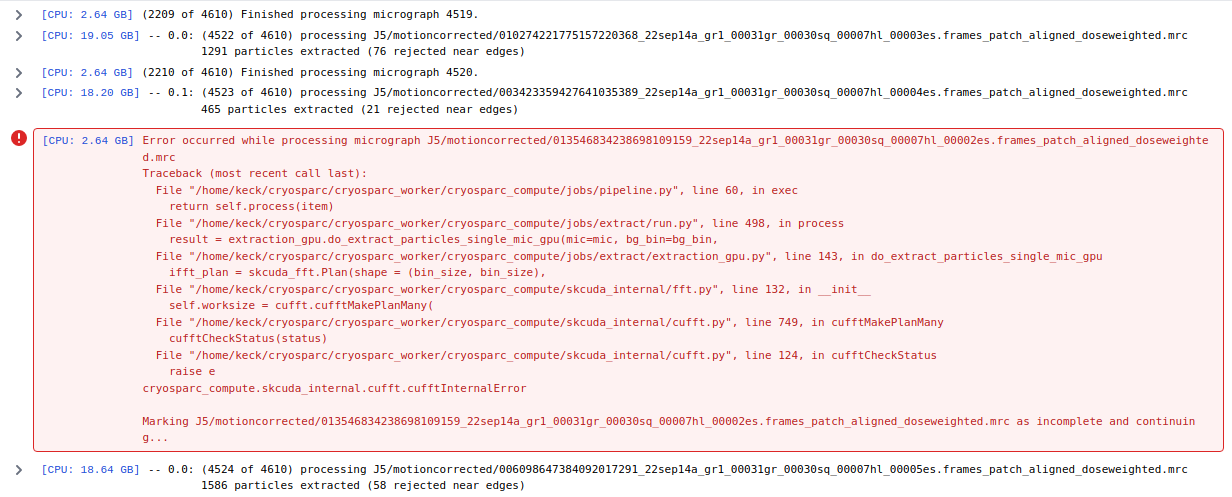
The difference is that this error only occur for about half of my dataset.
The only parameter I can change in this job is the Extraction Box Size - and I have tried that multiple times with the same error (from 256 - 360 pix).
I tried doing the same job for the tutorial data set and they don’t give any error.
I also have a problem with my ab-initio process down the line but I’m not sure if they are connected since the 2D classes job has no problem.
Is there a way for me to fix this (smaller/bigger box size) or am I stuck with half the data missing?
[CPU: 3.34 GB]
Error occurred while processing micrograph J5/motioncorrected/008579737736815460210_22sep14a_gr1_00031gr_00031sq_00007hl_00013es.frames_patch_aligned_doseweighted.mrc
Traceback (most recent call last):
File "/home/keck/cryosparc/cryosparc_worker/cryosparc_compute/jobs/pipeline.py", line 60, in exec
return self.process(item)
File "/home/keck/cryosparc/cryosparc_worker/cryosparc_compute/jobs/extract/run.py", line 498, in process
result = extraction_gpu.do_extract_particles_single_mic_gpu(mic=mic, bg_bin=bg_bin,
File "/home/keck/cryosparc/cryosparc_worker/cryosparc_compute/jobs/extract/extraction_gpu.py", line 136, in do_extract_particles_single_mic_gpu
fft_plan = skcuda_fft.Plan(shape=(patch_size, patch_size),
File "/home/keck/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/fft.py", line 132, in __init__
self.worksize = cufft.cufftMakePlanMany(
File "/home/keck/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/cufft.py", line 749, in cufftMakePlanMany
cufftCheckStatus(status)
File "/home/keck/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/cufft.py", line 124, in cufftCheckStatus
raise e
cryosparc_compute.skcuda_internal.cufft.cufftInternalError
Marking J5/motioncorrected/008579737736815460210_22sep14a_gr1_00031gr_00031sq_00007hl_00013es.frames_patch_aligned_doseweighted.mrc as incomplete and continuing...
Non default job parameter:
Extraction box size (pix) : 256
Output of /path/to/cryosparc_worker/bin/cryosparcw gpulist
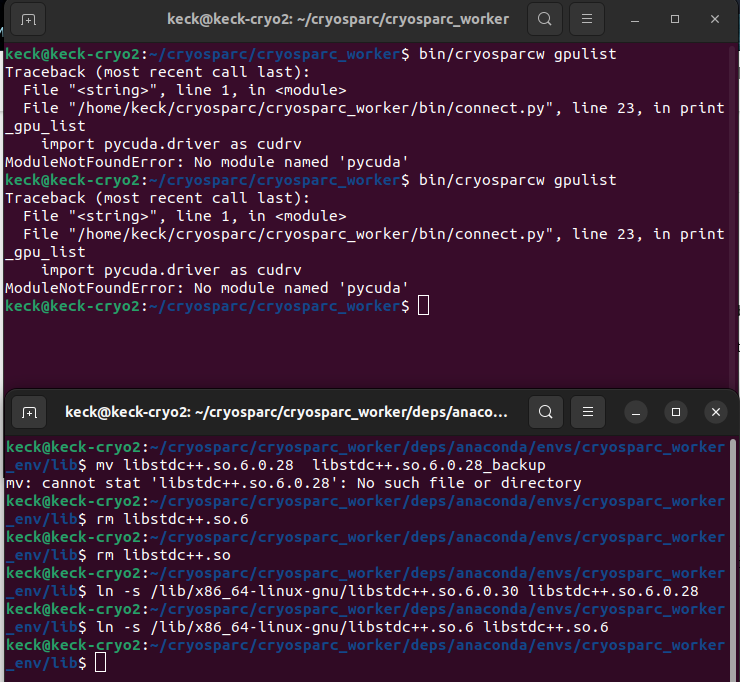
~/cryosparc/cryosparc_worker$ bin/cryosparcw gpulist
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/keck/cryosparc/cryosparc_worker/bin/connect.py", line 23, in print_gpu_list
import pycuda.driver as cudrv
ModuleNotFoundError: No module named 'pycuda'
This indicates a broken cryosparc worker installation.
Have there been any software updates since you last ran a GPU-enabled job on this CryoSPARC instance?
at the end of the installation this is the error I’m getting:
In file included from src/cpp/cuda.cpp:4:
src/cpp/cuda.hpp:14:10: fatal error: cuda.h: No such file or directory
14 | #include <cuda.h>
| ^~~~~~~~
compilation terminated.
error: command '/usr/bin/gcc' failed with exit code 1
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: legacy-install-failure
× Encountered error while trying to install package.
╰─> pycuda
note: This is an issue with the package mentioned above, not pip.
hint: See above for output from the failure.
check_install_deps.sh: 59: ERROR: installing python failed.
and when I do output for gpulist it still gives the same error
keck@keck-cryo2:~/cryosparc/cryosparc_worker$ bin/cryosparcw call which nvcc
keck@keck-cryo2:~/cryosparc/cryosparc_worker$ bin/cryosparcw call nvcc --version
bin/cryosparcw: line 338: exec: nvcc: not found
I don’t have nvcc installed because of this:
As you mentioned previously to hold off on installing a “system-wide” CUDA toolkit, should I do it for this?
Not having that installed may avoid some confusing CryoSPARC issues.
If you carefully ensure the prerequisites, /path/to/cryosparc_worker/bin/cryosparcw install-3dflex
has the convenient side effect of setting up your worker environment even for tasks other than 3DFlex. I think you have tried it earlier. You may want to try /path/to/cryosparc_worker/bin/cryosparcw install-3dflex
again.
There was some error with that installation of 3dflex (just like before: PyTorch not installed correctly, cannot find NVDIA gpu)
but the command bin/cryosparcw gpulist now yield
Detected 1 CUDA devices.
id pci-bus name
---------------------------------------------------------------
0 0000:61:00.0 NVIDIA RTX A5000
---------------------------------------------------------------
I will try to reload the job and see if I get the same error and will let you know
Hi Wtempel,
I’m trying to update the cryosparc to version 4.2.1
and I have the same problem as before
keck@keck-cryo2:~/cryosparc/cryosparc_worker$ bin/cryosparcw gpulist
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/keck/cryosparc/cryosparc_worker/bin/connect.py", line 23, in print_gpu_list
import pycuda.driver as cudrv
ModuleNotFoundError: No module named 'pycuda'
doing
/home/keck/cryosparc/cryosparc_worker/bin/cryosparcw forcedeps 2>&1 | tee forcedeps_20230124.out
no longer help, there’s nothing else that changes. can you help?