Thanks @wtempel .
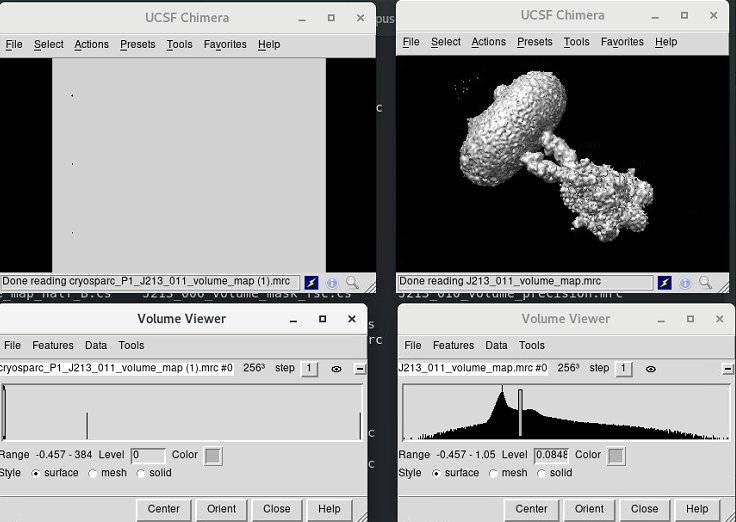
Do you observe inconsistencies within each pair of map files
Yes, the map files downloaded via the UI differ from their corresponding files in the job directory.
Here is the outputs:
$ cryosparcm cli "get_job('P1', 'J213', 'job_type', 'version', 'instance_information', 'status', 'params_spec', 'errors_run', 'created_at', 'started_at')"
{'_id': '67317b814e86c7a434a3459c', 'created_at': 'Mon, 11 Nov 2024 03:35:29 GMT', 'errors_run': [], 'instance_information': {'CUDA_version': '11.8', 'available_memory': '441.96GB', 'cpu_model': 'Intel(R) Xeon(R) Platinum 8468V', 'driver_version': '12.4', 'gpu_info': [{'id': 0, 'mem': 25386352640, 'name': 'NVIDIA GeForce RTX 4090', 'pcie': '0000:49:00'}], 'ofd_hard_limit': 51200, 'ofd_soft_limit': 1024, 'physical_cores': 96, 'platform_architecture': 'x86_64', 'platform_node': 'gpu1', 'platform_release': '5.15.0-94-generic', 'platform_version': '#104-Ubuntu SMP Tue Jan 9 15:25:40 UTC 2024', 'total_memory': '503.52GB', 'used_memory': '57.65GB'}, 'job_type': 'nonuniform_refine_new', 'params_spec': {'compute_use_ssd': {'value': False}, 'crg_do_anisomag': {'value': True}, 'crg_do_spherical': {'value': True}, 'crg_do_tetrafoil': {'value': True}, 'refine_ctf_global_refine': {'value': True}}, 'project_uid': 'P1', 'started_at': 'Mon, 11 Nov 2024 04:11:26 GMT', 'status': 'completed', 'uid': 'J213', 'version': 'v4.6.0'}
$ cryosparcm cli "get_job('P1', 'J595', 'job_type', 'version', 'instance_information', 'status', 'params_spec', 'errors_run', 'created_at', 'started_at')"
{'_id': '673807dc4c41e373a06f1395', 'created_at': 'Sat, 16 Nov 2024 02:47:56 GMT', 'errors_run': [], 'instance_information': {'CUDA_version': '11.8', 'available_memory': '947.48GB', 'cpu_model': 'Intel(R) Xeon(R) Platinum 8468V', 'driver_version': '12.4', 'gpu_info': [{'id': 0, 'mem': 47576711168, 'name': 'NVIDIA L40', 'pcie': '0000:29:00'}], 'ofd_hard_limit': 51200, 'ofd_soft_limit': 51200, 'physical_cores': 96, 'platform_architecture': 'x86_64', 'platform_node': 'gpu31', 'platform_release': '5.15.0-94-generic', 'platform_version': '#104-Ubuntu SMP Tue Jan 9 15:25:40 UTC 2024', 'total_memory': '1007.52GB', 'used_memory': '53.52GB'}, 'job_type': 'nonuniform_refine_new', 'params_spec': {}, 'project_uid': 'P1', 'started_at': 'Sat, 16 Nov 2024 02:49:10 GMT', 'status': 'completed', 'uid': 'J595', 'version': 'v4.5.3'}