can not have a web server running all the time on the cluster node because the user will not be able to access it
software now allowed to schedule jobs unless it can go through the cluster’s scheduler.
cluster IT staff can not allow a webapp/server running all the time on the cluster and they will not open the port to the internet. Cluster uses have to submit jobs to the cluster themselves.
Submitting to a SLURM cluster is fully supported. The only understandable confusion here is where to run the master node, since you aren’t able to run processes on the login node. Technically, you should be able to run the master node on your own laptop (and submit jobs to the cluster), but the main requirement is that the storage layer is shared across the master and worker nodes. This can be done by potentially mounting the group directory (/cluster/projects) onto your laptop, but I doubt the cluster admins would allow that since it’s not even mounted on the login node. Another option would be to set up some sort of “Edge Node” that is located in the same network as the cluster- this would just be another VM that can submit to the cluster, but again shares the storage layer. Either way, it might be worth talking to the cluster admins in this case.
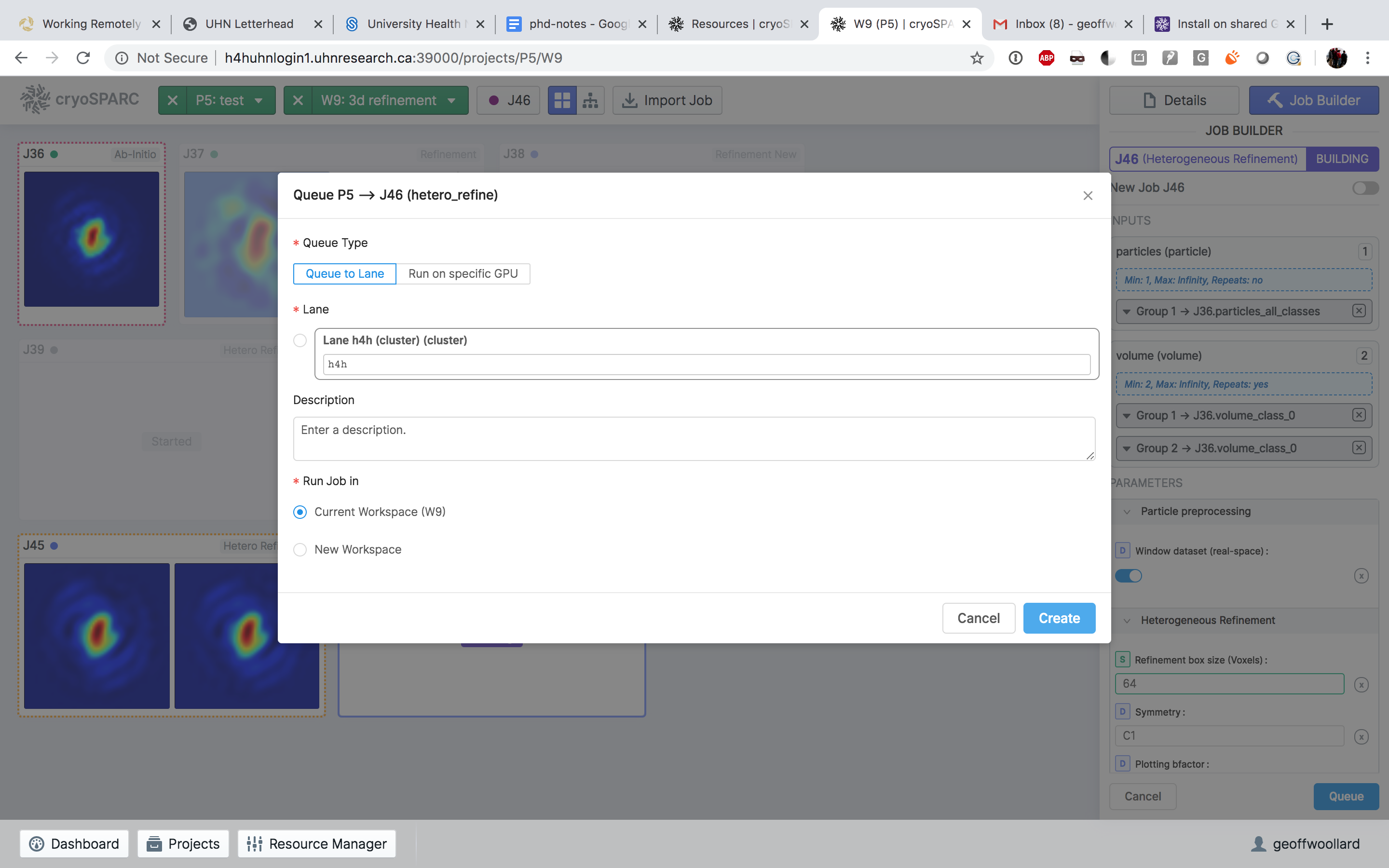
If the user submits a job without selecting the h4h lane (see screenshot below) then the job appears as queued in the workspace, but does not appear in the resource manager. The job output is completely blank. It’s actually an easy mistake to make.
No lane selected. This job will stay as queued, but never run, and not appear as queued in the resource manager.
Thanks for reporting the Queue modal quirk- we found the bug and we’re working on a fix!
Also, yes, sometimes cluster worker nodes have local SSD’s mounted on them. You should check with the cluster admin to see if they have one available. You can dynamically create the SSD path in your cluster_script.sh by adding export CRYOSPARC_SSD_PATH="<function that creates path to ssd>".
After some initial discussions it seems there is some reluctance to add an SSD. I’m not sure if its a policy issue (money, maintenance, priority) or feasibility issue.
Would clusters typically be able to have an SSD added? Is it difficult to do?