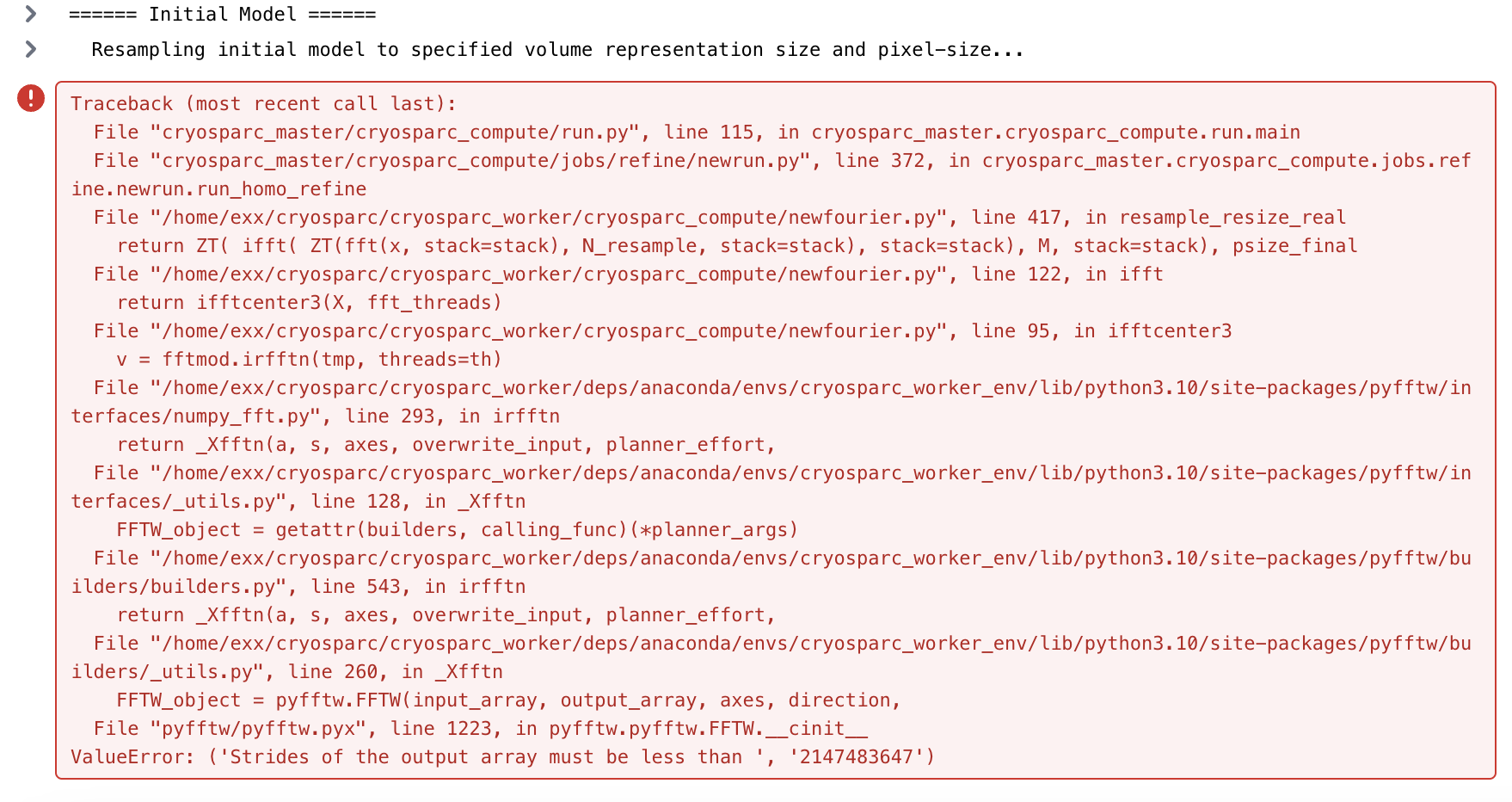
Tried running a NU-refinement with a large box size (1024px), it fails with the attached error (on an RTX-3090 card). Thoughts? I am running in low memory mode. It works when the particles are downsampled to 768px, so I assume it is a memory error of some kind, but it isn’t totally obvious to me looking at the error.
Cheers
Oli
Traceback (most recent call last):
File "cryosparc_master/cryosparc_compute/run.py", line 115, in cryosparc_master.cryosparc_compute.run.main
File "cryosparc_master/cryosparc_compute/jobs/refine/newrun.py", line 372, in cryosparc_master.cryosparc_compute.jobs.refine.newrun.run_homo_refine
File "/home/exx/cryosparc/cryosparc_worker/cryosparc_compute/newfourier.py", line 417, in resample_resize_real
return ZT( ifft( ZT(fft(x, stack=stack), N_resample, stack=stack), stack=stack), M, stack=stack), psize_final
File "/home/exx/cryosparc/cryosparc_worker/cryosparc_compute/newfourier.py", line 122, in ifft
return ifftcenter3(X, fft_threads)
File "/home/exx/cryosparc/cryosparc_worker/cryosparc_compute/newfourier.py", line 95, in ifftcenter3
v = fftmod.irfftn(tmp, threads=th)
File "/home/exx/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.10/site-packages/pyfftw/interfaces/numpy_fft.py", line 293, in irfftn
return _Xfftn(a, s, axes, overwrite_input, planner_effort,
File "/home/exx/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.10/site-packages/pyfftw/interfaces/_utils.py", line 128, in _Xfftn
FFTW_object = getattr(builders, calling_func)(*planner_args)
File "/home/exx/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.10/site-packages/pyfftw/builders/builders.py", line 543, in irfftn
return _Xfftn(a, s, axes, overwrite_input, planner_effort,
File "/home/exx/cryosparc/cryosparc_worker/deps/anaconda/envs/cryosparc_worker_env/lib/python3.10/site-packages/pyfftw/builders/_utils.py", line 260, in _Xfftn
FFTW_object = pyfftw.FFTW(input_array, output_array, axes, direction,
File "pyfftw/pyfftw.pyx", line 1223, in pyfftw.pyfftw.FFTW.__cinit__
ValueError: ('Strides of the output array must be less than ', '2147483647')