Hi,
I’m trying to train Deep Picker on a set of manually picked micrographs, but particles are quite sparse so the model is not returning any particles when used for inference.
I would like to try the “Use class weights” parameter (https://guide.cryosparc.com/processing-data/all-job-types-in-cryosparc/deep-picking/guideline-for-supervised-particle-picking-using-deep-learning-models) to try and improve this, but I can’t see this functionality in my version (v3.1.0), even in advanced mode. Was this option removed recently?
I have the same question!
1 Like
This is a bug- it was accidentally removed. We’ll release the fix that re-enables this parameter in the next patch to v3.2.0, which should be released tomorrow. Sorry for any inconvenience.
2 Likes
@stephan Thanks for your help!
Thanks!
However, I just applied the patch and now the job can’t seem to find my GPUs (which worked previously):
AssertionError: Cannot find TensorFlow compatible GPUs.

Do you know why that is happening?
Hi @emil,
That’s odd. Do you think you can restart cryoSPARC, and try again? cryosparcm restart
I accidentally forgot to mention a previous problem, which might be good for you to know.  When I first started the job after patching, I got this message:
When I first started the job after patching, I got this message:
AssertionError: Input number of GPUs must be less than or equal to number of available GPUs. Please check job log for more information.

We have two GPUs and both were free at that point.
To troubleshoot, I restarted the job with “number of GPUs = 0” and got the error mentioned before, which maybe then makes sense? But why is it even possible to start the job with no GPUs? And why did I get the first error message?
Thanks for helping out!
Hi @emil,
When you set the job to use 0 GPUs, the job will use your CPUs for training (which is quite slow). Though as you pointed out, there seems to be a bug where the job still looks for active GPUs on the system even if it only wants to use CPUs to do the work.
This also means that there seems to be an issue detecting the available GPUs on your system.
Can you post the job log of this job?
cryosparcm joblog <project_uid> <job_uid>
e.g. cryosparcm joblog P23 J233
Can you also make sure you can run nvidia-smi on the workstation without error?
This is the output from nvidia-smi:
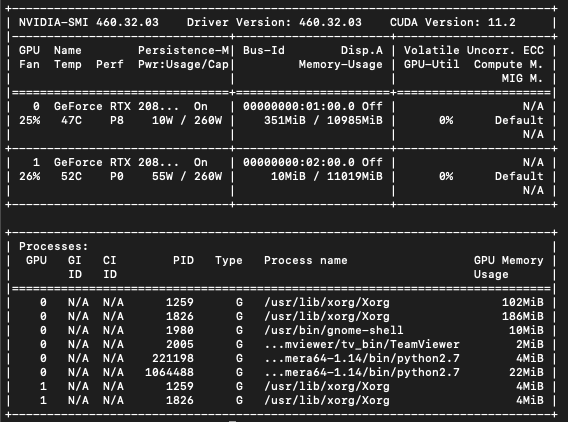
This is the job log (by the way, is it better if I post raw text instead of a screenshot in the future?):
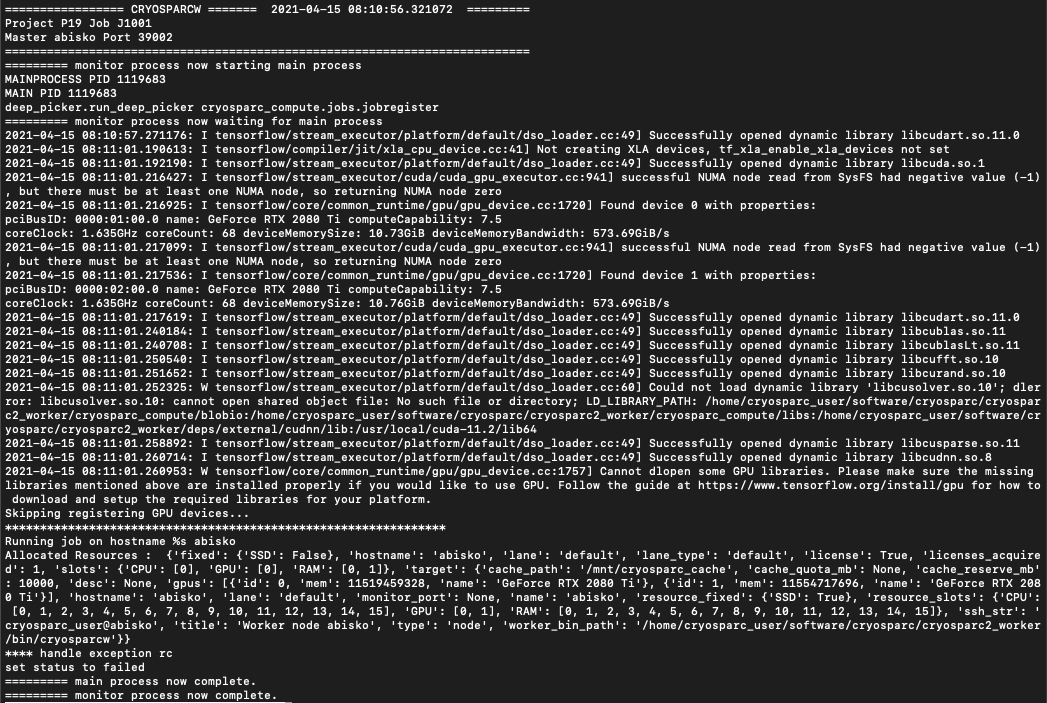
Could not load dynamic library libcusolver.so.10; dlerror: libcusolver.so.10: cannot open shared object file: No such file or directory;
So there seem to be some issue with a cuda dependency, right?
Another thing. In the preprocessing settings for Deep Picker Train, shouldn’t it be “Desired Angstroms per pixel” instead of “Desired pixels per Angstrom”? I mean, doesn’t downsampling lead to a higher Angstrom/pixel ratio? I am a bit new to this…
Hi @emil,
That would be ideal, thank you!
Definitely seems like it. Can you try re-installing the worker dependencies?
On a worker node (e.g. abisko in your case), navigate to cryosparc_worker and run the following:
./bin/cryosparcw forcedeps
Once that’s done, try the job again and let me know how it goes.
@stephan
I re-installed the dependencies, but unfortunately I still get “Could not load dynamic library ‘libcusolver.so.10’”.
Since I have updated to cuda 11.2, why is it looking for the libcusolver.so.10 and not the libcusolver.so.11 dependency?
Hi @emil,
Good point. This is the joblog from a Deep Picker Train job run from our instance:
2021-04-14 16:22:44.981975: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-04-14 16:22:44.982012: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-04-14 16:22:44.982035: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
2021-04-14 16:22:44.982057: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcufft.so.10
2021-04-14 16:22:44.982079: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcurand.so.10
2021-04-14 16:22:44.982099: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusolver.so.10
2021-04-14 16:22:44.982120: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusparse.so.11
2021-04-14 16:22:44.982141: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8
2021-04-14 16:22:44.985679: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0
2021-04-14 16:22:44.986736: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
libcusolver.so.10 doesn’t exist in CUDA 11.2. We’ll investigate further.
Edit: Looks like others have this issue  https://github.com/tensorflow/tensorflow/issues/44777#issuecomment-771285431
https://github.com/tensorflow/tensorflow/issues/44777#issuecomment-771285431
Hi @emil,
I was able to reproduce your error by deleting CUDA Toolkit 10.* folders from my workstation.
I then created a hard link, as suggested in the issue I linked above:
cd /usr/local/cuda-11.2/lib64
sudo ln libcusolver.so.11 libcusolver.so.10
And the job worked. Looks like an issue with Tensorflow 2.4, sorry for the inconvenience!
2 Likes
Thanks a lot, @stephan! Creating a hard link solved the issue.