I recently received suggestions from reviewers as follows:
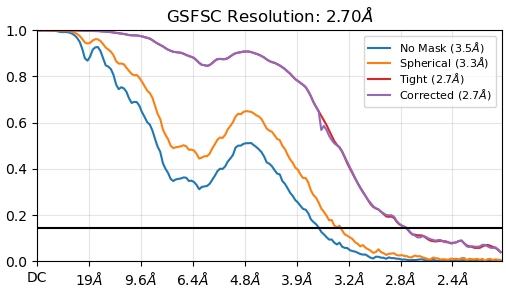
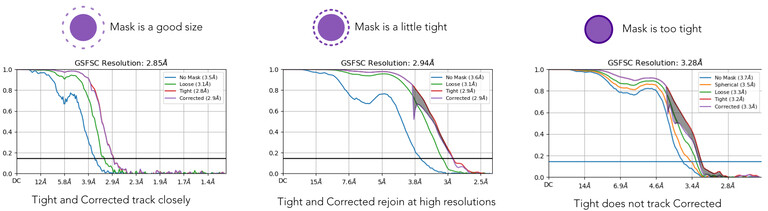
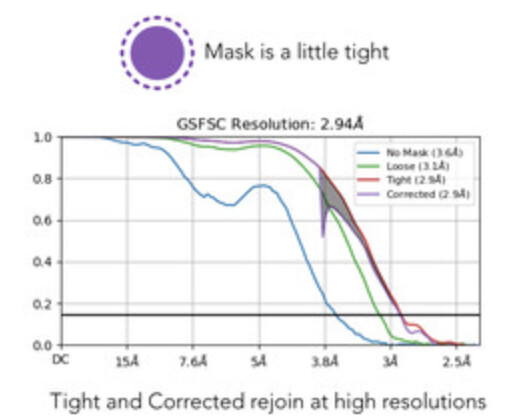
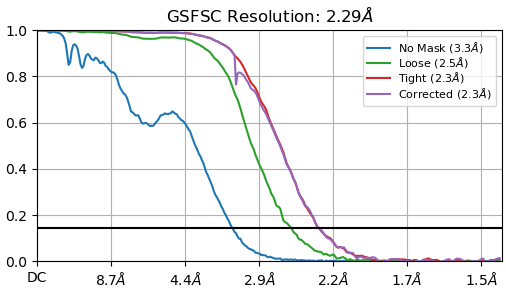
FSC is not dropping to 0, this is usually induced by duplicated particles or a too tight mask during FSC calculation. In both cases, it could lead to resolution overestimation. Please try to remove duplicates before your final refinement and if this is not the problem, recompute FSC with a broader mask.
For duplicated particles, I run the Remove Duplicate Particles job and the result is that only 1 particle is rejected. For mask, With reference to Tutorial: Mask Creation | CryoSPARC Guide, I think mask is appropriate, in addition, I use binned particles (F-crop factor 0.5), I think is it for this reason, how can I improve my work?
No mask and spherical masks fall to zero. Usually if genuine duplicates are present, they will not fall to zero either. What angpix is your data? Is that fully unbinned? Test duplicate removal, but mask optimisation (softer mask) is probably what is necessary.
Thank you very much for your reminding, I used the default parameter, the size of my particle is about 160 angstroms, I will try to change the minimum separation to 100 angstroms, I wonder if you have any suggestions on the setting of this parameter
This is a good point - but not sure it is a mask issue, as the corrected FSC looks fine - minimal artefacts at the phase randomization cutoff. I would try refining with unbinned particles and see how it looks
Thank you very much for your advice. I will endeavor to employ a softer mask. Additionally, a phenomenon that perplexed me is that in my previous work, I attempted a stack of 790,000 particles, all of which used the default mask, and its FSC curve could fall to 0. However, the review experts deemed that there were an excessive number of particles.
@olibclarke; Agreed, even the corrected mask dip is small. Problem is that CryoSPARC doesn’t show the phase randomised FSC - IIRC in RELION it’s usually set where the FSC drops below 0.8 for the first time in the unmasked map? Which in this case would be about 15 Ang. Also agree with unbinning - if size is an issue, could use 3/4 crop, I did that recently to keep box sizes under control as I wasn’t getting close enough to Nyquist to warrant the extreme box size.
@HFZ; excessive numbers of particles? Really? Considering the speed and ease with which data can now be acquired on a high-end microscope… huh. A slightly softer mask shouldn’t impact final resolution excessively, and won’t affect local resolution at all so local filtering will still show higher resolution features where appropriate.
What was their rationale on too many particles being a bad thing? It could indicate that the stack was insufficiently cleaned, but one can’t say that solely from the number of particles
Right, I see. Not sure it’s a hard and fast point though in CryoSPARC (or that dip is unrelated to the phase randomisation point) as a refinement last week showed that at ~0.9…
And you’re right, visualising it is a faff in CryoSPARC.
Hi Oli, does duplicate particles only need to be run when the results of multiple picker jobs are combined? In the same vein if I make the minimum seperation distance on picker jobs one full diameter will this reduce the chance of duplicate picks? (i.e are duplicate picks a result of combing picking jobs, setting pick diameter too close on crowded micrographs or high local maxima number etc or all the above? New to processing and appreciate any direction!
P.S. Is the remove duplicate standalone job functionally the same as remove duplicates option present in 2D classification or no?
Yes, in 2D classification, the “remove duplicates” parameter and the associated “minimum separation distance” parameter below it will accomplish the same thing as running a standalone remove duplicate particles job.
In most cases, you shouldn’t have to worry about duplicate particles except in the cases you describe (combining picking jobs, crowded micrographs, etc), but you should also be aware that performing a symmetry expansion on your particles will also generate “duplicates” that need to be removed before running a global refinement (heterogeneous, homogeneous, non-uniform, etc). You can find some more information in this thread: