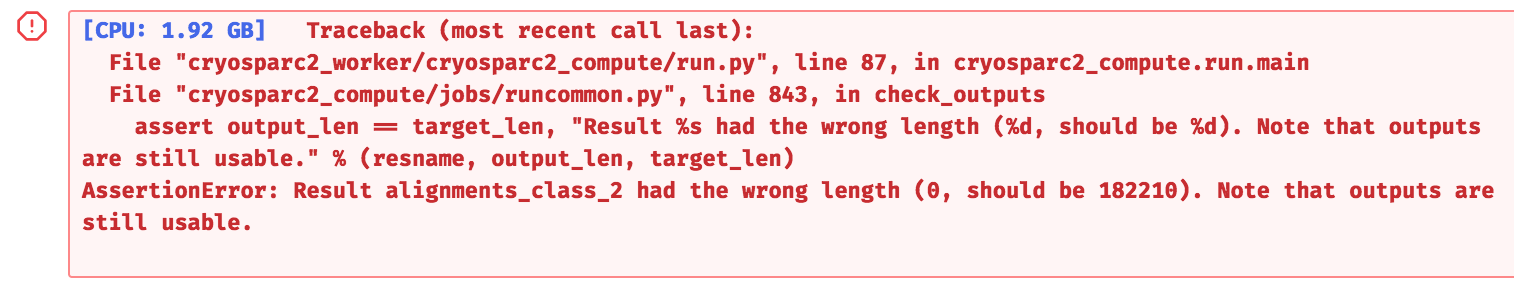
I’m getting this error Result alignments_class_1 had the wrong length (0, should be 182210) with a certain het. refine job (fresh particles).
(PS the reason I suddenly have these reports is I have been using my lab’s shared instance again, which has 75 extant projects (> 100 including deleted) and almost 6,000 completed jobs - not sure exactly what’s contributing to the apparent instability).
I think this happens when some classes legitimately have 0 particles assigned. Oddly, once the class is empty the failure occurs somewhat randomly, after more iterations. Further, empty classes are apparently sorted to the end of the list of classes, which would break queuing further jobs after a reference-based classification that assumes something about which is which.
Hi @DanielAsarnow,
The first error message happens at the very end of the job right? And it seems to happen when, during the same job, one of the classes collapses to zero particles and remains that way until the end?
That particular traceback points to a part of the code that checks the outputs of a job that is about to complete, to make sure the outputs are all making sense.
Can you paste a screenshot of what you mean by the sorted to the end of the list part? As far as I know the hetero refine job never re-arranges the classes - or shouldn’t be!
Correct on the first point.
Here are screen shots for the other issue I mentioned.
This job has these inputs:
Class 2 is started from an intentional garbage reference, and ends up having no particles:
Then I repeated the job, but placing that reference for Class 1:
But again its Class 2 that becomes empty:
Now, it’s possible that this happened because of genuine particle sorting, but the other two classes start from the same high-quality reference, and the other output volumes look like that.