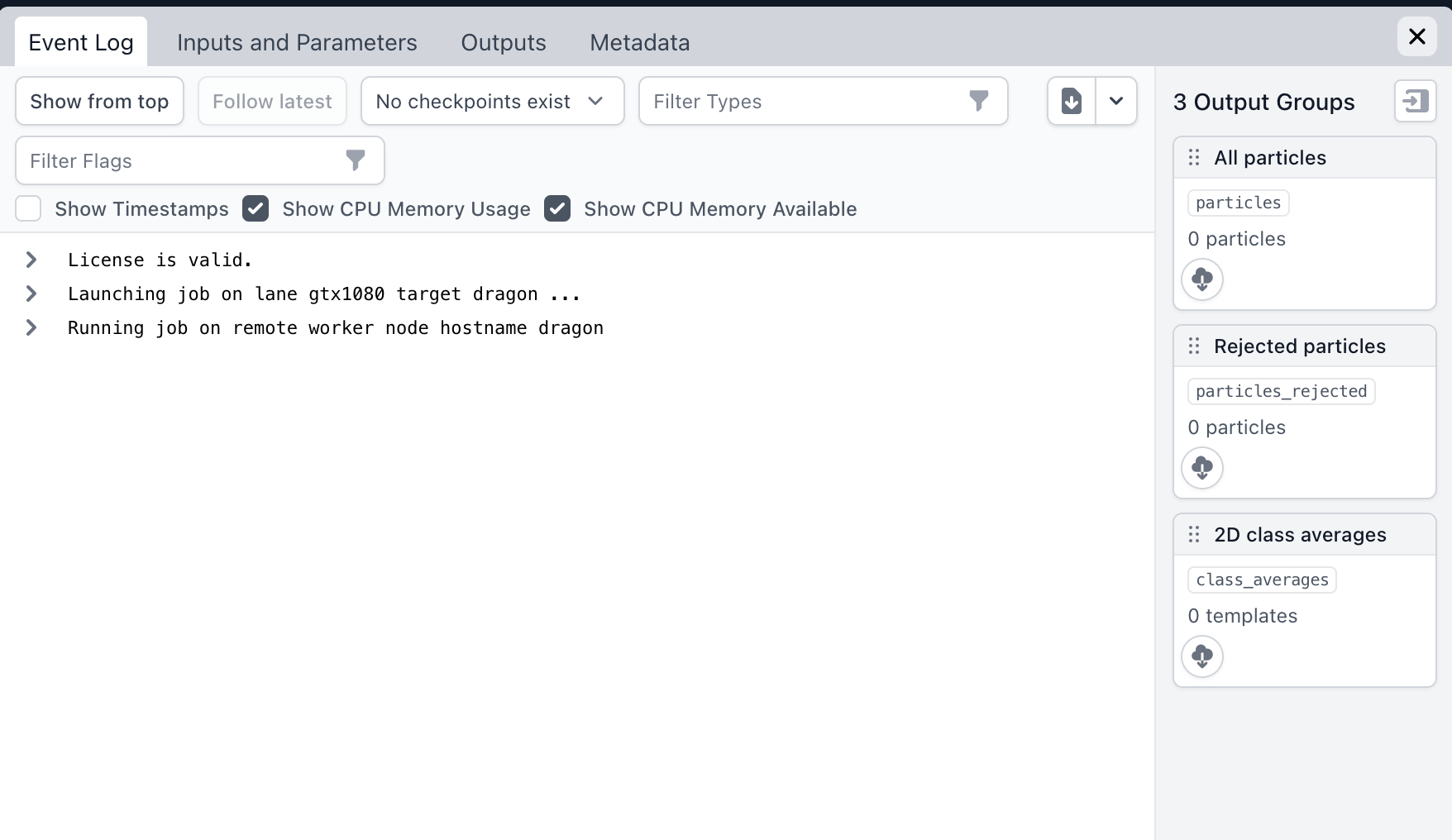
What, if anything, does the job log show?
(base) cryosparcuser@cmm-1:~$ ssh dragon "host cmm-1"
Host cmm-1 not found: 3(NXDOMAIN)
but it might be the host utility problem on centos – the other one works just fine:
(base) cryosparcuser@cmm-1:~$ ssh dragon "getent hosts cmm-1"
<the real IP here> cmm-1 cmm1
I am surprised that dragon could have been connected under these circumstances. Do you recall the full
cryosparcw connectcommand you used?
[cryosparcuser@dragon ~]$ ./cryosparc_app/cryosparc_worker/bin/cryosparcw connect --worker dragon --master <correct ip here> --port 39000 --ssdpath /data/cryosparc_cache --gpus "1,2,3" --ssdquota 500000 --lane gtx1080 --sshstr cryosparcuser@dragon --newlane
---------------------------------------------------------------
CRYOSPARC CONNECT --------------------------------------------
---------------------------------------------------------------
Attempting to register worker dragon to command <correct ip here>:39002
Connecting as unix user cryosparcuser
Will register using ssh string: cryosparcuser@<real ip here>
If this is incorrect, you should re-run this command with the flag --sshstr <ssh string>
---------------------------------------------------------------
Connected to master.
---------------------------------------------------------------
Current connected workers:
cmm-1
cmm2
---------------------------------------------------------------
Autodetecting available GPUs...
Detected 4 CUDA devices.
id pci-bus name
---------------------------------------------------------------
0 0000:03:00.0 GeForce GTX 1080 Ti
1 0000:04:00.0 GeForce GTX 1080 Ti
2 0000:81:00.0 GeForce GTX 1080 Ti
3 0000:82:00.0 GeForce GTX 1080 Ti
---------------------------------------------------------------
Devices specified: 1, 2, 3
Devices 1, 2, 3 will be enabled now.
This can be changed later using --update
---------------------------------------------------------------
Worker will be registered with SSD cache location /data/cryosparc_cache
---------------------------------------------------------------
Autodetecting the amount of RAM available...
This machine has 128.65GB RAM .
---------------------------------------------------------------
---------------------------------------------------------------
Registering worker...
Done.
You can now launch jobs on the master node and they will be scheduled
on to this worker node if resource requirements are met.
---------------------------------------------------------------
Final configuration for dragon
cache_path : /data/cryosparc_cache
cache_quota_mb : None
cache_reserve_mb : 10000
desc : None
gpus : [{'id': 1, 'mem': 11721506816, 'name': 'GeForce GTX 1080 Ti'}, {'id': 2, 'mem': 11721506816, 'name': 'GeForce GTX 1080 Ti'}, {'id': 3, 'mem': 11721506816, 'name': 'GeForce GTX 1080 Ti'}]
hostname : dragon
lane : gtx1080
monitor_port : None
name : dragon
resource_fixed : {'SSD': True}
resource_slots : {'CPU': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87], 'GPU': [1, 2, 3], 'RAM': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]}
ssh_str : cryosparcuser@<real ip here>
title : Worker node dragon
type : node
worker_bin_path : /home/cryosparcuser/cryosparc_app/cryosparc_worker/bin/cryosparcw
---------------------------------------------------------------
Is it now ensured that all workers can access CryoSPARC master ports using the
cmm-1hostname?
yes, I can e.g. ping them:
[cryosparcuser@dragon ~]$ ping cmm1
PING cmm-1 (10.55.229.12) 56(84) bytes of data.
64 bytes from cmm-1 (10.55.229.12): icmp_seq=1 ttl=61 time=0.476 ms
64 bytes from cmm-1 (10.55.229.12): icmp_seq=2 ttl=61 time=0.512 ms
or check if the ports are accessible:
[cryosparcuser@dragon ~]$ for p in `seq 39000 1 39010`; do printf "$p "; if $(nc -zv 10.55.229.12 $p &> /dev/null); then echo available; else echo unavailable; fi; done
39000 available
39001 available
39002 available
39003 available
39004 unavailable
39005 available
39006 available
39007 unavailable
39008 unavailable
39009 unavailable
39010 unavailable
ports 39004 and 39007-39010 are actually allowed on cmm-1 host too, but I believe there are no services running.