First of all, I added the following parameters to master’s config.sh:
export CRYOSPARC_DISABLE_IMPORT_ON_MASTER=true
Then I took the following test:
1、Use “ulimit -v 10240000” in master to add a virtual memory limit, restart cryosparc. Then submit the import job, which failed with below error:
numpy.core._exceptions.MemoryError: Unable to allocate 89.9 MiB for an array with shape (8184, 11520) and data type uint8
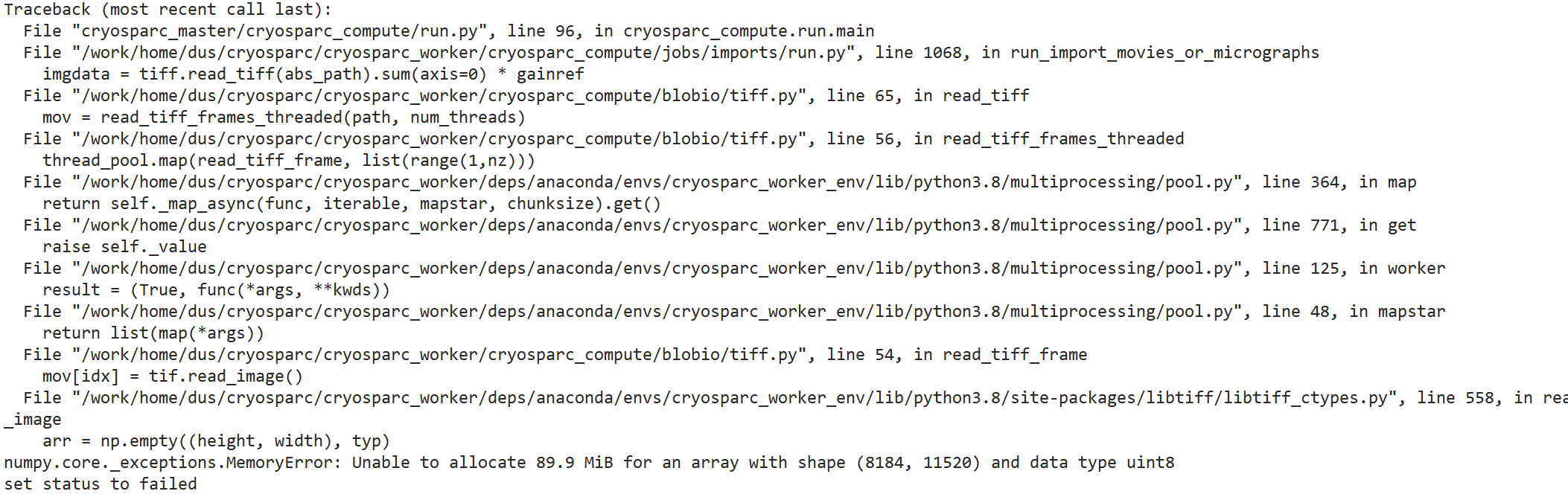
So I add the “ulimit -a” command to the end of cluster_script.sh,resubmit job. The result shows that slurm worker and master have the same limit.
2、Restart the cryosparc when virtual memory is not restricted in the master. The import job is running successfully.
I think I can come to a conclusion:
When cryosparc start,it inherits the master’s ulimit parameter and adds it to the slurm worker. But the strange thing is, use “cryosparw connect” add a worker,the worker runs without error.
I hope someone can help me find the cause of the problem. I need to use the ulimit feature to limit users on cluster’s master node.
My slurm script
---cluster_info.json---
{
"name" : "cluster_normal",
"worker_bin_path" : "/work/home/dus/cryosparc/cryosparc_worker/bin/cryosparcw",
"cache_path" : "/ssdcache",
"send_cmd_tpl" : "{{ command }}",
"qsub_cmd_tpl" : "sbatch {{ script_path_abs }}",
"qstat_cmd_tpl" : "squeue -j {{ cluster_job_id }}",
"qstat_code_cmd_tpl": "squeue --noheader -j {{ cluster_job_id }} --format=%T",
"qdel_cmd_tpl" : "scancel {{ cluster_job_id }}",
"qinfo_cmd_tpl" : "sinfo",
"transfer_cmd_tpl" : "cp {{ src_path }} {{ dest_path }}"
}
---cluster_script.sh---
#!/usr/bin/env bash
#### cryoSPARC cluster submission script template for SLURM
## Available variables:
## {{ run_cmd }} - the complete command string to run the job
## {{ num_cpu }} - the number of CPUs needed
## {{ num_gpu }} - the number of GPUs needed.
## Note: the code will use this many GPUs starting from dev id 0
## the cluster scheduler or this script have the responsibility
## of setting CUDA_VISIBLE_DEVICES so that the job code ends up
## using the correct cluster-allocated GPUs.
## {{ ram_gb }} - the amount of RAM needed in GB
## {{ job_dir_abs }} - absolute path to the job directory
## {{ project_dir_abs }} - absolute path to the project dir
## {{ job_log_path_abs }} - absolute path to the log file for the job
## {{ worker_bin_path }} - absolute path to the cryosparc worker command
## {{ run_args }} - arguments to be passed to cryosparcw run
## {{ project_uid }} - uid of the project
## {{ job_uid }} - uid of the job
## {{ job_creator }} - name of the user that created the job (may contain spaces)
## {{ cryosparc_username }} - cryosparc username of the user that created the job (usually an email)
##
## What follows is a simple SLURM script:
#SBATCH --job-name cryosparc_{{ project_uid }}_{{ job_uid }}
#SBATCH -n {{ num_cpu }}
#SBATCH --gres=gpu:{{ num_gpu }}
#SBATCH --partition=normal
#SBATCH --output={{ job_log_path_abs }}
#SBATCH --error={{ job_log_path_abs }}
#SBATCH --exclusive
{{ run_cmd }}
ulimit -a