I have just upgraded from 2.11 to 2.13 and wanted to try out the new homogeneous refinement job. However, it fails with two different datasets - error messages below. It suggests some problem with compilation. The legacy version of homogeneous refinement is working, as is 2D classification and ab initio reconstruction. I haven’t tested anything else yet. I have tried restarting cryosparc but that makes no difference.
Thanks for any help
Dave Lawson
Are you able to install CUDA 10.2 (latest)? This error is because the CUDA Toolkit you’re using doesn’t have the function we’re using in our kernel in the latest job.
Once you’ve installed CUDA 10.2 and its required NVIDIA Driver, all you have to do is recompile one of the dependencies that cryoSPARC uses by running one function. This does not require updating or restarting cryoSPARC. Follow the instructions in this post:
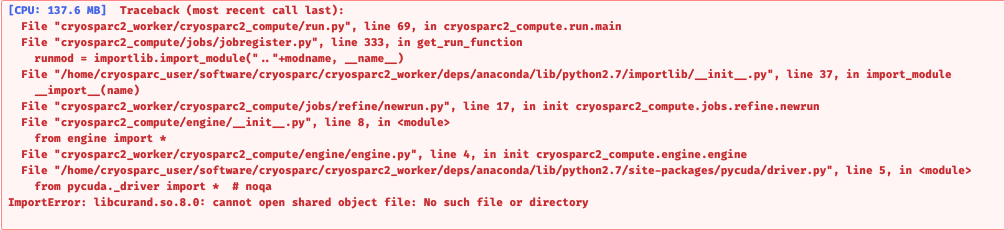
Following your advice we now have CUDA 10.2 and updated the NVIDIA Driver
I then ran:
cryosparc2_worker/bin/cryosparcw newcuda /usr/local/cuda-10.2
…which completed with the following lines:
Installing collected packages: pycuda
Running setup.py install for pycuda … done
Successfully installed pycuda-2019.1
You are using pip version 9.0.1, however version 20.0.2 is available.
You should consider upgrading via the ‘pip install --upgrade pip’ command.
Finished!
I have not upgraded pip - should I?
However, I was unable to connect to the cryosparc server through my browser
so I did a “cryosparcm restart”
and got the following:
CryoSPARC is running.
Stopping cryosparc.
command_core: stopped
database: stopped
Shut down
Starting cryoSPARC System master process…
CryoSPARC is not already running.
database: started
command_core: started
/home/cryosparc_user/software/cryosparc/cryosparc2_master/bin/cryosparcm: line 424: curl: command not found
/home/cryosparc_user/software/cryosparc/cryosparc2_master/bin/cryosparcm: line 424: curl: command not found
etc…
lines 424-426 look like this:
while ! curl http://$CRYOSPARC_MASTER_HOSTNAME:$CRYOSPARC_COMMAND_CORE_PORT -m1 -o/dev/null -s; do
sleep 0.5
done
the libcurand.so.8 error means that cryoSPARC is still looking for CUDA 8.0 libraries for some reason. The simplest way to fix this without digging too much into the guts of the system is to reinstall the cryosparc2_worker package only (i.e. not the cryosparc2_master - this should be kept exactly as is). You can do this by renaming your current cryosparc2_worker to cryosparc2_worker_old or similar, and then following the worker installation process again, this time specifying /usr/local/cuda-10.2 as your cuda path right from the start.
The worker installation process is here:
If you install the worker to the same location as it was previously, you will not have to change any configuration and jobs should start to run.
Hi @apunjani
Thanks for the advice. When I intially installed cryosparc I think I just did the quick installation for a single workstation, rather than separate installations for master and worker. Just to avoid me messing up, please could you clarify my best course of action - should I repeat the quick installation?
Thanks very much
Dave
The standalone installation script installs the master and worker together- it’s essentially the same as doing the master and worker install separately. You can still do what @apunjani said in this case!
Hi @stephan
Thanks for confirming. That nearly worked - I ended up with the worker and master running different versions.
I fixed this using cryosparcm update
Thanks again to both @stephan and @apunjani for the help!
Dave