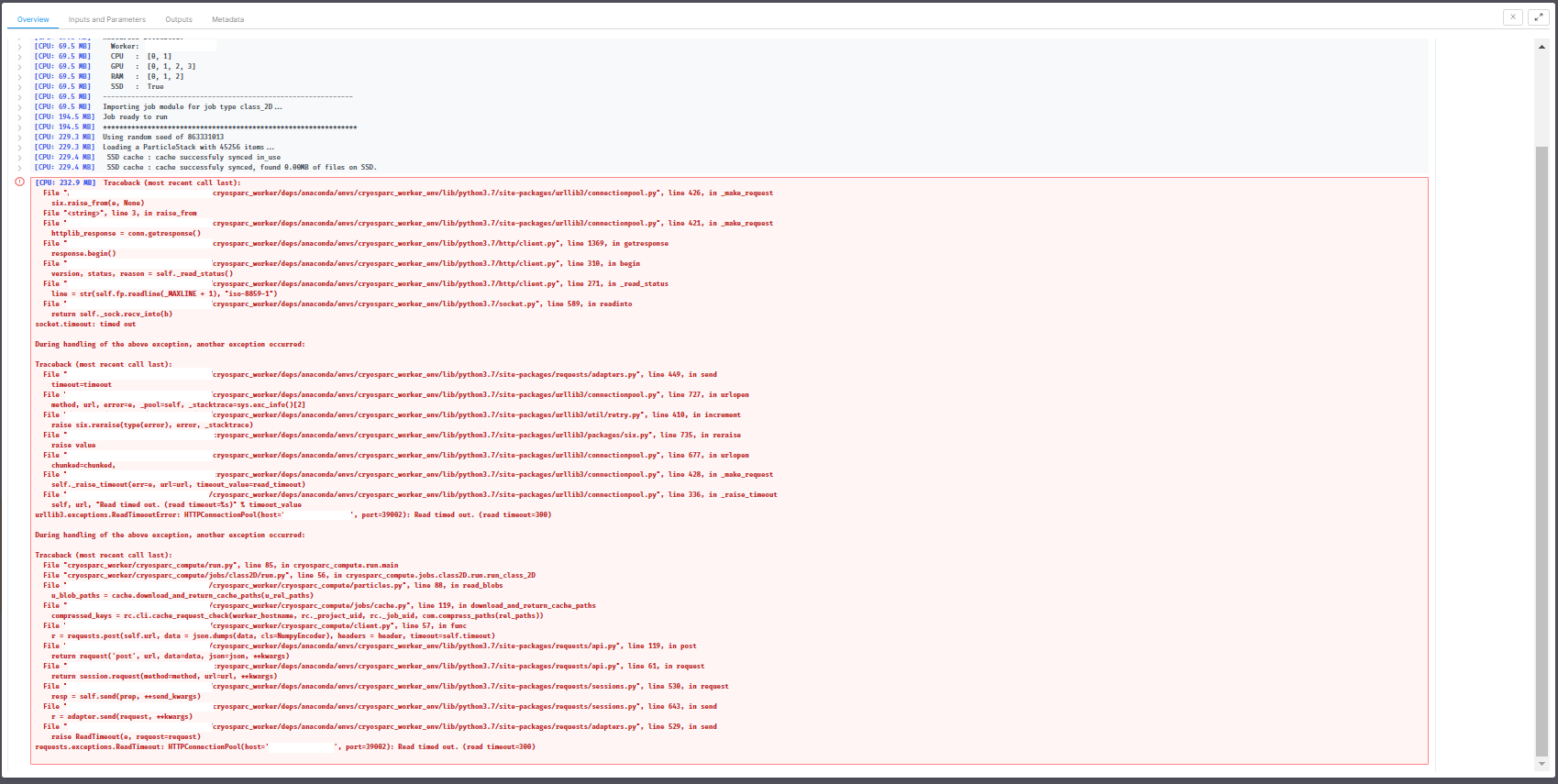
We has encountered this http timeout error message for the past three weeks. Now it almost fully blocked our cryosparc usage. Here are the error message:
We tried to add the “export CRYOSPARC_CLIENT_TIMEOUT=1800” to the config.sh under the “cryosparc_master” folder. However, it looks like this environment setting was not used after restarting cryosparc with “cryosparc restart”. We still have the error message saying “timeout=300”.
The ports 39000-39010 have been opened for both master and worker node. Trying “curl master node:39002 from the worker nodes” can return “hello world” without issue.
Now if we run 2D or 3D jobs without an SSD, the chance of successful running will increase. But with SSD, jobs usually fail before transferring data and throw out the timeout error. It’s worth noting that the particle dataset was not large at all (only 20G).
The cryosparc version we use is 3.3.2. We have 1 master node and two worker nodes.
In those cases, is caching disabled via the Cache particle images on SSD job parameter?
Yes.
Did the error ever occur when caching was disabled?
Not exactly sure. At least, these jobs worked fine when I test them, while the SSD cache jobs failed.
Do jobs with caching work some of the time?
Yes.
Are there any error messages in the joblog of the job for which you posted the screenshot above?
No error message was shown. Here are the last few lines of the job log file:
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
***************************************************************
Running job J182 of type class_3D
Allocated Resources : (not shown)
*** client.py: command (http://xxx.edu:39002/api) did not reply within timeout of 300 seconds, attempt 1 of 3
*** client.py: command (http://xxx.edu:39002/api) did not reply within timeout of 300 seconds, attempt 2 of 3
*** client.py: command (http://xxx.edu:39002/api) did not reply within timeout of 300 seconds, attempt 3 of 3
**** handle exception rc
set status to failed
Please can you send me the output of cryosparcm env via a forum direct message?
Will do.
What is the nominal bandwidth between the worker nodes and the file server that serves the project directory? Is it 1Gbps ethernet? 10Gbps?
1Gbps ethernet
Is there any history of NFS disruptions in your network environment? Any hints in the workers’ or NFS server’s system logs?
We are using Lustre, but we also tried to use NFS file system. How should we get these logs?
@Btz The change in cryosparc_worker/config.sh should be effective for jobs launched after the change. Do new jobs still show timeout=300?
Also:
What is the size of the $CRYOSPARC_DB_PATH directory?
On what type of storage is $CRYOSPARC_DB_PATH?
Yes. The jobs still show timeout=300 after the change in work config.sh. This is the similar as the heartbeat issue. It keeps reporting “30s no heartbeat” even if we have set the environment variable CRYOSPARC_HEARTBEAT_SECONDS=180 in both worker and master config.sh files.
I am beginning to suspect a yet-to-be-identified network issue, which would have to be investigated locally.
There is also a small chance that reboots of the CryoSPARC master (after cryosparcm stop) and worker(s) may restore proper function.
We have tried to stop cryosparc and reboot master node and worker nodes. Unfortunately, it didn’t resolve the timeout issue. Do you have any clues what we should test locally for the network? Thanks for all the comments so far!
As far as know, we didn’t do any updates for software, OS, computer hardware, or networks in the past few weeks.
However, we started to use cryosparc live few weeks ago. Since then, we usually run live jobs and normal jobs together under the same cryosparc installation. Will this lead to some communication issue between worker node and master node database?
This should not be a problem unless a there is a misconfiguration or the workload overwhelms available resources. A few questions about your CryoSPARC master host:
How much RAM and how many CPU cores does it have?
Does the host handle additional tasks:
as a CryoSPARC worker
as a master for an additional CryoSPARC instance
non CryoSPARC workloads
Over what kind of network (Ethernet? How many Gbps?) is it connected to the file server that holds the CryoSPARC database?
How heavy is the overall load on the file server that serves the database?
Have any patches been applied to the CryoSPARC v3.3.2 installation?
1. How much RAM and how many CPU cores does it have?
94G, 8 cores
2. Does the host handle additional tasks: as a CryoSPARC worker as a master for an additional CryoSPARC instance non CryoSPARC workloads
The master node is solely used for cryosparc master, no other additional tasks.
3. Over what kind of network (Ethernet? How many Gbps?) is it connected to the file server that holds the CryoSPARC database?
The database is in a local SSD in the master node. The connection between master and worker is 1Gbps.
4. How heavy is the overall load on the file server that serves the database?
The ssd load in the master node is usually quite low.
5. Have any patches been applied to the CryoSPARC v3.3.2 installation?
The latest patch 220824.