Hi Stephan,
Here are the outputs:
[{'cache_path': '/scratch/cryosparc_cache', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'desc': None, 'gpus': [{'id': 0, 'mem': 51050250240, 'name': 'NVIDIA RTX A6000'}, {'id': 1, 'mem': 51049857024, 'name': 'NVIDIA RTX A6000'}, {'id': 2, 'mem': 51050250240, 'name': 'NVIDIA RTX A6000'}, {'id': 3, 'mem': 51050250240, 'name': 'NVIDIA RTX A6000'}], 'hostname': 'io', 'lane': 'io', 'monitor_port': None, 'name': 'io', 'resource_fixed': {'SSD': True}, 'resource_slots': {'CPU': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39], 'GPU': [0, 1, 2, 3], 'RAM': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]}, 'ssh_str': 'exx@io', 'title': 'Worker node io', 'type': 'node', 'worker_bin_path': '/home/exx/software/cryosparc/cryosparc_worker/bin/cryosparcw'}, {'cache_path': '/scratch/cryosparc_cache', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'desc': None, 'gpus': [{'id': 0, 'mem': 25434587136, 'name': 'NVIDIA RTX A5000'}, {'id': 1, 'mem': 25434193920, 'name': 'NVIDIA RTX A5000'}, {'id': 2, 'mem': 25434587136, 'name': 'NVIDIA RTX A5000'}, {'id': 3, 'mem': 25434587136, 'name': 'NVIDIA RTX A5000'}], 'hostname': 'ganymede', 'lane': 'ganymede', 'monitor_port': None, 'name': 'ganymede', 'resource_fixed': {'SSD': True}, 'resource_slots': {'CPU': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39], 'GPU': [0, 1, 2, 3], 'RAM': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]}, 'ssh_str': 'exx@ganymede', 'title': 'Worker node ganymede', 'type': 'node', 'worker_bin_path': '/home/exx/software/cryosparc/cryosparc_worker/bin/cryosparcw'}, {'cache_path': '/scratch/cryosparc_cache', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'desc': None, 'gpus': [{'id': 0, 'mem': 25434587136, 'name': 'NVIDIA RTX A5000'}, {'id': 1, 'mem': 25434193920, 'name': 'NVIDIA RTX A5000'}, {'id': 2, 'mem': 25434587136, 'name': 'NVIDIA RTX A5000'}, {'id': 3, 'mem': 25434587136, 'name': 'NVIDIA RTX A5000'}], 'hostname': 'europa', 'lane': 'europa', 'monitor_port': None, 'name': 'europa', 'resource_fixed': {'SSD': True}, 'resource_slots': {'CPU': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39], 'GPU': [0, 1, 2, 3], 'RAM': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]}, 'ssh_str': 'exx@europa', 'title': 'Worker node europa', 'type': 'node', 'worker_bin_path': '/home/exx/software/cryosparc/cryosparc_worker/bin/cryosparcw'}, {'cache_path': '/scratch/cryosparc_cache', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'desc': None, 'hostname': 'garcialabcoolkids', 'lane': 'garcialabcoolkids', 'name': 'garcialabcoolkids', 'qdel_cmd_tpl': 'scancel {{ cluster_job_id }}', 'qinfo_cmd_tpl': 'sinfo', 'qstat_cmd_tpl': 'squeue -j {{ cluster_job_id }}', 'qsub_cmd_tpl': 'sbatch {{ script_path_abs }}', 'script_tpl': '#!/usr/bin/env bash\n#### cryoSPARC cluster submission script template for SLURM\n## Available variables:\n## {{ run_cmd }} - the complete command string to run the job\n## {{ num_cpu }} - the number of CPUs needed\n## {{ num_gpu }} - the number of GPUs needed. \n## Note: the code will use this many GPUs starting from dev id 0\n## the cluster scheduler or this script have the responsibility\n## of setting CUDA_VISIBLE_DEVICES so that the job code ends up\n## using the correct cluster-allocated GPUs.\n## {{ ram_gb }} - the amount of RAM needed in GB\n## {{ job_dir_abs }} - absolute path to the job directory\n## {{ project_dir_abs }} - absolute path to the project dir\n## {{ job_log_path_abs }} - absolute path to the log file for the job\n## {{ worker_bin_path }} - absolute path to the cryosparc worker command\n## {{ run_args }} - arguments to be passed to cryosparcw run\n## {{ project_uid }} - uid of the project\n## {{ job_uid }} - uid of the job\n## {{ job_creator }} - name of the user that created the job (may contain spaces)\n## {{ cryosparc_username }} - cryosparc username of the user that created the job (usually an email)\n##\n## What follows is a simple SLURM script:\n\n#SBATCH --job-name cryosparc_{{ project_uid }}_{{ job_uid }}\n#SBATCH -n {{ num_cpu }}\n#SBATCH --gres=gpu:{{ num_gpu }}\n#SBATCH --mem={{ (ram_gb)|int }}GB \n#SBATCH -o {{ job_dir_abs }}\n#SBATCH -e {{ job_dir_abs }}\n#SBATCH --error=/home/exx//Slurmlogs/%j.err\n#SBATCH --output=/home/exx//Slurmlogs/%j.out\n\navailable_devs=""\nfor devidx in $(seq 0 15);\ndo\n if [[ -z $(nvidia-smi -i $devidx --query-compute-apps=pid --format=csv,noheader) ]] ; then\n if [[ -z "$available_devs" ]] ; then\n available_devs=$devidx\n else\n available_devs=$available_devs,$devidx\n fi\n fi\ndone\nexport CUDA_VISIBLE_DEVICES=$available_devs\n\n{{ run_cmd }}\n', 'send_cmd_tpl': '{{ command }}', 'title': 'garcialabcoolkids', 'type': 'cluster', 'worker_bin_path': '/home/exx/software/cryosparc/cryosparc_worker/bin/cryosparcw'}, {'cache_path': '/scratch/cryosparc_cache/', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'desc': None, 'gpus': [{'id': 0, 'mem': 51050250240, 'name': 'NVIDIA RTX A6000'}, {'id': 1, 'mem': 51049857024, 'name': 'NVIDIA RTX A6000'}, {'id': 2, 'mem': 51050250240, 'name': 'NVIDIA RTX A6000'}, {'id': 3, 'mem': 51050250240, 'name': 'NVIDIA RTX A6000'}], 'hostname': 'jupiter', 'lane': 'jupiter', 'monitor_port': None, 'name': 'jupiter', 'resource_fixed': {'SSD': True}, 'resource_slots': {'CPU': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39], 'GPU': [0, 1, 2, 3], 'RAM': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]}, 'ssh_str': 'exx@jupiter', 'title': 'Worker node jupiter', 'type': 'node', 'worker_bin_path': '/home/exx/software/cryosparc/cryosparc_worker/bin/cryosparcw'}]
[{'desc': '', 'name': 'garcialabcoolkids', 'title': 'Lane garcialabcoolkids (cluster)', 'type': 'cluster'}, {'desc': '', 'name': 'europa', 'title': 'europa', 'type': 'node'}, {'desc': '', 'name': 'ganymede', 'title': 'ganymede', 'type': 'node'}, {'desc': '', 'name': 'io', 'title': 'io', 'type': 'node'}, {'desc': '', 'name': 'jupiter', 'title': 'jupiter', 'type': 'node'}]
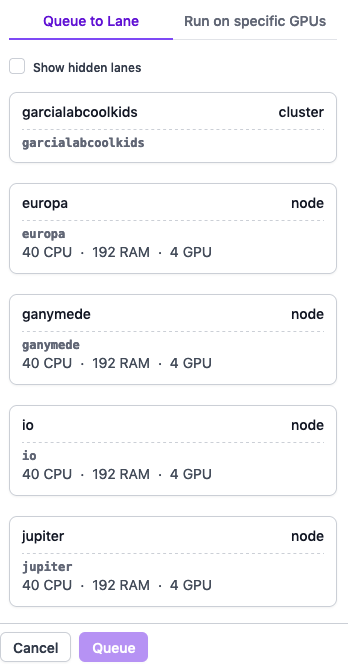
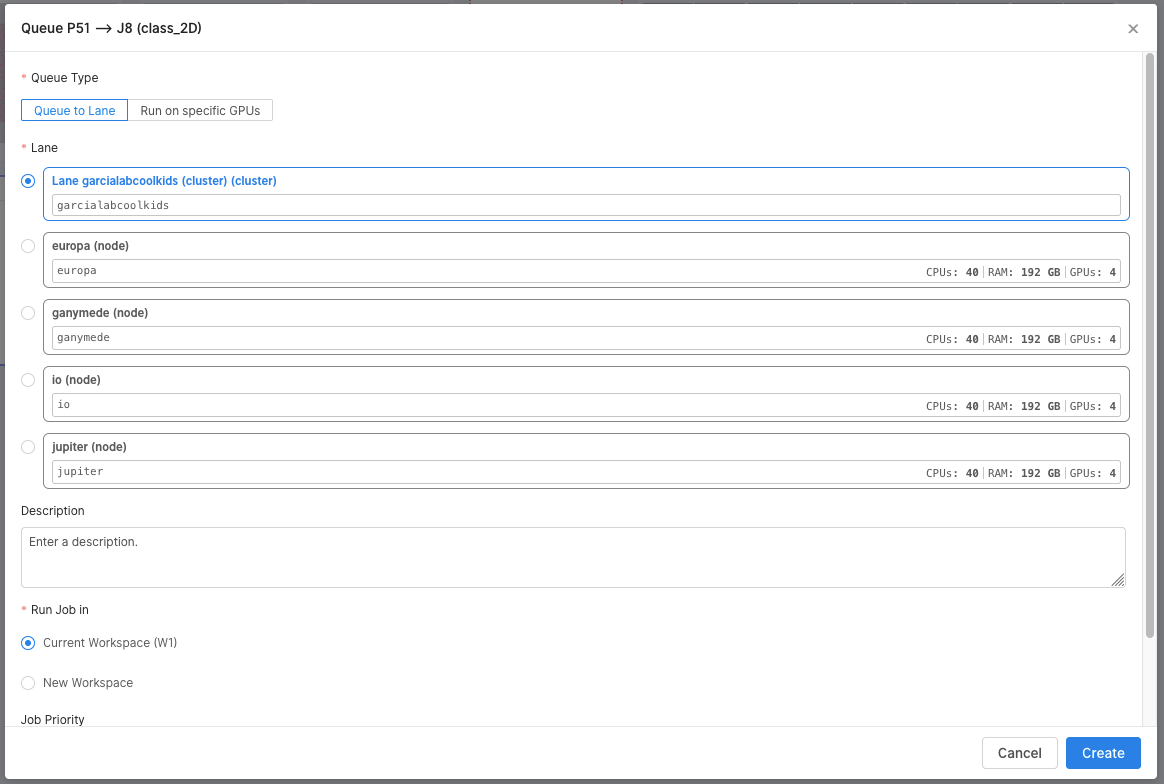
This is what I used to see - the first lane is pre-selected so you can just click queue and no need to select the lane every time:
Sorry for the relatively small concern - its just very helpful for newer users on our cluster if it just defaults to where most jobs should be running. Hope this makes sense.
Cheers,
NAC